
My Java Guide(Legacy)
服务端,All in Boom!
—— 2024年10月7日深夜
—————————————
线性表
1 | class SqList { |
反转数组
1 | public void reverseSqList(int[] arr) { |
反转链表
反转一个单链表。
1 | public ListNode reverseLinkList(ListNode head) { |
合并两个数组
合并两个有序数组为一个有序数组。
1 | public void merge(int[] nums1, int m, int[] nums2, int n) { |
合并两个链表
1 | /** |
拆分两个数组
1 | public static void splitArray(int[] inputArray) { |
拆分两个链表
1 | /** |
TopK
1 | // 最小堆法 |
数组和列表之间的转换
1 | //数组转列表 |
栈、队列
用栈实现队列
1 | public class QueueWithTwoStacks { |
用数组实现循环队列
1 | public class CircularQueue { |
有效的括号
判断字符串中的括号是否有效配对。例如[]{()()}}。
1 | public boolean isValid(String s) { |
最小栈
设计一个可以获取最小元素的栈。
1 | class MinStack { |
二叉树
二叉树结构
1 | class TreeNode { |
前序|中序|后序、层次遍历
实现二叉树的前序、中序、后序、层次遍历。
1 | // 前序遍历 (根-左-右) |
1 | // 中序遍历 (左-根-右) |
1 | // 后序遍历 (左-右-根) |
1 | // 层次遍历 |
查找、插入、删除、更新
1 | // 查找 |
1 | // 插入新节点 |
1 | // 删除节点 |
1 | // 更新 |
翻转二叉树
1 | //翻转二叉树 |
判断路径总和
判断二叉树中是否存在一条路径,其路径和等于给定的数值。
1 | public boolean hasPathSum(TreeNode root, int sum) { |
判断镜像二叉树
判断一个二叉树是否是它的镜像。
1 | public boolean isSymmetric(TreeNode root) { |
哈夫曼树
哈夫曼编码原理

哈夫曼树结构
1 | class HuffmanNode<T> extends BinaryNode<T> implements Comparable<HuffmanNode<T>> { |
构建哈夫曼树
1 | // 处理字符串 |
哈夫曼编码、解码
1 | // 编码 |
1 | // 解码 |
计算带权路径长度、压缩率
1 | public static int calculateWPL(HuffmanNode<Character> node, int depth) { |
1 | public static int calculateOriginalSize(String str) { |
搜索算法
广度优先搜索
深度优先搜索
1 | public class 搜索算法_DFS_BFS { |
排序算法
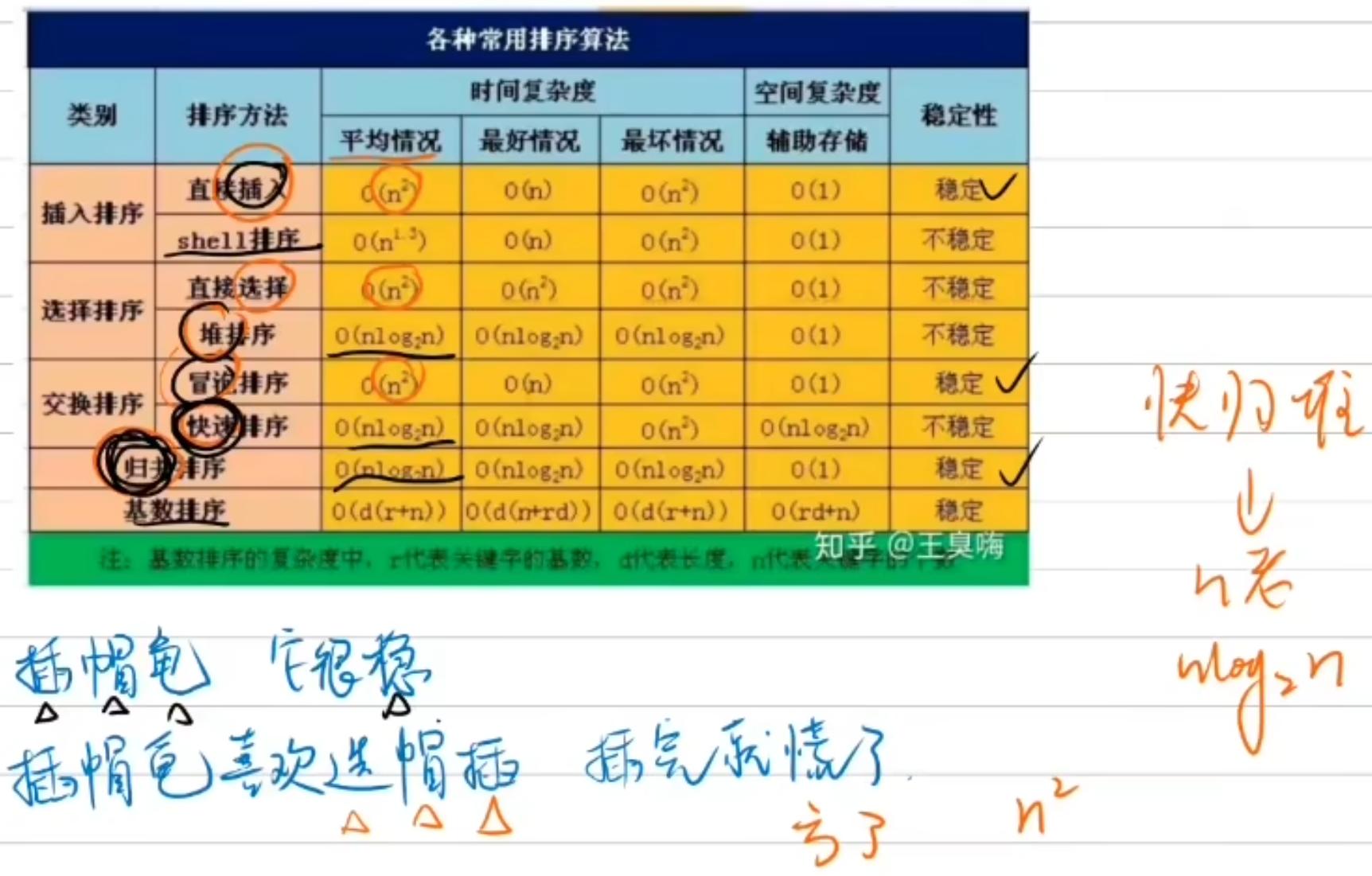
交换算法
1 | /** |
插入类排序
1 | /**********************插入类排序**********************/ |
在插入排序时,使用二分查找找到插入的位置,从而减少比较次数(但仍然需要线性时间插入元素)。
1 | /** |
选择类排序
1 | /**********************选择类排序**********************/ |
在选择最小元素时,记录最小元素的索引,并在每次找到更小元素时更新索引。
1 | /** |
1 | /** |
交换类排序
1 | /**********************交换类排序**********************/ |
1 | /** |
1 | //快速排序:先选择一个基准(哨兵值)然后分成两部分递归,如此往复 |
1 | /** |
归并类排序
1 | /**********************归并类排序**********************/ |
1 | /** |
分布类排序
1 | /**********************分布类排序**********************/ |
1 | // 主函数,执行基数排序 |
二分查找
1 | public static int binSearch(int[] arr, int low, int high, int item) { |
—————————————
数据淘汰算法
LRU 算法(最近最少使用)
设计一个数据结构,实现最近最少使用缓存。
通过哈希表和双向链表实现。哈希表提供 O(1) 的查找时间,双向链表维护访问顺序。
1 | // 直接继承法,继承LinkedHashMap,只需要重写get和put、修改淘汰规则即可 |
LFU 算法(频率最少使用)
设计一个数据结构,实现最不经常使用缓存。
LFU 缓存需要同时记录使用频率和访问时间,通过哈希表和最小堆实现。
1 | class LFUCache { |
多线程并发题
多线程交替打印数字
两个线程交替打印数字,一个线程打印奇数,另一个线程打印偶数,直到100。
使用synchronized实现
1 | class PrintOddEven { |
使用ReentrantLock实现
1 | import java.util.concurrent.locks.Condition; |
使用Semaphore实现
1 | import java.util.concurrent.Semaphore; |
多线程按顺序打印ABC
三个线程按顺序打印ABC,重复10次。
1 | public class 线程交替打印字母_PrintABC { |
模拟死锁
1 | class DeadLockDemo2 { |
模拟消息队列
使用阻塞队列实现生产者消费者问题。
1 | import java.util.concurrent.ArrayBlockingQueue; |
哲学家进餐问题
使用信号量解决哲学家进餐问题。
1 | class Philosopher implements Runnable { |
使用CyclicBarrier实现多线程任务
使用CyclicBarrier实现多个线程分段执行任务,每个线程打印自己的任务完成后,等待其他线程到达,然后继续下一段任务。
1 | import java.util.concurrent.BrokenBarrierException; |
使用CountDownLatch实现任务协调
使用CountDownLatch等待多个线程完成任务后再继续主线程执行。
1 | import java.util.concurrent.CountDownLatch; |
使用Exchanger实现线程间数据交换
使用Exchanger实现两个线程交换数据。
1 | import java.util.concurrent.Exchanger; |
拓展:实现和指定的线程交换数据
1 | class ExchangerRegistry { |
—————————————
数学相关
两数之和
在数组中找到两个数,使它们的和等于给定的数。
1 | public int[] twoSum(int[] nums, int target) { |
两数之和 II
在一个排序列表中找到两个数,使它们的和等于给定的数。
1 | public int[] twoSum(int[] numbers, int target) { |
快乐数
判断一个数是否为快乐数,即反复将每个位的数字平方求和,最终会得到1。
1 | public boolean isHappy(int n) { |
罗马数字转整数
将罗马数字转换为整数。
1 | public int romanToInt(String s) { |
整数反转
给你一个32位的有符号的int类型的数字,将数字上的每一位进行反转。
1 | public int reverseInt(int x) { |
滑动窗口、动归
爬楼梯
1 | public int climbStairs(int n) { |
1 | public int lengthOfLIS(int[] nums) { |
能否组成顺子
1 | class Shunzi{ |
最长公共前缀
找到字符串数组中的最长公共前缀。
1 | // 解法一:startsWith匹配 |
最长递增子串的长度
递增子串:每个相邻的数字之差为1,例如”1,2,3,4,5”
1 | public static int lengthOfCSQ(int[] nums) { |
最长递增子序列的长度
递增子序列:不考虑前后数字是否相邻,只要是递增的就行,例如”1,…,4,9,…,10,…,17”
1 | public int lengthOfNCSQ(int[] nums) { |
最大子数组和
1 | class MaxSubArray{ |
最大连续子数组和
1 | class MaxContinuousSubArray { |
旋转数组
给定一个数组,将数组中的元素向右移动 k 个位置。
1 | public void rotate(int[] nums, int k) { |
搜索旋转排序数组
在旋转排序数组中查找一个特定的元素。
1 | public int search(int[] nums, int target) { |
是否是回文数
判断一个整数是否是回文数,即正读和反读都一样。
1 | public boolean isPalindrome(int x) { |
回文串判断
1 | private static String getString(){ |
[最长回文子串](5. 最长回文子串 - 力扣(LeetCode))
1 | public static String longestPalindrome(String s) { |
最长回文子串的长度
1 | public static int longestPalindromeLength(String s) { |
最长回文子序列的长度
1 | public static int longestPalindromeSubseqLength(String s) { |
无重复字符的最长子串
示例 1:
1 | 输入: s = "abcabcbb" |
示例 2:
1 | 输入: s = "bbbbb" |
示例 3:
1 | 输入: s = "pwwkew" |
1 | public int lengthOfLongestSubstring(String s) { |
寻找两个正序数组的中位数(暴力版)
1 | public double findMedianSortedArrays(int[] nums1, int[] nums2) { |
#————————————–
#操作系统
用户态和内核态
指处理器运行在不同权限级别的两种模式。这两种模式的设计目的是为了提高系统的安全性,并且防止用户程序错误地影响到整个系统的稳定性和数据的安全性。
用户态(User Mode)
用户态是指普通应用程序运行时所在的模式。在这种模式下,应用程序只能访问受限制的系统资源和服务。用户态程序不能直接访问硬件或执行某些特权指令,这样可以防止由于程序错误或恶意行为而导致系统崩溃或数据损坏。
在用户态下运行的应用程序包括但不限于:
- 文档编辑器
- 游戏
- 浏览器
- 办公软件
- 大部分用户级服务
内核态(Kernel Mode)
内核态是指操作系统内核运行时所在的模式。在内核态下,程序拥有完全的系统访问权限,可以执行任何指令,直接访问硬件资源。这种模式下的代码通常是经过严格审查的,因为任何错误都可能导致系统不稳定甚至崩溃。
在内核态下运行的组件包括:
- 文件系统驱动
- 设备驱动
- 网络协议栈
- 进程调度器
- 内存管理模块
用户态和内核态之间的转换
用户态下的应用程序需要调用操作系统提供的系统调用(System Call)来请求内核提供的服务,例如读写文件、分配内存、创建进程等。当应用程序发起一个系统调用时,CPU会从用户态切换到内核态,操作系统内核处理完请求后再从内核态切换回用户态。这种转换涉及到:
- 保护上下文:保存用户态的寄存器状态和程序计数器。
- 执行系统调用处理程序:操作系统内核中的代码负责处理系统调用。
- 恢复上下文:完成系统调用后,恢复用户态的寄存器状态和程序计数器。
进程的调度算法
| 调度算法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 先来先服务(First-Come, First-Served, FCFS) | 按照进程到达的先后顺序进行调度 | 实现简单,易于理解 | 可能导致长进程饿死短进程(长作业优先),响应时间较长 |
| 短作业优先(Shortest Job First, SJF) | 总是选择预计执行时间最短的进程来执行 | 可以最小化平均等待时间 | 需要知道进程的确切执行时间,实现复杂,且可能不公平对待长进程 |
| 最短剩余时间优先(Shortest Remaining Time First, SRTF) | 总是选择剩余执行时间最短的进程来执行 | 可以动态调整,更好地适应实际情况 | 需要实时更新剩余时间,实现较为复杂 |
| 时间片轮转(Round Robin, RR) | 给每个就绪队列中的进程分配一个固定的时间片(时间量子),并在时间片结束后强制切换到下一个进程 | 简单公平,适用于交互式系统 | 时间片的选择至关重要,否则可能会影响响应时间和吞吐量 |
| 优先级调度(Priority Scheduling) | 根据进程的优先级来调度,优先级高的进程优先执行 | 可以根据进程的重要性灵活调度 | 可能造成饥饿(starvation),即低优先级的进程永远得不到执行的机会 |
……还有很多,不列举了
进程间的通信方式
进程间通信(IPC)主要包括以下几种方式:
- 管道(Pipe)是最古老的进程间通信机制之一,所有的 UNIX 系统都支持这种机制。管道实质上是内核维护的一块内存缓冲区。Linux 系统中通过
pipe()函数创建管道,这会生成两个文件描述符,分别对应管道的读端和写端。无名管道仅限于具有亲缘关系的进程间通信。 - 命名管道(FIFO) 命名管道(Named Pipe 或 FIFO 文件)克服了无名管道只能用于亲缘进程通信的限制。命名管道提供了一个路径名与之关联,作为文件系统中的一个 FIFO 文件存在。任何能够访问该路径的进程,即便与创建该 FIFO 的进程无关,也可以通过该 FIFO 进行通信。
- 信号 信号是进程间通信的另一种古老方式,作为一种异步通知机制,它可以在一个进程中产生中断,使进程能够响应某些事件。信号可以看作是软件层次上的中断机制,用于处理突发事件。
- 消息队列 消息队列是一个链表结构,其中包含具有特定格式和优先级的消息。具有写权限的进程可以按规则向消息队列中添加消息,而具有读权限的进程可以从队列中读取消息。消息队列是随内核持续存在的。
- 共享内存 共享内存允许多个进程共享同一块物理内存区域。这种机制允许进程直接在共享内存中进行数据交换,不需要内核的干预,因此速度较快。
- 内存映射 内存映射技术将磁盘文件的数据映射到内存,用户可以通过修改内存中的内容来间接修改磁盘文件。
- 信号量 信号用于解决进程或线程间的同步问题。对信号量的操作包括 P 操作(减 1)和 V 操作(加 1),用于控制进程或线程的互斥访问。
- Socket Socket 是网络中不同主机上应用程序之间进行双向通信的端点的抽象。它为应用层提供了使用网络协议进行数据交换的机制,主要用于网络中不同主机上的进程间通信。
什么是软中断、什么是硬中断?
| 中断类型 | 描述 | 特点 | 例子 |
|---|---|---|---|
| 硬中断 | 由硬件设备引发的中断信号 | 外部来源:由外部硬件设备引发。 硬件触发:通常由设备通过 IRQ 线向 CPU 发送中断信号。 实时性:通常要求立即响应。 硬件驱动程序处理:中断处理程序通常由硬件驱动程序编写。 |
键盘中断:按下键盘按键。 网络中断:网络适配器接收到数据包。 定时器中断:定时器硬件定时发送中断信号。 |
| 软中断 | 由软件指令或内核代码触发的中断信号 | 内部来源:由软件指令或内核代码触发。 软件触发:通过特定的指令或函数调用触发。 灵活性:可以根据需要随时触发。 内核处理:通常由内核中的中断处理程序处理。 |
系统调用:应用程序调用系统服务。 时间片到期:时间片结束时触发。 异常处理:如页错误、除零错误等。 |
什么是分段、什么是分页?
| 特点 | 分段(Segmentation) | 分页(Paging) |
|---|---|---|
| 逻辑划分 | 将逻辑地址空间划分为多个逻辑段,每个段代表程序的一部分。 | 将逻辑地址空间划分为固定大小的页面。 |
| 大小 | 段的大小可以是动态变化的,每个段可以有不同的大小。 | 页面的大小是固定的,通常是 4KB 或更大。 |
| 映射 | 段可以映射到物理内存中的连续或非连续区域。 | 页面映射到物理内存中的连续或非连续区域。 |
| 保护 | 每个段可以单独保护和管理,有利于实现访问控制和保护。 | 页面级别的保护,但通常不如分段灵活。 |
| 缺点 | 实现复杂,可能导致内存碎片。 | 可能导致内存碎片,但通常较少。 |
| 应用场景 | 适合需要逻辑分段的应用程序,如操作系统内核、数据库管理系统等。 | 适合大多数应用程序,特别是需要虚拟内存支持的应用程序。 |
| 代表性系统 | Unix、早期的 Windows 操作系统。 | Linux、现代 Windows 操作系统。 |
什么是 Channel?
在计算机科学和软件开发中,“Channel”(通道)是一个广泛使用的术语,它在不同的上下文中可以有不同的含义。这里我们将讨论几种常见的“Channel”的定义及其用途:
1. 操作系统中的 Channel
在操作系统中,“Channel”通常指的是用于在进程之间进行通信的一种机制。它可以看作是一种高级的 IPC(Inter-Process Communication)机制,用于在进程之间传递数据。
特点:
- 通信媒介:Channel 作为进程间通信的媒介,可以实现数据的发送和接收。
- 同步:通常 Channel 机制会包含同步机制,确保数据的正确传递。
例子:
- 管道(Pipe):在 Unix/Linux 系统中,管道是一种典型的 Channel,用于连接两个进程,使一个进程的输出成为另一个进程的输入。
- 命名管道(Named Pipe/FIFO):与管道类似,但可以在不同的进程或用户之间共享,通过文件名来标识。
2. 并发编程中的 Channel
在并发编程中,Channel 是一种用于通信和同步的基本原语,特别是在函数式编程语言和并发模型(如 Go 语言的 goroutines)中。
特点:
- 数据传递:Channel 用于在并发执行的线程或协程之间传递数据。
- 同步机制:Channel 提供了一种同步方式,确保数据的有序传递和一致性。
- 阻塞行为:Channel 可以是阻塞的或非阻塞的,具体取决于是否有数据可以接收或发送。
例子:
- Go 语言的 Channel:Go 语言中的 Channel 是用于 goroutine 之间通信的基本机制,可以传递任意类型的数据。
- Haskell 的 TChan:Haskell 中的
TChan是一种用于线程间通信的 Channel。
3. 网络通信中的 Channel
在网络通信中,“Channel”通常指的是一种逻辑上的连接或通信路径,用于传输数据。
特点:
- 逻辑连接:在网络层面上,Channel 可以指一条逻辑上的连接,如 TCP 连接。
- 数据传输:Channel 用于在网络节点之间传输数据包。
例子:
- TCP 连接:TCP 连接可以视为一种 Channel,用于在客户端和服务器之间建立稳定的双向通信路径。
- WebSocket:WebSocket 是一种全双工的通信协议,可以在客户端和服务器之间建立持久的 Channel。
4. 应用程序中的 Channel
在某些应用程序中,Channel 也可以指一种用于组织和管理数据流的方式。
特点:
- 数据组织:Channel 可以用于组织不同类型的数据流。
- 逻辑隔离:不同的 Channel 可以用于隔离不同类型的数据传输。
例子:
- 多媒体播放器中的音频/视频 Channel:在多媒体播放器中,音频和视频数据流可以被视为不同的 Channel。
- 消息队列中的 Topic:在消息队列系统(如 Apache Kafka)中,Topic 可以被视为一种 Channel,用于组织不同类型的消息。
- Buffer:用于缓存数据,提高 I/O 效率。
- Selector:用于监控多个文件描述符的状态,实现多路复用。
- Reactor:结合 Selector 和事件驱动的设计模式,用于处理并发 I/O 操作。
- Select、Poll、Epoll:三种不同的文件描述符监控机制,分别适用于不同场景。
什么是 Buffer?
Buffer通常指用于临时存储数据的内存区域。在计算机科学中,Buffer 主要用于缓存数据,以便进行批量处理或提高数据传输效率。
作用:
- 数据缓存:临时存储数据,以减少 I/O 操作次数。
- 流量控制:在数据传输过程中,用于平滑数据流,防止数据丢失。
- 同步:在多线程或多进程环境中,Buffer 用于同步数据。
例子:
- 网络编程中的 Buffer:在网络编程中,接收的数据通常先存储在一个 Buffer 中,然后再进行处理。
- 文件系统中的 Buffer:在文件系统中,读取或写入的数据通常先存储在 Buffer 中,以减少磁盘 I/O 操作。
什么是 Selector?
Selector是一种用于监控多个文件描述符(File Descriptor)状态的技术,通常用于网络编程中的多路复用(Multiplexing)。
作用:
- 多路复用:同时监控多个文件描述符的状态,如读写就绪状态。
- 非阻塞:当没有数据可读或可写时,不会阻塞当前线程。
- 效率:相比于传统的阻塞 I/O,使用 Selector 可以大大提高 I/O 效率。
例子:
- Java NIO 中的 Selector:在 Java 的 NIO(New IO)框架中,
Selector用于监控多个SocketChannel的状态。 - POSIX 系统中的 Select 和 Poll:在 POSIX 系统中,
select()和poll()是常用的 Selector 实现。
什么是 Reactor?
Reactor是一种设计模式,用于处理并发 I/O 操作。它结合了 Selector 和事件驱动的设计思想,通常用于构建高性能的网络服务器。
作用:
- 事件驱动:监听并处理多个 I/O 事件。
- 非阻塞:当没有 I/O 事件发生时,不会阻塞当前线程。
- 可扩展性:通过事件循环处理 I/O 事件,易于扩展和维护。
例子:
- Reactor 模式:在高性能服务器中,Reactor 模式常用于处理大量的并发连接。
- 事件驱动框架:如 libevent、libuv 等,提供了基于 Reactor 模式的设计框架。
Select、Poll、Epoll 之间有什么区别?
Select:select() 是一个用于监控多个文件描述符的系统调用。
- 支持的文件描述符数量有限(通常为 FD_SETSIZE)。
- 可以同时监控读、写和异常状态。
- 在 Linux 中,
select()的效率较低,因为需要遍历所有的文件描述符。
适用场景:适合文件描述符较少的场景。
Poll:poll() 是 select() 的改进版本,同样用于监控多个文件描述符的状态。
- 不受文件描述符数量限制。
- 每个文件描述符的状态信息保存在
pollfd结构中。 - 效率高于
select(),因为不需要遍历所有文件描述符。
适用场景:适合文件描述符较多的场景。
Epoll:epoll() 是 Linux 内核提供的一个高效的文件描述符监控机制。
- 使用事件驱动的方式,只有状态改变的文件描述符才会被激活。
- 支持动态添加和删除监控对象。
- 效率最高,因为只关心状态发生变化的文件描述符。
适用场景:适合高性能网络服务器,尤其是需要处理大量并发连接的场景。
—————————————
计算机网络
模型
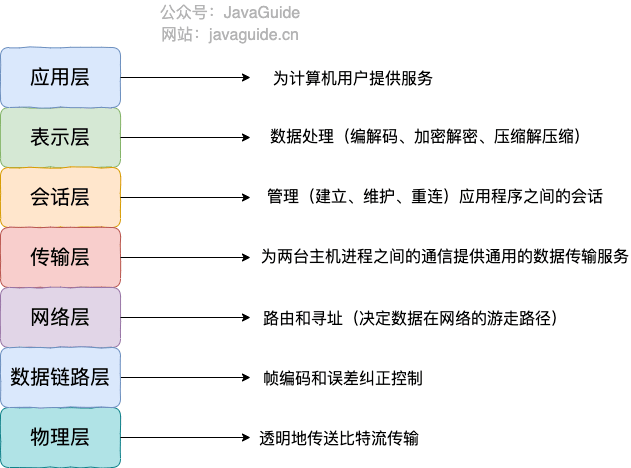
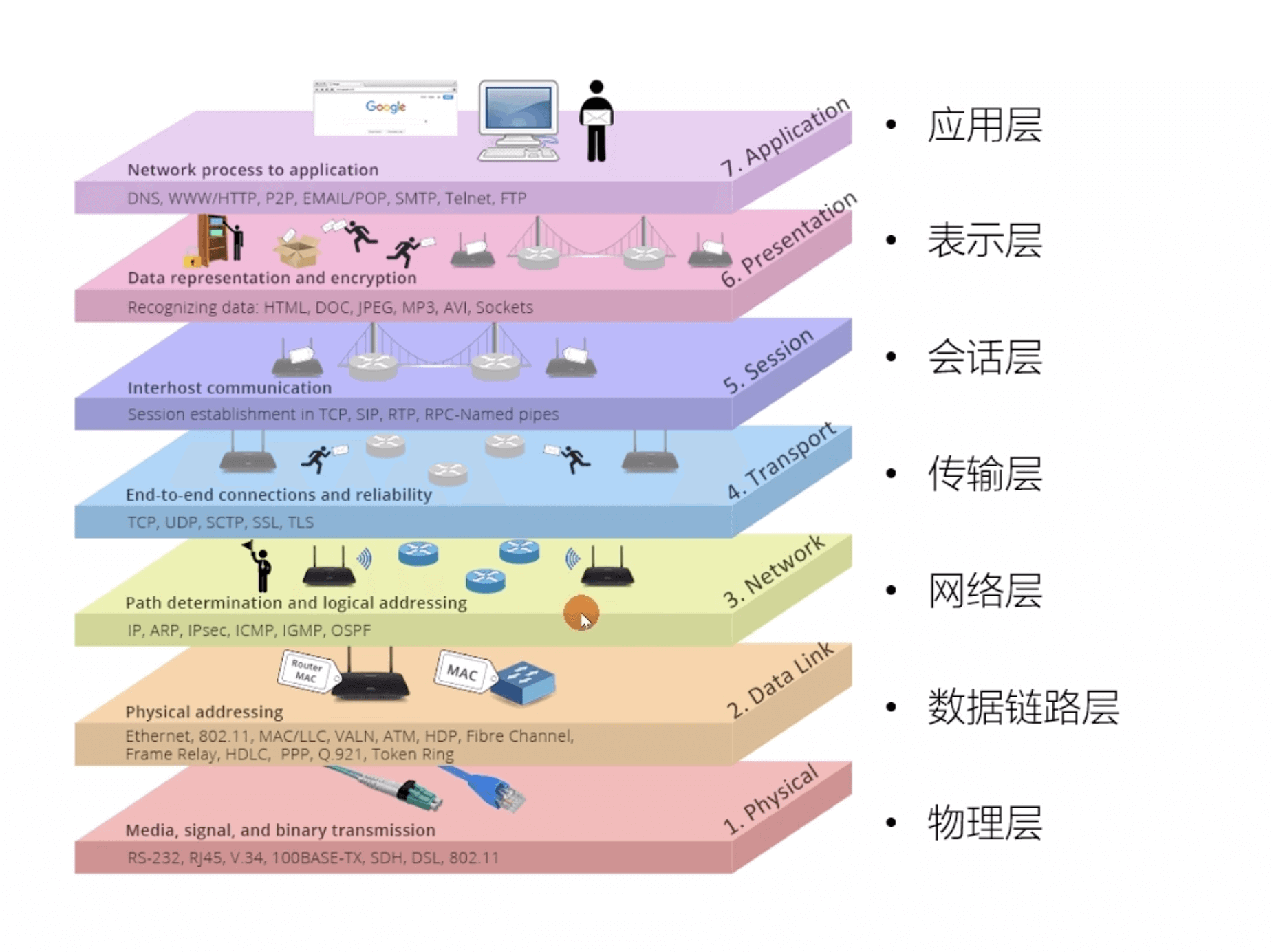
OSI 七层模型
OSI 七层模型 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
TCP/IP 四层模型
TCP/IP 四层模型 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
- 应用层
- 传输层
- 网络层
- 网络接口层
需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:

协议
常见网络协议汇总
1. 应用层有哪些常见的协议?
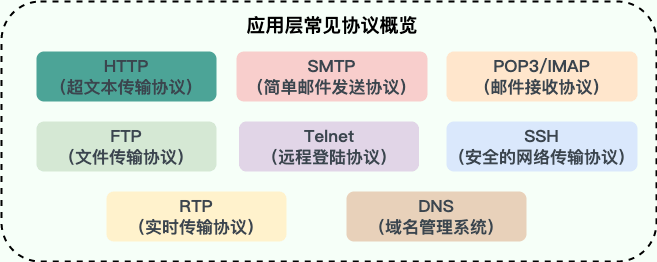
- HTTP(Hypertext Transfer Protocol,超文本传输协议):基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
- SMTP(Simple Mail Transfer Protocol,简单邮件发送协议):基于 TCP 协议,是一种用于发送电子邮件的协议。注意 :SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
- POP3/IMAP(邮件接收协议):基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
- FTP(File Transfer Protocol,文件传输协议) : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
- Telnet(远程登陆协议):基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
- SSH(Secure Shell Protocol,安全的网络传输协议):基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- RTP(Real-time Transport Protocol,实时传输协议):通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
- DNS(Domain Name System,域名管理系统): 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
2. 传输层有哪些常见的协议?

- TCP(Transmission Control Protocol,传输控制协议 ):提供 面向连接 的,可靠 的数据传输服务。
- UDP(User Datagram Protocol,用户数据协议):提供 无连接 的,尽最大努力 的数据传输服务(不保证数据传输的可靠性),简单高效。
3. 网络层有哪些常见的协议?
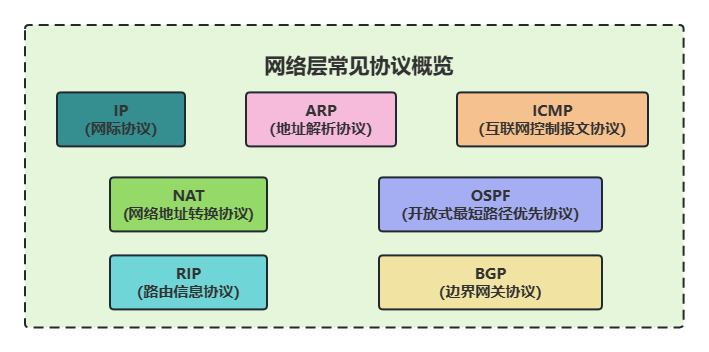
- IP(Internet Protocol,网际协议):TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
- ARP(Address Resolution Protocol,地址解析协议):ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
- ICMP(Internet Control Message Protocol,互联网控制报文协议):一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
- NAT(Network Address Translation,网络地址转换协议):NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
- OSPF(Open Shortest Path First,开放式最短路径优先) ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
- RIP(Routing Information Protocol,路由信息协议):一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
- BGP(Border Gateway Protocol,边界网关协议):一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
TCP 与 UDP 的区别
- 是否面向连接:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
- 是否是可靠传输:远地主机在收到 UDP 报文后,不需要给出任何确认,并且不保证数据不丢失,不保证是否顺序到达。TCP 提供可靠的传输服务,TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。
- 是否有状态:这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(这很渣男!)。
- 传输效率:由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
- 传输形式:TCP 是面向字节流的,UDP 是面向报文的。
- 首部开销:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
- 是否提供广播或多播服务:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
- ……
我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
| TCP | UDP | |
|---|---|---|
| 是否面向连接 | 是 | 否 |
| 是否可靠 | 是 | 否 |
| 是否有状态 | 是 | 否 |
| 传输效率 | 较慢 | 较快 |
| 传输形式 | 字节流 | 数据报文段 |
| 首部开销 | 20 ~ 60 bytes | 8 bytes |
| 是否提供广播或多播服务 | 否 | 是 |
TCP 和 UDP 的选择
- UDP 一般用于即时通信,比如:语音、 视频、直播等等。这些场景对传输数据的准确性要求不是特别高,比如你看视频即使少个一两帧,实际给人的感觉区别也不大。
- TCP 用于对传输准确性要求特别高的场景,比如文件传输、发送和接收邮件、远程登录等等。
HTTP 和 HTTPS 的区别

- 端口号:HTTP 默认是 80,HTTPS 默认是 443。
- URL 前缀:HTTP 的 URL 前缀是
http://,HTTPS 的 URL 前缀是https://。 - 安全性和资源消耗:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
- SEO(搜索引擎优化):搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
URI 和 URL 的区别
- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
什么是 WebSocket?
WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
WebSocket 和 HTTP 的区别
WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
下面是二者的主要区别:
- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
TCP/IP 协议
常见的 HTTP 状态码
信息响应类(1xx):请求已被接受,需要客户端继续操作。
重定向类(3xx):需要客户端采取进一步的动作来完成请求。
成功类(2xx):请求已经被成功处理。
- 200 OK:请求已成功,返回请求的数据。
- 204 无内容:服务器成功处理了请求,但没有返回任何内容。
客户端错误类(4xx):请求包含语法错误或无法完成请求。
- 400 错误请求:服务器不能理解请求报文。
- 401 未授权:请求要求用户的身份认证。
- 403 禁止:服务器理解请求客户端的请求,但是拒绝执行此请求。
服务器错误类(5xx):服务器发生错误,无法完成请求。
- 500 内部服务器错误:服务器遇到未知错误。
- 501 未实现:服务器不支持请求的功能。
- 502 坏网关:作为网关或代理工作的服务器从上游服务器收到了无效响应。
- 503 服务不可用:服务器暂时过载或维护。
- 504 网关超时:作为网关或代理工作的服务器没有及时从上游服务器收到请求。
- 505 HTTP 版本不受支持:服务器不支持请求中所用的 HTTP 协议版本。
三次握手的过程
- SYN(同步序列编号,Synchronize):
- 客户端发送一个 SYN 包给服务器端,表示请求建立连接。这个包中包含了一个初始化的序号(Sequence Number),用于后续的数据传输。
- SYN-ACK(同步-确认,Synchronize-Acknowledge):
- 服务器端接收到 SYN 包之后,会发送一个 SYN-ACK 包作为应答。这个包中包含了一个自己的初始化序号,并且还包含了一个确认序号(Acknowledgment Number),这个确认序号是对客户端发出的 SYN 包的序号加一的确认。
- ACK(确认,Acknowledge):
- 客户端接收到服务器的 SYN-ACK 包后,会发送一个 ACK 包作为确认,这个包仅仅包含确认序号,确认序号是对服务器发出的 SYN-ACK 包的序号加一的确认。这样就完成了三次握手的过程,连接建立完成。
1 | Client Server |
四次挥手的过程
- FIN(结束标志,Finish):
- 假设客户端想要关闭连接,它会发送一个 FIN 段到服务器,这个 FIN 段表明客户端已经没有更多的数据要发送了。该 FIN 段包含客户端的序列号 Seq = X。
- ACK(确认标志,Acknowledge):
- 服务器接收到客户端的 FIN 段后,会发送一个 ACK 段作为响应。这个 ACK 段确认了它已经收到了客户端的 FIN 段,并且确认了客户端的序列号 Seq = X + 1。此时,服务器可能仍然有未发送完的数据,所以这个 ACK 段可能还包含了一些待发送的数据。该 ACK 段包含服务器的序列号 Seq = Y 和确认号 Ack = X + 1。
- FIN(结束标志,Finish):
- 当服务器完成了所有数据的发送后,它也会发送一个 FIN 段到客户端,表明服务器也没有更多的数据要发送了。这个 FIN 段包含服务器的序列号 Seq = Z。
- ACK(确认标志,Acknowledge):
- 客户端接收到服务器的 FIN 段后,同样发送一个 ACK 段作为确认,表明它已经收到了服务器的 FIN 段,并且确认了服务器的序列号 Seq = Z + 1。此时,连接就可以正式关闭了。
1 | Client Server |
断开连接
在标准的TCP/IP协议栈中,终止一个TCP连接主要是通过四次挥手来完成的。然而,在某些特殊情况下,还有其他的机制可以导致TCP连接的中断:
- RST(复位)包:发送一个带有RST标志的TCP段可以立即终止一个TCP连接。这种方式通常用于异常情况,如主机崩溃后重启或检测到恶意流量时。使用RST包断开会丢失未确认的数据,并且不会等待已发送的数据被接收。
- 超时:如果一段长时间内没有任何数据传输活动,TCP连接可能会因为超时而自动关闭。这种机制是为了防止死链的存在。
- 操作系统强制关闭:在某些情况下,操作系统可以直接关闭TCP连接,例如当系统检测到连接的一端已经不可达时。
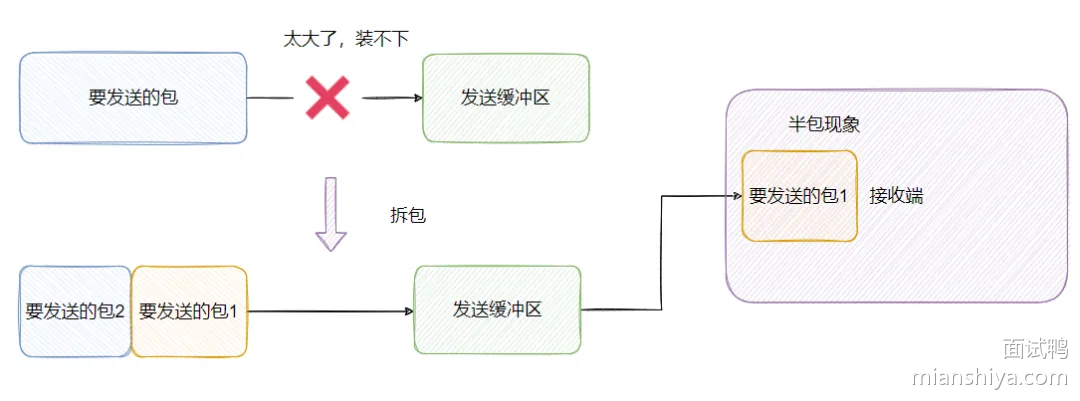
粘包、拆包
粘包(Packet Clumping):指的是多个数据包在TCP层被合并成一个大的数据包进行发送,导致接收方无法区分这些数据包的边界。这通常发生在TCP的拥塞控制算法工作时,或者当发送方连续发送小的数据包而接收方在一个接收缓冲区中接收到的数据量超过了单个数据包的大小时。
发生原因:
- 发送方连续发送多个小的数据段,但接收方一次只收到了一个数据段。
- 这些数据段在TCP层被合并成了一个较大的数据段进行传输。
解决方案:
- 在发送数据时添加定长的包头。
- 使用特殊的分隔符来标识每个消息的边界。
- 使用固定长度的消息格式。
拆包(Packet Fragmentation):指的是一个较大的数据包在传输过程中被分割成几个更小的数据包进行发送,导致接收方接收到多个数据段,这些数据段原本属于同一个消息。
发生原因:
- 当一个数据包的大小超过了一定限制(如MTU,最大传输单元),路由器或网络设备可能会将其分割成几个较小的数据包进行传输。
- 接收方会收到这些被分割的数据包,并需要重组它们以恢复原始的消息。
解决方案:
- 通常情况下,TCP协议本身会处理这些被分割的数据包的重组,不需要应用层做额外的工作。
- 如果频繁出现拆包问题,可以考虑调整发送的数据包大小,使其不超过网络的最大传输单元(MTU)。
滑动窗口
主要作用:
- 流量控制:滑动窗口使得接收方可以控制发送方发送数据的速度,从而避免因发送速度过快而导致接收方无法及时处理数据。
- 提高带宽利用率:通过动态调整窗口大小,可以根据网络状况和接收方的能力最大化带宽的使用效率。
- 减少数据重传:通过有效的流量控制,减少因接收方缓冲区满而造成的丢包,从而减少不必要的数据重传。
- 改善延迟和吞吐量:滑动窗口机制有助于平衡延迟和吞吐量之间的关系,使得在网络条件变化时仍能保持较好的性能。
工作原理:
滑动窗口的核心思想是维护一个滑动的窗口范围,发送方和接收方通过TCP报文中的序号和确认号来协商这个窗口的大小和位置。
- 窗口大小:TCP头部中的“窗口大小”字段指明了接收方希望接收的数据量,即接收方缓冲区还能接受多少字节的数据。
- 序号和确认号:TCP报文中的序号用来标识数据的第一个字节的编号,而确认号则是指接收方期望接收的下一个字节的序号。
- 发送方的行为:发送方根据接收方提供的窗口大小发送数据,并且不能超出这个窗口的范围。一旦发送的数据达到了窗口的上限,发送方就需要等待接收方的确认或窗口更新后再继续发送。
- 接收方的行为:接收方接收到数据后,会根据接收到的数据量更新窗口大小,并通过ACK(确认)报文告诉发送方最新的窗口大小。
拥塞控制的步骤
TCP拥塞控制是为了防止过多的数据注入到网络中,从而引起网络拥塞的一种机制。TCP拥塞控制主要包括以下几个步骤或阶段:
1)慢启动(Slow Start)
慢启动阶段的目标是迅速增大拥塞窗口(Congestion Window, cwnd),同时避免过多地增加网络负载。在这个阶段,发送方会逐步增加发送的分组数量,直到达到某个阈值(ssthresh,slow start threshold)。
- 初始状态:当一个新的TCP连接建立时,或者网络中发生严重拥塞后重新开始传输时,cwnd通常被初始化为一个MSS(最大段大小)。
- 指数增长:每经过一个往返时间(Round Trip Time, RTT),cwnd就会翻倍。也就是说,发送方每次接收到一个ACK都会增加一个MSS的发送量。
2)拥塞避免(Congestion Avoidance)
当cwnd达到ssthresh时,进入拥塞避免阶段。这个阶段的目的是更加平缓地增加cwnd,以避免网络拥塞。
- 线性增长:每经过一个RTT,cwnd增加一个MSS的大小。也就是说,发送方每次接收到一个ACK时,并不会像慢启动那样翻倍增加,而是按部就班地增加。
- 目标:逐步增大cwnd,同时监控网络状况,避免拥塞。
3)快重传(Fast Retransmit)
快重传是一种加速重传丢失分组的机制。它允许发送方在没有等到重传计时器到期的情况下就重传丢失的数据。
- 触发条件:当发送方收到三个重复的ACK(意味着接收方已经接收到后面的分组,但中间的一个或几个分组丢失了),它就会立即重传丢失的分组,而不是等待计时器超时。
- 结果:这可以更快地恢复丢失的数据,减少传输延迟。
4)快恢复(Fast Recovery)
快恢复是在快重传之后的一个阶段,其目的是快速恢复到正常传输状态。
- 降低阈值:当快重传触发时,ssthresh会被减半(通常是设置为当前cwnd的一半),然后cwnd设置为ssthresh。
- 试探性增长:随后,发送方试探性地增大cwnd。每收到一个丢失分组的ACK,cwnd增加一个MSS。如果接收到足够多的ACK,则认为网络状况良好,可以回到拥塞避免阶段。
Token、Session、Cookie
都用于维护客户端和服务器之间用户认证和会话管理,其区别如下:
Cookie
| 优点 | 缺点 |
|---|---|
| 简单易实现:存储在客户端(静态文件、数据库查询结果) | 安全风险:有被串改风险 |
| 本地缓存:读取速度快,不占用服务器存储 | 容量限制:4KB |
| 可用限制:用户可能禁用 |
Session
| 优点 | 缺点 |
|---|---|
| 安全性高:存储在服务器端,不容易被恶意篡改和伪造 | 占用服务器资源 |
| 容量大:可以保存对象、大量的数据 | 扩展性差(分布式集群) |
| 依然需要依赖cookie跨域限制 |
Session怎么提高效率?
Session持久化:将session信息存储在持久化存储中,如数据库、文件系统或NoSQL存储中,这样可以避免将所有session信息存储在内存中,从而减少内存的使用量。
Session复制:将session信息从一台服务器复制到另一台服务器上,这样可以实现负载均衡,并将会话信息在多个服务器之间共享。
Session失效策略:设置合理的session失效策略,例如根据用户活动时间、最大不活动时间等来决定session的失效时间,可以减少无用的session信息。
集群:使用集群环境来分散请求和负载,这样可以使应用程序在多个服务器上运行,从而提高应用程序的性能和可扩展性。
总之,为了提高会话管理的效率,需要使用合理的持久化和集群技术,并设置合理的会话失效策略,以避免会话信息的无限增长。
Token
| 优点 | 缺点 |
|---|---|
| 无状态性:服务器无需存储,提升可扩展性和性能 | 存储安全:客户端丢失或泄露Token可能导致安全问题 |
| 安全性:通过签名保证数据的完整性和来源的可靠性 | 传输负载:Token较多信息,会增加HTTP请求的大小 |
| 自包含性:Token自身包含用户信息和过期时间等,减少对服务器的查询 |
JWT Token
JWT 的组成
JWT 由三部分组成,每一部分由点号(.)分隔:
- Header(头部)
- Payload(载荷)
- Signature(签名)
Header(头部):头部包含关于 JWT 的元数据,通常是一个 JSON 对象,编码为 Base64URL 字符串。头部包含的信息可能包括使用的签名算法(如 HMAC 使用 SHA-256 或 RSA 使用 SHA-256)以及令牌类型(通常是 “JWT”)。示例:
1 | { |
Payload(载荷):载荷是存储 JWT 数据的地方。这也是一个 JSON 对象,编码为 Base64URL 字符串。载荷包含了一系列声明(Claims),声明可以是标准的也可以是自定义的。一些常用的声明包括 iss(发行者)、exp(过期时间)、sub(主题)等。例如:
1 | { |
Signature(签名):签名部分是用来验证 JWT 的发送方确实是谁他们声称是的人,并且确保载荷没有被篡改。为了创建签名,需要使用 Header 中指定的算法(如 HMAC 使用 SHA-256)对 Header 和 Payload 进行加密,并加上一个密钥(Secret)。密钥通常是只有发行者和接收者知道的秘密。接收方通过使用相同的密钥和算法解密签名,来验证令牌的真实性。示例签名:
1 | eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c |
JWT 的优点
- 无状态:JWT 是自包含的,因此不需要在服务器上保存会话状态,这使得 JWT 成为构建无状态、可扩展的应用程序的理想选择。
- 易于跨域使用:由于 JWT 可以通过 HTTP header 或者 POST 参数携带,所以非常适合跨域资源共享(CORS)。
- 轻量级:JWT 是紧凑的,可以减少网络传输的开销。
JWT 的局限性
- 过期管理:JWT 一旦签发,就不能撤销。如果令牌被盗或滥用,唯一的办法是让它过期或者在服务器端维护一个黑名单列表。
- 安全性依赖于密钥管理:JWT 的安全性依赖于密钥的安全性。如果密钥泄露,任何人都可以伪造 JWT。
JWT 的使用场景
JWT 通常用于身份验证和授权。在用户登录成功后,服务器会生成一个 JWT 并返回给客户端。客户端在后续的请求中将 JWT 放入 HTTP header(通常是 Authorization 头),这样服务器就可以验证用户的权限。
总的来说,JWT 是一种强大的工具,可以帮助开发者构建安全、高效的应用程序,特别是在微服务架构和分布式系统中。然而,使用 JWT 也需要谨慎处理安全性和过期管理等问题。
从输入 URL 到页面展示到底发生了什么?
总体来说分为以下几个步骤:
- 用户输入网址:在浏览器中输入指定网页的 URL。
- DNS 解析:浏览器通过 DNS 协议,获取域名对应的 IP 地址。
- 建立 TCP 连接:浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
- 建立 SSL/TLS 加密连接:如果网站使用 HTTPS 协议,那么双方要交换密钥,建立会话密钥,使用密钥进行加密通信。
- 发送 HTTP 请求:浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
- 服务器处理请求并响应:服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
- 浏览器解析响应:浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
- 中断连接:浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
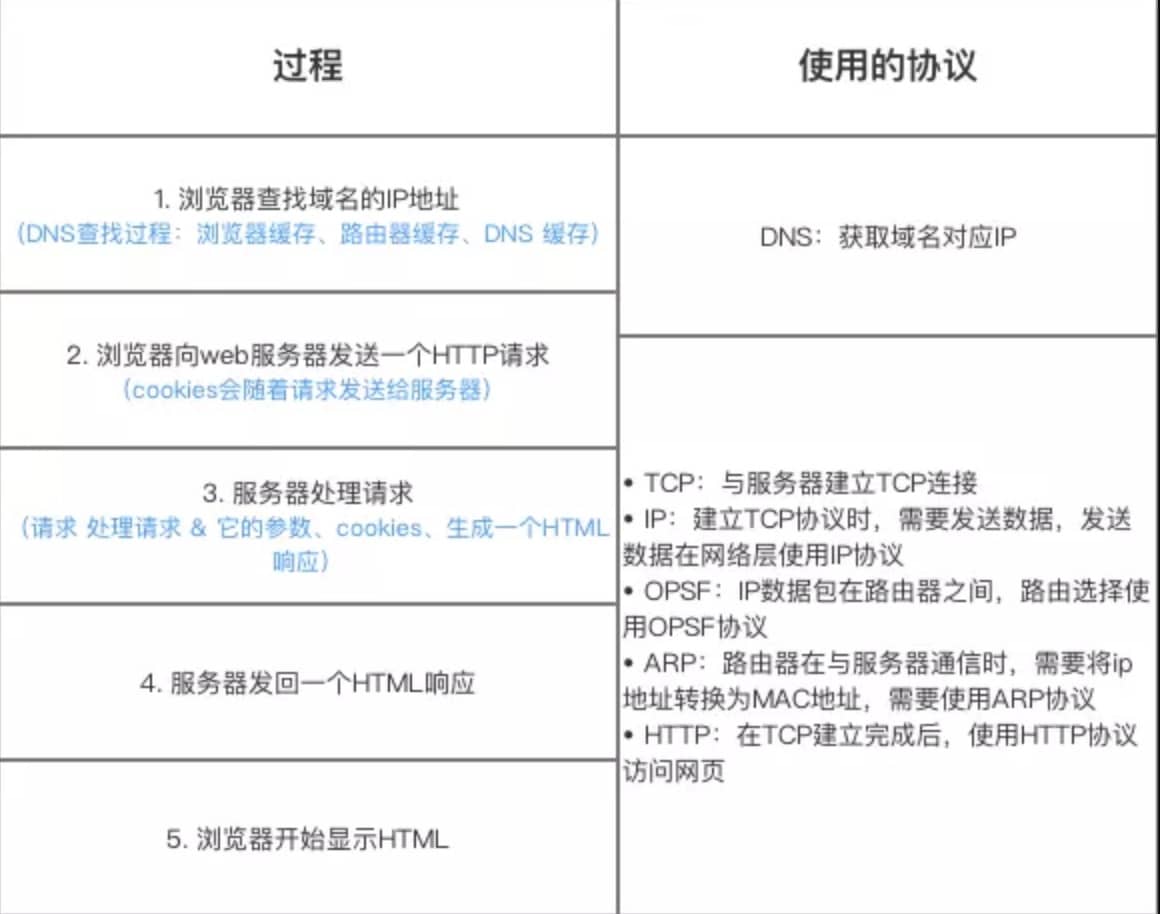
HTTP 协议中 GET 和 POST 的区别
- GET:请求参数在 URL 中,用于获取数据。
- POST:请求参数在请求体中,用于修改数据。
—————————————
设计模式
为什么要用设计模式?
设计模式是一套被预先定义好的解决方案,用于解决软件设计中常见问题,以提高代码的可重用性、可读性和可维护性。
使用设计模式的原因是为了使软件设计更加规范、模块化,从而提升代码的质量,使得软件更容易理解、维护和扩展。
设计模式分类
23种设计模式通常分为三大类,分别是:
- 创建型模式(Creational Patterns)
- 结构型模式(Structural Patterns)
- 行为型模式(Behavioral Patterns)
创建型模式(Creational Patterns)
创建型模式关注对象的创建机制,将对象的创建与使用分离开来,以便让系统更加灵活地决定创建哪个对象。创建型模式可以将对象创建的责任封装起来,从而使系统更加独立于具体的对象创建、组合和表示。
创建型模式包括但不限于:
- 单例模式(Singleton):确保一个类只有一个实例,并提供一个访问它的全局访问点。
- 工厂方法模式(Factory Method):定义一个创建产品对象的接口,让子类决定实例化哪一个类。
- 抽象工厂模式(Abstract Factory):提供一个创建一系列相关或依赖对象的接口,而无需指定它们具体的类。
- 建造者模式(Builder):将一个复杂对象的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
- 原型模式(Prototype):用原型实例指定创建对象的种类,并通过复制这些原型创建新的对象。
结构型模式(Structural Patterns)
结构型模式关注如何组合类或对象来形成更大的结构。这些模式可以让你的代码更加灵活地组合对象,以便创建出更加复杂的结构。
结构型模式包括但不限于:
- 适配器模式(Adapter):将一个类的接口转换成客户希望的另外一个接口。
- 装饰器模式(Decorator):动态地给一个对象添加一些额外的职责。
- 代理模式(Proxy):为其他对象提供一种代理以控制对这个对象的访问。
- 外观模式(Facade):为子系统中的一组接口提供一个一致的界面。
- 桥接模式(Bridge):将抽象部分与它的实现部分分离,使它们都可以独立地变化。
- 组合模式(Composite):将对象组合成树形结构以表示“部分-整体”的层次结构。
- 享元模式(Flyweight):运用共享技术有效地支持大量细粒度的对象。
行为型模式(Behavioral Patterns)
行为型模式关注对象之间的通信以及职责分配机制。它们描述了对象之间应该如何相互作用以及如何分配职责。
行为型模式包括但不限于:
- 策略模式(Strategy):定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。
- 模板方法模式(Template Method):定义一个操作中的算法骨架,而将一些步骤延迟到子类中。
- 观察者模式(Observer):定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
- 迭代器模式(Iterator):提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。
- 责任链模式(Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。
- 命令模式(Command):将一个请求封装为一个对象,从而使你可用不同的请求来参数化客户端。
- 备忘录模式(Memento):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
- 状态模式(State):允许一个对象在其内部状态改变时改变它的行为。
- 访问者模式(Visitor):表示一个作用于某对象结构中的各元素的操作。
- 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
- 解释器模式(Interpreter):给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
单例模式
分类:
- 饿汉式单例模式
- 懒汉式单例模式
- 线程安全的懒汉式单例模式
单例模式(Singleton Pattern) 是最简单的创建型设计模式。它的目的是确保一个类只有一个实例存在,并且提供一个全局访问点。
单例模式最重要的特点 是构造函数私有,从而避免外界直接使用构造函数直接实例化该类的对象。
单例模式的优点:
- 在一个对象需要频繁地销毁、创建,而销毁、创建性能又无法优化时,单例模式的优势尤为明显。
- 在一个对象的产生需要较多资源时,如读取配置、产生其他依赖对象时,则可以通过在启动时直接产生一个单例对象,然后用永久驻留内存的方式来解决。
- 单例模式可以避免对资源的多重占用,因为只有一个实例,避免了对一个共享资源的并发操作。
- 单例模式可以在系统设置全局的访问点,优化和共享资源访问。
单例模式的缺点:
- 单例模式无法创建子类,扩展困难,若要扩展,除了修改代码基本上没有第二种途径可以实现。
- 单例模式对测试不利。在并行开发环境中,如果采用单例模式的类没有完成,是不能进行测试的。
- 单例模式与单一职责原则有冲突。一个类应该只实现一个逻辑,而不关心它是否是单例的,是不是要用单例模式取决于环境。
单例模式在 Java 中通常有两种表现形式:
饿汉式单例模式
- 类加载时就进行对象实例化。
1 | public class Singleton { |
懒汉式单例模式(线程安全)
- 第一次引用类时才进行对象实例化。
- 线程安全问题:如果线程 A 和 B 同时调用此方法,会出现执行
if (instance == null)语句时都为真的情况,导致创建两个对象。为解决这一问题,可以使用synchronized关键字对静态方法getInstance()进行同步。
1 | public class Singleton2 { |
比较:饿汉式单例类的速度和反应时间要优于懒汉式单例类,但资源利用率不如懒汉式单例类。
工厂模式
分类:
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
工厂模式(Factory Pattern) 是一种创建型设计模式,其主要目的是封装对象创建的细节,使得创建过程更加灵活。工厂模式可以分为三种类型:简单工厂模式、工厂方法模式和抽象工厂模式。
简单工厂模式 实际上并不是严格意义上的设计模式,而是一种编程习惯。它通过定义一个工厂类来创建不同类型的对象,这些对象通常具有共同的父类或接口。
工厂方法模式 是简单工厂模式的进一步发展。在工厂方法模式中,我们不再提供一个统一的工厂类来创建所有的对象,而是针对不同的对象提供不同的工厂。每个对象都有一个与之对应的工厂,工厂方法模式让一个类的实例化延迟到其子类。
抽象工厂模式 是工厂方法模式的进一步深化。在这个模式中,工厂类不仅可以创建一个对象,而是可以创建一组相关或相互依赖的对象。这是与工厂方法模式最大的不同点。抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
简单工厂模式
简单工厂模式并不严格属于设计模式,而更多是一种编程习惯。其特点是定义一个工厂类,根据传入的参数不同返回不同的实例。这些实例通常具有共同的父类或接口。
示例代码:
1 | public interface Shape { |
1 | public class CircleShape implements Shape { |
1 | public class RectShape implements Shape { |
1 | public class TriangleShape implements Shape { |
1 | public class ShapeFactory { |
工厂方法模式
工厂方法模式定义了一个创建产品对象的工厂接口,将实际创建工作推迟到子类中。它具有良好的封装性和扩展性,可以降低模块间的耦合度。
示例代码:
1 | public interface Car { |
1 | public interface CarFactory { |
1 | public class Audi implements Car { |
1 | public class Auto implements Car { |
1 | public class AudiFactory implements CarFactory { |
1 | public class AutoFactory implements CarFactory { |
1 | public class ClientDemo { |
抽象工厂模式
抽象工厂模式为创建一组相关或相互依赖的对象提供一个接口,而无需指定它们的具体类。它适用于需要一组对象共同完成某种功能的场景。
示例代码:
1 | interface OperationController { |
策略模式
策略模式(Strategy Pattern) 是一种行为设计模式,它使你能在运行时改变对象的行为。策略模式定义了一系列算法,并将每一个算法封装起来,使它们可以互相替换。
策略模式允许在运行时改变算法的行为。它定义了包含算法族的接口,并且将算法的责任委托给一个子类。
1 | // 定义策略类型枚举类 |
1 | // 定义策略接口 |
1 | // 策略实现类 A |
1 | // 配置类,注入Bean |
1 | // 使用策略模式 |
责任链模式
责任链模式(Chain of Responsibility Pattern)能够将请求沿着处理者的链进行发送。收到请求后,每个处理者均可对请求进行处理,或将其传递给链上的下一个处理者。
假设我们有一个系统,需要处理不同级别的日志消息(debug、info、warning、error)。
1 | // 抽象处理者类 |
模板方法模式
模板方法模式(Template Method Pattern)定义了一些基本步骤,并让子类实现某些步骤。它允许子类重写某些步骤而不改变整个算法。
假设我们需要设计一个游戏框架,其中包含一些固定的流程,但每个游戏的具体实现不同。
1 | abstract class Game { |
观察者模式
观察者模式(Observer Pattern)允许对象在状态发生变化时通知多个观察者对象,而无需使对象知道观察者是谁。
假设我们有一个天气预报系统,需要实时更新天气信息,并通知不同的观察者(如用户界面、天气API等)。
1 | interface Observer { |
适配器模式
适配器模式(Adapter Pattern) 是一种结构型设计模式,它能让不兼容的接口协同工作。适配器模式充当了两个不同接口之间的桥梁。
适配器模式让两个没有关联的接口能够一起工作。适配器通过包装一个类的方法来实现所需的目标接口。
1 | // 目标接口 |
装饰器模式
装饰器模式(Decorator Pattern) 是一种结构型设计模式,它允许向部分对象添加新的功能,同时不会影响其他对象的功能。装饰器模式可以动态地给一个对象添加一些额外的责任。
装饰器模式允许你给对象动态地添加职责,而无需修改对象本身的结构。它是继承关系的一个替代方案。
1 | // 组件接口 |
—————————————
Netty
网络通信的过程
服务端是怎么接收客户端的消息的?服务端是如何感知到数据的?
服务器使用非阻塞I/O(NIO)来接收客户端的消息。具体过程如下:
- 接收连接: 服务器通过
ServerSocketChannel监听特定端口,并接受来自客户端的连接请求,创建SocketChannel。 - 读取数据: 服务器在处理客户端连接时,会调用
SocketChannel.read()方法读取客户端发送的数据。此方法会将数据填充到一个ByteBuffer中。 - 感知数据到达: 服务器在循环中持续读取数据,直到没有更多数据可读。如果
read()方法返回的字节数大于0,说明有数据到达。 - 解析数据: 服务器在读取数据后,将数据进行解码。
- 循环处理: 服务器会继续循环,等待并处理后续消息,直到客户端关闭连接。
这种方式使得服务器能够有效地处理多个客户端的连接和消息,同时能够感知数据的到达。
常见的I/O 模型
- 阻塞I/O(Blocking I/O):每个I/O操作都需要等待,效率较低。
- 非阻塞I/O(Non-blocking I/O):调用I/O操作后立即返回,可以通过轮询来检查操作是否完成。
- 多路复用(Multiplexing I/O):使用
select、poll、epoll等机制,同时监视多个I/O操作,适合高并发场景。 - 异步I/O(Asynchronous I/O):操作完成时会通知应用程序,避免了轮询。
NIO和BIO的区别
NIO(New IO)和BIO(Blocking IO)是Java编程语言中用于处理输入输出(IO)操作的两种不同机制,它们之间存在一些显著的区别。
工作原理:
BIO:这是一种同步阻塞式IO。服务器实现模式为“一个连接一个线程”,即当客户端发送请求时,服务器端需要启动一个线程进行处理。如果连接不进行任何操作,会造成不必要的线程开销。虽然可以通过线程池机制改善这个问题,但在高并发环境下,BIO的性能可能会受到影响,因为每个连接都需要创建一个线程,而且线程切换开销较大。
NIO:这是一种同步非阻塞式IO。服务器实现模式为“一个请求一个线程”,即客户端发送的连接请求都会注册到多路复用器(采用事件驱动思想实现)上,多路复用器轮询I/O请求时才启动一个线程进行处理。NIO在处理IO操作时,会把资源先操作至内存缓冲区,然后询问是否IO操作就绪。如果就绪,则进行IO操作;否则,进行下一步操作,并不断轮询是否IO操作就绪。
资源利用:
- BIO:由于每个连接都需要创建一个线程,因此在高并发环境下可能会导致大量线程的创建和管理,这会增加系统开销。
- NIO:通过单线程处理多个通道(Channel)的方式,减少了线程的数量,从而降低了系统开销。此外,NIO使用缓冲区(Buffer)进行数据的读写,提高了IO的处理效率。
应用场景:
BIO:适合一些简单的、低频的、短连接的通信场景,例如HTTP请求。
NIO:适用于高并发、长连接、大量数据读写的场景,如文件传输、分布式计算等。
讲讲Java NIO
- 背景与目的
- NIO是为了弥补传统同步阻塞IO模型中的不足而设计的。它提供了更快的、基于块的数据处理方式。
- 核心概念
- Buffer(缓冲区):Buffer是NIO的核心组件之一,它是一个可以直接访问的数组,用于存储不同数据类型的数据。所有数据都会先经过Buffer来处理,无论是读取还是写入。
- Channel(通道):Channel是另一个关键组件,它允许数据从一个地方传输到另一个地方。与传统的流(Stream)不同,Channel是双向的,支持同时进行读写操作。
- Selector(选择器/多路复用器):Selector负责监听一个或多个Channel,并通知应用程序有关Channel的状态变化,如是否准备好进行读或写操作等。
- 工作流程
- 当应用程序需要读取数据时,数据首先被读取到Buffer中。
- 写入数据时,数据是从Buffer写入到Channel。
- Selector用于监控多个Channel的状态,并且当Channel准备好了相应的操作时,Selector会通知应用程序。
- 通过Selector返回的SelectionKey,可以获取就绪状态的Channel,并执行相应的IO操作。
- 优势
- NIO相比传统的IO模型更加高效,因为它允许单个线程管理多个Channel连接,从而提高了并发处理能力。
*讲讲Netty,它解决了什么问题?
- Netty是一个高性能、异步的事件驱动的网络应用框架,主要用于构建快速、可扩展的网络服务器和客户端。它简化了网络编程的复杂性,如处理TCP连接、数据传输、协议解析等,使开发者能够更专注于业务逻辑。
- Netty是一个高性能、异步事件驱动的网络应用程序框架,用于快速开发可靠的协议服务器和客户端。它基于Java NIO(非阻塞IO),提供了丰富的API来简化网络编程的复杂性。Netty可以用于开发多种协议的服务端和客户端,如HTTP、WebSocket、SMTP等,也可以用来开发自定义的二进制协议。
- Netty是一个基于NIO模型的高性能网络通信框架,它是对NIO网络通信的封装,我们可以利用这样一些封装好的api去快速开发一个网络程序。
- Netty在NIO的基础上做了很多优化,比如零拷贝机制、高性能无锁队列、内存池,因此性能比NIO更高。
- Netty可以支持多种的通信协议,例如:Http、WebSocket等,并且针对一些通信问题,Netty也内置了一些策略,例如拆包、粘包,所以在使用过程中会比较方便。
Netty 的应用场景
- 高性能网络服务器(如游戏服务器、即时通讯工具)
- 微服务架构中的服务通信
- WebSocket服务器
- 数据传输层(如RPC框架)
*为什么要使用Netty?Netty的特点
Netty相比与直接使用JDK自带的api更简单,因为它具有这样一些特点:
- 统一的api,支持多种传输类型、比如阻塞、非阻塞,以及epoll、poll等模型
- 可以使用非常少的代码去实现多线程Reactor模型,以及主从多线程Reactor模型
- 自带编解码器,解决了TCP粘包拆包的问题
- 自带各种通信协议
- 相比JDK自带的NIO,有更高的吞吐量、更低的延迟、更低的资源消耗、更低的内存复制
- 安全性较好,有完整的 SSL/TLS 的支持
- 经历了各种大的项目的考验,社区活跃度高,例如:Dubbo、Zookeeper、RocketMQ
*Netty可以做什么事情?
我们之所以要使用Netty,核心的点是要去解决服务器如何去承载更多的用户同时访问的问题,传统的BIO模型由于阻塞的特性使得在高并发的环境种很难去支持更高的吞吐量,尽管用NIO的多路复用模型可以在阻塞方面进行优化,但是它的api使用较为复杂,而Netty是基于NIO的封装,提供了成熟简单易用的api,降低了使用成本和学习成本,本质上来说Netty和NIO所扮演的角色是相同的,都是是去为了提升服务端的吞吐量,让用户获得更好的产品体验。
Netty的核心组件
Netty有三层结构构成的,分别是:
网络通信层,有三个核心组件:
Bootstrap负责客户端启动,并且去连接远程的Netty ServerServerBootStrap负责服务端的监听,用来监听指定的一个端口Channel负责网络通信的一个载体——事件调度器。
事件调度层,有两个核心角色:
EventLoopGroup本质上是一个线程池,主要去负责接收IO请求,并分发给对应的EventLoop去执行处理请求EventLoop是相对于线程池里面的一个具体线程
事件调度层的工作流程
- 初始化:在 Netty 应用启动时,首先创建
EventLoopGroup,然后根据需要创建EventLoop。 - 注册:当客户端或服务端建立连接时,会创建一个
Channel,并将该Channel注册到EventLoop上。 - 事件处理:一旦
Channel上有事件发生(如读写事件),相应的EventLoop就会被唤醒,并处理这些事件。 - 任务执行:除了处理 I/O 事件外,
EventLoop还可以执行用户提交的任务,如定时任务、异步任务等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19EventLoopGroup bossGroup = new NioEventLoopGroup(); // (1) 负责接受传入的连接请求
EventLoopGroup workerGroup = new NioEventLoopGroup(); // (2) 负责处理已经被接受的连接上的 I/O 操作
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup) // (3) 将 `bossGroup` 和 `workerGroup` 绑定到 `ServerBootstrap`
.channel(NioServerSocketChannel.class) // (4) 指定使用的 `Channel` 类型
.childHandler(new ChannelInitializer<SocketChannel>() { // (5) 设置一个 `ChannelInitializer`,用于初始化 `Channel` 的 `Pipeline`
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new EchoServerHandler());
}
});
ChannelFuture f = b.bind(port).sync(); // (6) 绑定并开始监听端口
f.channel().closeFuture().sync(); // (7) 等待 `ServerChannel` 关闭
} finally {
bossGroup.shutdownGracefully(); // (8) 关闭 `EventLoopGroup`,释放所有资源
workerGroup.shutdownGracefully(); // (9) 关闭 `EventLoop`,释放所有资源
}服务编排层,有三个核心组件:
ChannelPipeline负责处理多个ChannelHandler,他会把多个Channelhandler的过成一个链,去形成一个PipelineChannelHandler主要是针对10数据的一个处理器,数据接收后,就通过指定的一个上Handler进行处理ChannelHandlerContext是用来去保存ChannelHandler的一个上下文信息的。
Reactor 线程模型、其原理和作用
Reactor线程模型是基于事件驱动的模型,主要分为三个角色:
- Reactor:负责监视I/O事件并分发事件。
- Handler:处理具体的业务逻辑。
- Worker:执行I/O操作。可以使用多个Worker线程处理具体的请求,提高并发性能。
Netty提供了三种Reactor模型的支持:
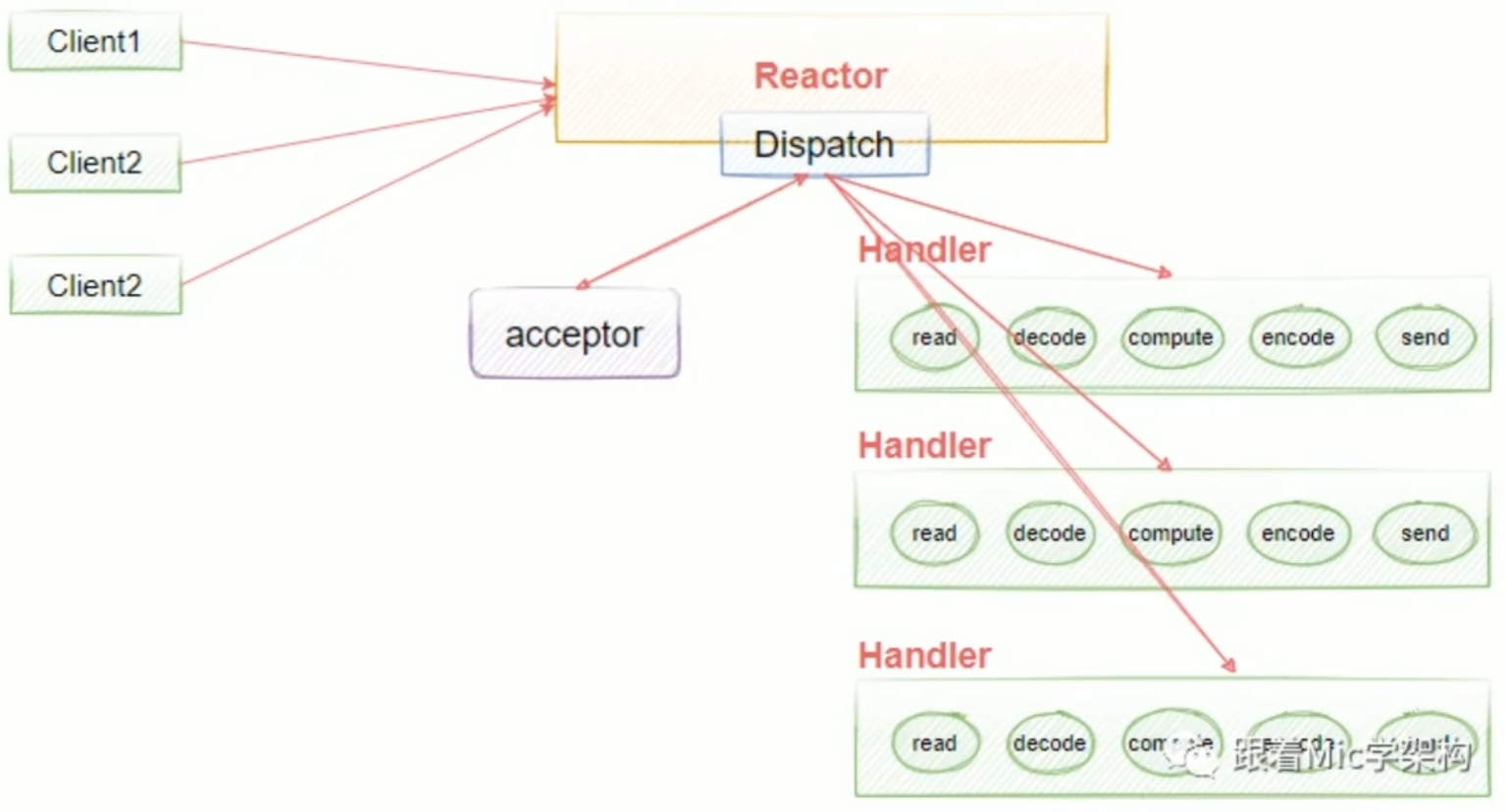
单线程单Reactor模型。单线程单Reactor模型也有缺点:如果其中一个Handler的出现阻塞,就会导致后续的客户端无法被处理,因为它们是同一个线程,所以就导致无法接受新的请求。为了解决这个问题,就提出了使用多线程的方式,也就是说在业务处理的时候加入线程池去异步处理,这样就可以解决handlers阻塞的一个问题。
多线程单Reactor模型。为了解决单线程中handlers阻塞的问题,我们引入了线程池去异步处理,这意味着我们把Reactor和handlers放在不同的线程里面去处理。在多线程单Reactor模型中,所有的IO操作都是由一个Reactor来完成的,这导致单个Reactor会存在一个性能瓶颈,对于小容量的场景影响不是很大,但是对于高并发的一些场景来说,很容易会因为单个Reactor线程的性能瓶颈,导致整个吞吐量会受到影响,所以当这个线程超过负载之后,处理的速度变慢,就会导致大量的客户端连接超时,超时之后往往会进行重发,这反而加重了这个线程的一个负载,最终会导致大量的消息积压和处理的超时,成为整个系统的一个性能瓶颈,所以我们还可以进行进一步的优化,也就是引入多线程多Reactor模型。
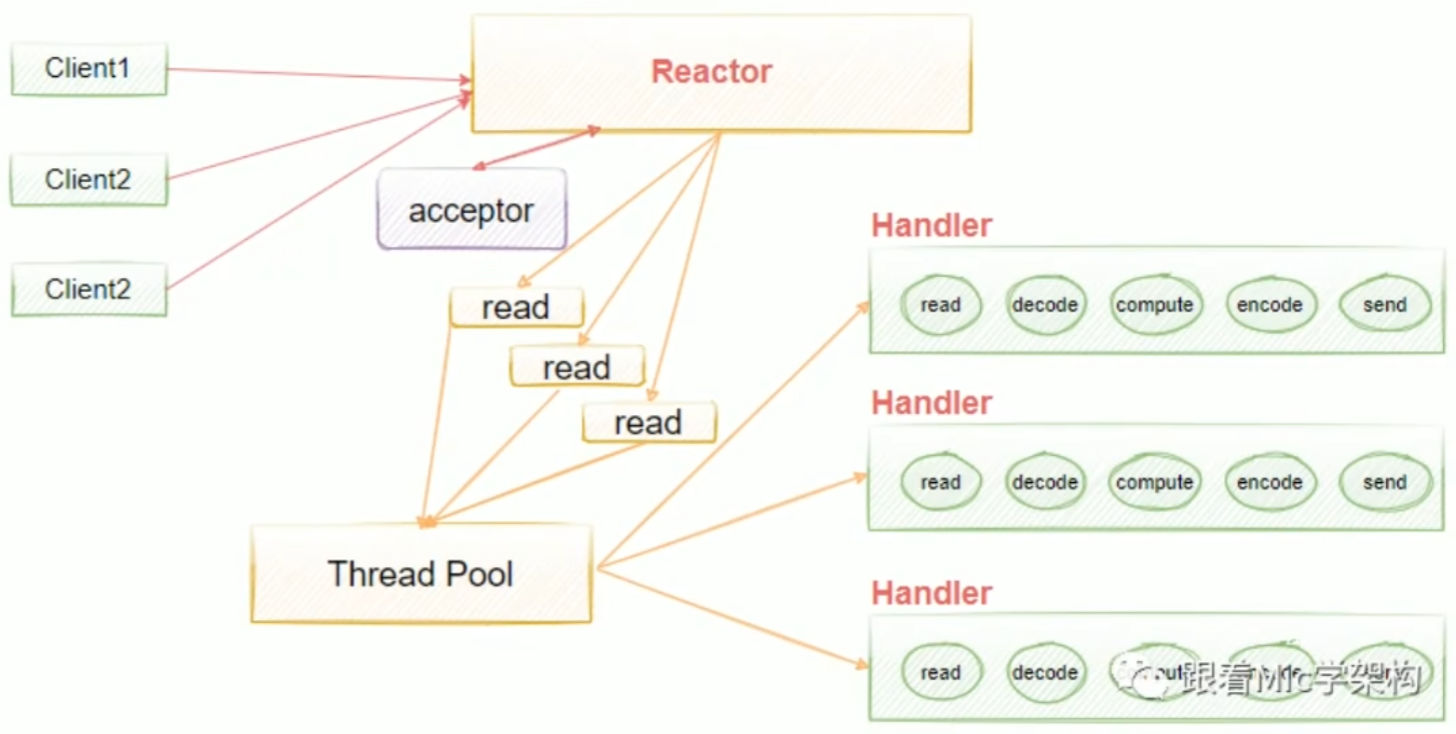
多线程多Reactor模型,也叫主从多线程Reactor模型。Main Reactor负责接收客户的连接请求,然后把接收的请求传递给Sub Reactor,Sub Reactorl我们可以配置多个,这样我们可以去进行灵活的扩容和缩容,具体的业务处理由Sub Reactor去完成,由它最终去绑定给对应的handler。Main Reactor扮演请求接收者,它会把接收的请求转发到Sub Reactor来处理,由Sub Reactor去进行真正意义上的分发。
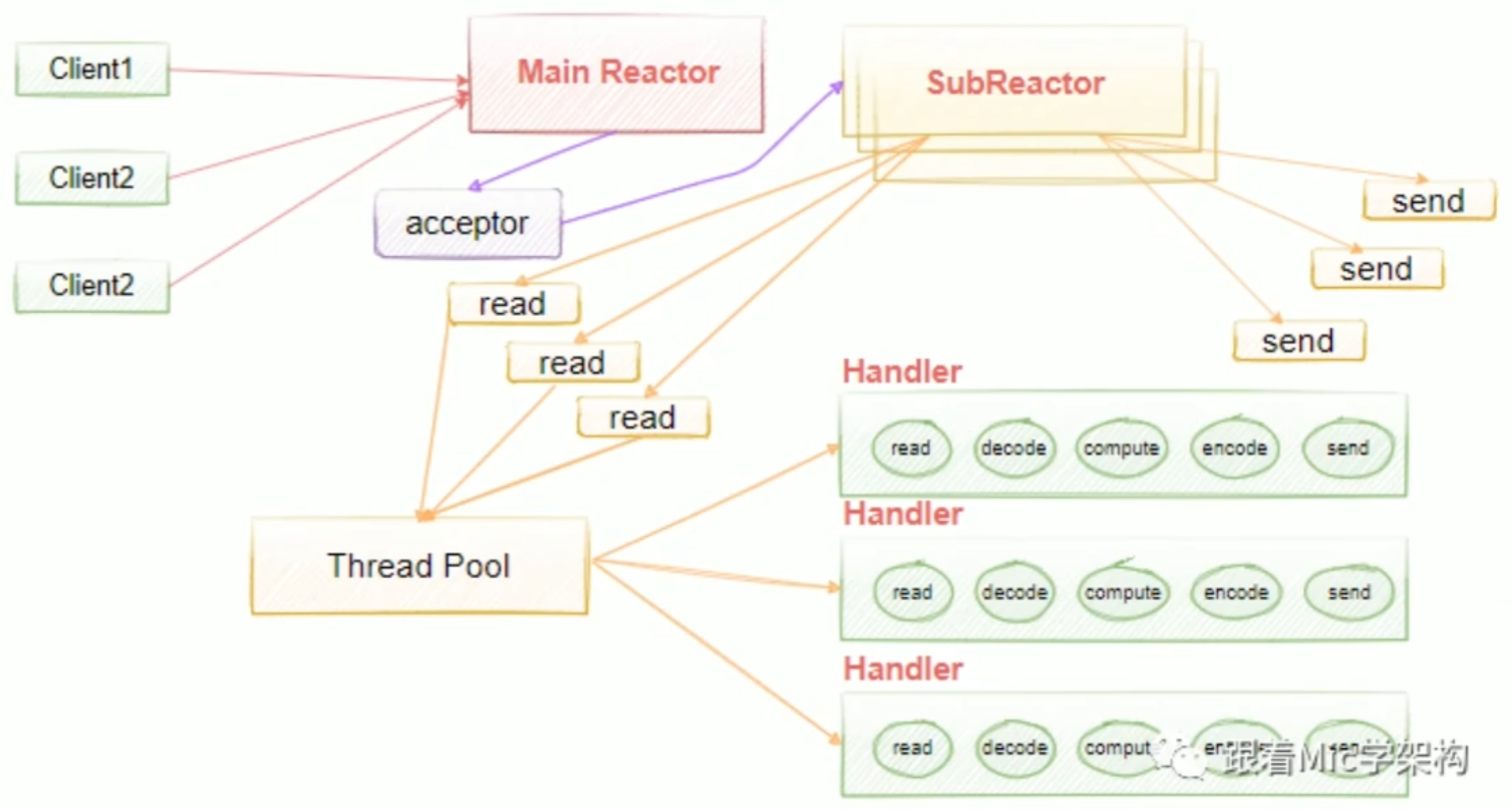
Reactor模型有三个重要的组件:
Reactor负责将IO事件分派给对应的HandlerAcceptor处理客户端的连接请求handlers负责执行我们的业务逻辑的读写操作
高性能设计
- 非阻塞IO模型:Netty基于NIO实现,使用非阻塞IO模型,减少了线程的使用,从而减少了上下文切换的开销。
- 事件驱动:Netty采用了事件驱动的设计模式,当有IO事件发生时,才会被处理,这样可以有效地利用CPU资源。
- 零拷贝技术:Netty支持直接缓冲区(DirectByteBuffer),在数据传输中减少了数据的拷贝次数,提高了数据传输的效率。具体做法是:使用
FileChannel的transferTo()和transferFrom()等方法实现文件传输时,避免了将数据从用户空间复制到内核空间的过程,提高了性能。 - 线程模型:Netty提供了高效的线程模型,如Boss/Worker模型,使得任务的分配更加合理,充分利用多核CPU的计算能力。
Netty 中的设计模式
- 单例模式:如EventLoop。
- 观察者模式:事件的注册和触发。
- 责任链模式:通过ChannelPipeline处理多个ChannelHandler。
- 适配器模式:将不同的Handler统一处理。
处理粘包、拆包问题
在Netty中,粘包和拆包的问题通常通过消息编码器和解码器(如LengthFieldBasedFrameDecoder、DelimiterBasedFrameDecoder等)来解析数据流。
Netty提供了几种方式来处理这种情况:
- 定长消息:如果消息长度固定,可以直接读取固定长度的数据。
- 使用分隔符(Delimiters):对于文本协议,可以使用特定的分隔符(如’\n’)来分隔消息。
- 自定义协议头:在消息前加上长度字段,这样接收方可以根据长度字段读取完整的消息。
- 使用现成的编解码器:Netty提供了如LengthFieldBasedFrameDecoder这样的解码器,它可以根据消息长度字段自动处理粘包和拆包的问题。
异步非阻塞的IO操作
Netty通过使用Java NIO(非阻塞IO)技术实现了异步非阻塞的IO操作。具体来说:
- NIO:Netty基于Java NIO来实现非阻塞IO模型,使用
Selector来监听多个Channel的事件,当有事件发生时,Selector会通知相应的Channel进行处理。 - EventLoop:Netty中的
EventLoop是一个不断循环的线程,负责处理绑定在其上的Channel的所有IO操作。每个EventLoop都关联了一个Selector,用来监听Channel上的事件。 - Channel:每个
Channel都绑定了一个或多个ChannelHandler,用来处理读写事件。当有事件发生时,EventLoop会调用相应的ChannelHandler来处理事件。
示例代码如下:
1 | // 创建EventLoopGroup |
消息的有序发送
在Netty中实现消息的有序发送,可以通过以下几种方式:
- 单线程模型:如果业务逻辑要求消息必须按顺序发送,可以将所有消息的发送操作放在同一个线程中执行。这样可以保证消息的顺序性。
- ChannelPipeline:利用
ChannelPipeline中的ChannelHandler来控制消息的顺序。可以自定义ChannelHandler来实现消息的排队发送。 - ChannelFutureListener:使用
ChannelFutureListener来监听ChannelFuture的状态,确保前一个消息发送成功后再发送下一个消息。
示例代码如下:
1 | public class OrderedMessageHandler extends SimpleChannelInboundHandler<String> { |
异步任务的调度
Netty提供了ScheduledExecutorService来实现异步任务调度。ScheduledExecutorService可以用来安排定时任务,包括一次性任务和周期性任务。
示例代码如下:
1 | public class ScheduledTaskHandler extends SimpleChannelInboundHandler<String> { |
参考计数
Netty中的参考计数(Reference Counting)是Netty为了管理内存而采用的一种机制。它主要用于追踪ByteBuf的引用次数。每个ByteBuf都有一个内部的引用计数器,当ByteBuf被引用时,计数器加一;当引用被释放时,计数器减一。
当ByteBuf的引用计数降到0时,意味着没有引用再指向这个ByteBuf,此时Netty会自动释放这个ByteBuf所占的内存空间。这种方式可以防止内存泄漏,并且在多线程环境下确保内存的安全释放。
异常的处理方案
在Netty中,异常处理通常是通过ChannelFutureListener和ChannelInboundHandler来实现的。
- ChannelFutureListener:可以注册一个ChannelFutureListener来监听ChannelFuture的完成状态,当操作失败时,可以抛出异常或进行其他错误处理。
- ChannelInboundHandler:当ChannelPipeline中的某个Handler抛出异常时,可以通过实现ExceptionCaught()方法来捕获并处理这些异常。通常在这个方法中打印堆栈跟踪信息或采取其他补救措施。
此外,Netty还提供了全局异常处理机制,可以注册GlobalChannelInboundHandler来处理所有未捕获的异常。
Netty 如何解决 NIO 中的空轮询 Bug
Netty通过使用Selector的poll方法,并结合EventLoop进行优化,避免了空轮询的情况。它会在没有事件时进行适当的休眠,减少CPU资源的浪费。
Netty底层原理
Channel、ChannelHandlerContext
- Channel:表示一个连接,可以是服务器端或客户端的
SocketChannel,它负责数据的读写。 - ChannelHandlerContext:表示在ChannelPipeline中每个ChannelHandler的上下文,提供了访问Channel和其他Handler的功能,用于在Handler之间传递事件和数据。
ChannelPipeline是什么?它是如何工作的?
ChannelPipeline是Netty中的一个重要概念,它是一个责任链模式的具体实现。
在Netty中,每当有数据从网络到达或者需要发送数据时,数据会沿着ChannelPipeline中的处理器链进行传递。每个处理器(Handler)都可以对数据进行处理,比如编码、解码、日志记录等。ChannelPipeline使得我们可以方便地组织和管理这些处理器,按需插入、删除或替换处理器,从而实现了高度的灵活性。
ChannelPipeline是Netty中的一个责任链模式的实现,用于管理一系列的ChannelHandler。它的工作原理如下:
- 责任链:
ChannelPipeline中包含了一系列的ChannelHandler,这些ChannelHandler按照添加的顺序组成一个责任链。 - 消息传递:当有消息从网络到达或需要发送时,消息会沿着
ChannelPipeline中的ChannelHandler传递。 - 事件传播:除了消息外,
ChannelPipeline还可以传播各种事件,如连接建立、关闭等。 - 上下文管理:通过
ChannelHandlerContext来管理当前ChannelHandler的上下文信息。
示例代码如下:
1 | public class MyInitializer extends ChannelInitializer<SocketChannel> { |
ChannelHandler是什么?它们之间是如何通信的?
ChannelHandler是一个接口,它定义了处理网络事件的方法,如读取数据、写入数据等。我们通常会实现这个接口或者继承自AbstractChannelHandler来创建自定义的处理器。
ChannelHandler之间可以通过ChannelPipeline来通信。ChannelPipeline管理了一系列的ChannelHandler,并按照顺序处理消息。
- 消息传递:消息从一个ChannelHandler传递到另一个ChannelHandler时,会按照ChannelPipeline中定义的顺序依次处理。每个ChannelHandler可以对消息进行处理、修改或转发。
- Context传递:ChannelHandlerContext提供了与ChannelHandler相关的上下文信息,包括获取当前ChannelHandler的前后Handler,以及发送消息给当前Channel或者管道中的其他ChannelHandler。
- 事件传播:除了消息外,ChannelPipeline还可以传播各种事件,如连接建立、断开等。这些事件同样会按照顺序传递给ChannelPipeline中的各个ChannelHandler。
示例代码如下:
1 | public class MyHandler extends ChannelInboundHandlerAdapter { |
ChannelHandlerContext是什么?有什么作用?
ChannelHandlerContext则是ChannelHandler的上下文环境,它提供了与处理器相关的上下文信息,比如可以获取当前处理器的前一个和下一个处理器,以及用于发送消息、注册定时器等功能的方法。ChannelHandlerContext在处理器中非常关键,因为它让我们可以方便地与ChannelPipeline交互。
ChannelHandlerContext是Netty中的一个重要的上下文环境对象,它提供了与ChannelHandler相关的上下文信息。主要作用包括:
- 上下文信息:提供当前
ChannelHandler的上下文信息,如获取当前ChannelHandler的前后ChannelHandler。 - 消息传递:可以用来向当前
Channel或管道中的其他ChannelHandler发送消息。 - 事件传播:可以用来触发事件给当前
Channel或管道中的其他ChannelHandler。 - 访问Channel属性:提供了访问和修改
Channel属性的方法。
示例代码如下:
1 | public class MyHandler extends SimpleChannelInboundHandler<String> { |
Channel和ChannelHandlerContext的关系是什么?
在Netty中,Channel代表了网络连接的一个端点,它封装了网络连接的生命周期,包括连接、读取、写入等操。
ChannelHandlerContext则是Channel的一个上下文环境,它为ChannelHandler提供了执行上下文。
ChannelHandlerContext包含了当前ChannelHandler的信息,以及对ChannelPipeline的操作方法。通过ChannelHandlerContext,我们可以获取当前ChannelHandler的前后Handler,发送消息给当前Channel或者管道中的其他ChannelHandler,以及访问Channel的各种属性等。
Channel和ChannelFuture的区别是什么?
Channel和ChannelFuture`在Netty中有不同的作用:
- **
Channel**:代表了网络连接的一个端点,封装了网络连接的生命周期,包括连接、读取、写入等操作。Channel提供了执行这些操作的方法。 - **
ChannelFuture**:表示异步通道操作的结果,提供了方法来检查异步操作的状态,如是否完成、成功或失败等。ChannelFuture通常用于异步操作的同步等待和结果监听。
示例代码如下:
1 | public class MyServerInitializer extends ChannelInitializer<SocketChannel> { |
Selector机制是如何工作的?
Netty中的Selector机制主要用于处理网络连接的读写事件。在Java NIO中,Selector允许我们监听多个Channel的事件,如连接、读取、写入等。当有事件发生时,Selector会通知相应的Channel,这样我们就可以处理这些事件。
在Netty中,通常每个EventLoopGroup对应一个Selector,而每个EventLoop负责处理绑定到它的Channel的IO操作。当一个Channel上有事件发生时,EventLoop会轮询Selector,发现有事件就调用相应的Handler来处理。
EventLoop和EventLoopGroup有什么区别?
EventLoop和EventLoopGroup是Netty中用来处理IO操作的关键组件。
- EventLoop:它是Netty中的一个线程,负责处理绑定到它的Channel的IO操作,如读取、写入和连接等。每个EventLoop都有一个Selector,用来监听Channel上的事件。
- EventLoopGroup:它是一组EventLoop的集合,用于管理多个EventLoop。EventLoopGroup负责为新创建的Channel分配合适的EventLoop。Netty中有两种类型的EventLoopGroup:BossGroup和WorkerGroup。BossGroup负责接受客户端的连接请求,而WorkerGroup负责处理已经被接受的连接上的读写操作。
Future和Promise是什么?它们的作用是什么?
Netty中的Future和Promise是用于处理异步操作的结果和状态的。
- Future:表示异步操作的结果,它提供了一些方法来检查异步操作是否完成,以及获取操作的结果或抛出异常。使用Future可以很容易地实现异步编程模型。
- Promise:是一个特殊的Future,它还提供了一个方法来设置异步操作的结果。Promise通常用于Channel操作,如注册、连接、写入等,它允许在异步操作完成后设置结果或异常。
使用Future和Promise可以更好地控制异步操作的生命周期,处理异步回调中的异常,并且可以方便地进行链式调用。
—————————————
Java基础
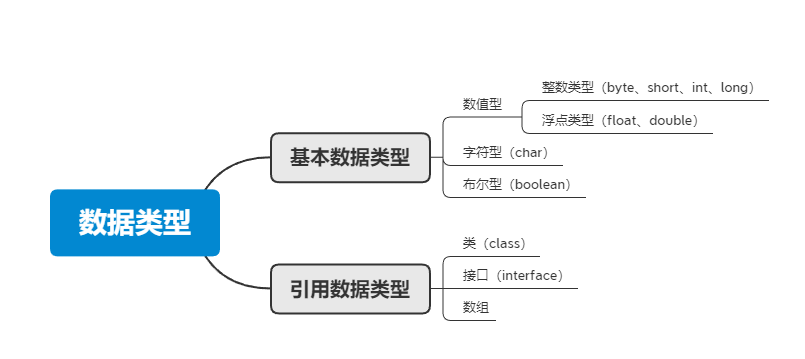
八种基本的数据类型
Java支持数据类型分为两类: 基本数据类型和引用数据类型。
基本数据类型共有8种,可以分为三类:
- 数值型:整数类型(byte、short、int、long)和浮点类型(float、double)
- 字符型:char
- 布尔型:boolean
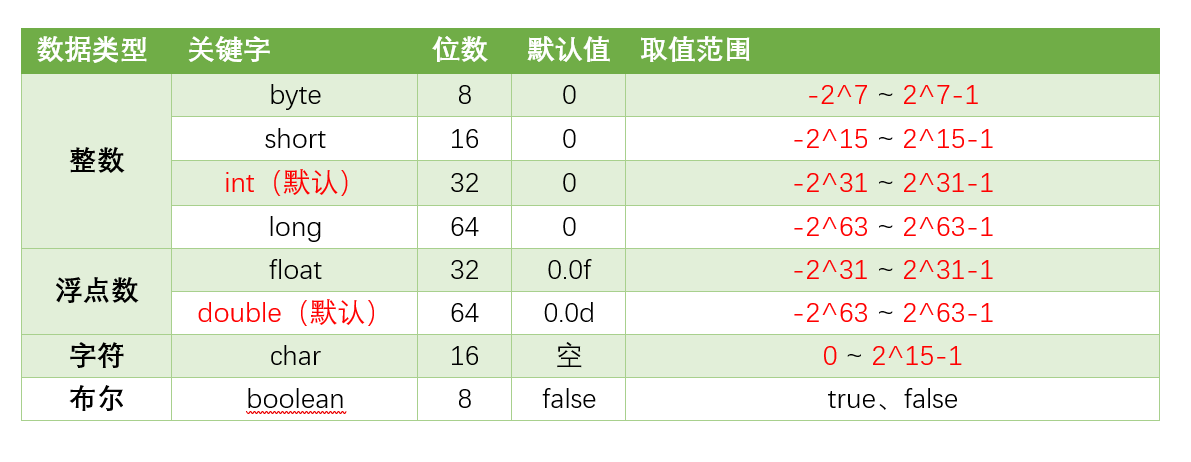
8种基本数据类型的默认值、位数、取值范围,如下表所示:
String、StringBuffer 和 StringBuilder 的区别
- String:不可变,适合少量字符串操作。
- StringBuffer:可变且线程安全,适合多线程环境中的频繁字符串修改,,内部使用了
synchronized关键字来保证多线程环境下的安全性。 - StringBuilder:可变且非线程安全,适合单线程环境中的高性能字符串处理,性能比
StringBuffer更高。
接口和抽象类有什么区别?
接口的设计是自上而下的。我们知晓某一行为,于是基于这些行为约束定义了接口,一些类需要有这些行为,因此实现对应的接口。
抽象类的设计是自下而上的。我们写了很多类,发现它们之间有共性,通过代码复用将公共逻辑封装成一个抽象类,减少代码冗余。
所谓的 自上而下 指的是先约定接口,再实现。
而 自下而上的 是先有一些类,才抽象了共同父类(可能和学校教的不太一样,但是实战中很多时候都是因为重构才有的抽象)。
其他区别
1)方法实现
接口中的方法默认是 public 和 abstract(但在 Java8 之后可以设置 default 方法或者静态方法)。
抽象类可以包含 abstract 方法(没有实现)和具体方法(有实现)。它允许子类继承并重用抽象类中的方法实现。
2)构造函数和成员变量
接口不能包含构造函数,接口中的成员变量默认为常量。
抽象类可以包含构造函数,成员变量可以有不同的访问修饰符。
3)多继承
抽象类只能单继承,接口可以有多个实现。
注解原理是什么?
注解其实就是一个标记,是一种提供元数据的机制,用于给代码添加说明信息。
注解可以标记在类上、方法上、属性上等,标记自身也可以设置一些值。
注解本身不影响程序的逻辑执行,但可以通过工具或框架来利用这些信息进行特定的处理,如代码生成、编译时检查、运行时处理等。
Java 反射机制
反射机制提供了在运行时动态创建对象、调用方法、访问字段等功能,而无需在编译时知道这些类的具体信息。
反射机制的优点:
- 可以动态地获取类的信息,不需要在编译时就知道类的信息。
- 可以动态地创建对象,不需要在编译时就知道对象的类型。
- 可以动态地调用对象的属性和方法,在运行时动态地改变对象的行为。
反射机制的缺点:
- 性能损失。
- 安全风险。
反射机制的应用场景:
- 动态代理。
- 测试工具。
- ORM框架。
深拷贝和浅拷贝有什么区别?
深拷贝:深拷贝不仅复制对象本身,还递归复制对象中所有引用的对象。这样新对象与原对象完全独立,修改新对象不会影响到原对象。即包括基本类型和引用类型,堆内的引用对象也会复制一份。
浅拷贝:拷贝只复制对象的引用,而不复制引用指向的实际对象。也就是说,浅拷贝创建一个新对象,但它的字段(若是对象类型)指向的是原对象中的相同内存地。
深拷贝创建的新对象与原对象完全独立,任何一个对象的修改都不会影响另一个。而修改浅拷贝对象中引用类型的字段会影响到原对象,因为它们共享相同的引用。

网络通信协议名词解释
以一个点外卖的例子解释什么是IP地址、端口号、Socket和协议。
IP地址:对应的是我们上班所在的一个大楼。
端口号:对应我们所在大楼里的一个具体房间。
Socket:进行通信的一个工具。
协议:通信要遵循的规则。
例子:
IP地址:外卖员要送餐到的大楼(例如:腾讯大楼)。
端口号:外卖员要到大楼里的具体房间(例如:1001)。
Socket:外卖员通过手机(Socket)与我们通信,告知外卖已到。
协议:我们默认使用中文对话。
Java 访问修饰符
- public:完全公开,任何地方都可以访问。
- private:仅限于本类内部访问。
- protected:本类内部及子类可以访问。
- 默认(无修饰符):包内可见,同包下的其他类可以访问。
| 修饰符 | 当前类 | 同一包内 | 子类(不同包) | 其他包 |
|---|---|---|---|---|
| public | 是 | 是 | 是 | 是 |
| protected | 是 | 是 | 是 | 否 |
| 默认(default) | 是 | 是 | 否 | 否 |
| private | 是 | 否 | 否 | 否 |
适用范围区别
- **
public**:类、接口、字段、方法、构造函数。 - **
protected**:字段、方法、构造函数(没有类)。 - 默认(包级别):类、字段、方法、构造函数。
- **
private**:字段、方法、构造函数(没有类)。
访问修饰符的选择
- **
public**:适用于需要被外部类广泛访问的成员。过多使用public可能导致封装性降低。 - **
protected**:适用于需要在继承关系中使用的成员。它提供了比public更严格的访问控制,但允许子类访问。 - 默认(包级别):适用于仅在同一包内使用的类和成员。适当使用可以隐藏实现细节,减少类之间的耦合。
- **
private**:适用于内部实现细节,确保类的内部数据和方法不会被外部直接访问。最严格的访问控制,保护类的封装性。
Java 字节码是什么?
字节码是编译器将源代码编译后生成的中间表示形式,位于源代码与 JVM 执行的机器码之间。
字节码由 JVM 解释或即时编译(JIT)为机器码执行。
字节码结构:
- Java 字节码是平台无关的指令集,存储在
.class文件中。每个.class文件包含类的定义信息、字段、方法,以及方法对应的字节码指令。
字节码指令集:
- Java 字节码包含一系列指令,如加载、存储、算术运算、类型转换、对象操作、控制流等。常见的指令包括
aload,iload,astore,iadd,if_icmpgt等。
执行过程:
- JVM 通过解释器逐条执行字节码,或通过 JIT 编译器将热点字节码片段即时编译为机器码,提高执行效率。
反射与动态代理:
- 通过 Java 反射 API,可以在运行时动态生成或修改字节码,从而创建代理对象或实现动态方法调用。
字节码增强与框架:
- 许多 Java 框架(如 Hibernate, Spring AOP)使用字节码增强技术,通过修改类的字节码来实现功能增强。常用工具包括 ASM、Javassist、CGLIB 等。
—————————————
数据库(MySQL、PostgreSql)
MySQL支持的存储引擎及其区别
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
在MySQL中提供了很多的存储引擎,比较常见有InnoDB、MyISAM、Memory
InnoDB:存储引擎是mysql5.5之后是默认的引擎,它支持事务、外键、表级锁和行级锁。DML操作遵循ACID模型,支持事务。有行级锁,提高并发访问性能。支持外键,保证数据的完整性和正确性。MyISAM:不支持事务、外键,只有表级锁,用的不多Memory:不支持事务、外键,只有表级锁,用的也不多,特点是能把数据存储在内存里
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务安全 | 支持 | 不支持 | 不支持 |
| 锁机制 | 表锁/行锁 | 表锁 | 表锁 |
| 外键 | 支持 | 不支持 | 不支持 |
PostgreSQL 的唯一存储引擎:Heap
Heap 存储引擎是 PostgreSQL 的默认存储引擎,也是唯一内置的存储引擎。它具有以下特点:
- 事务支持:支持 ACID、MVCC,支持多种隔离级别,如读已提交(Read Committed)、可重复读(Repeatable Read)和序列化(Serializable)。
- 索引支持:支持 B-Tree、Hash、GiST(通用搜索树)、SP-GiST(空间分区通用搜索树)、GIN(通用倒排索引)和 BRIN(块范围索引)。
- 数据类型支持:支持自定义数据类型。支持整数、浮点数、字符串、日期时间、UUID、JSON、XML、数组、范围类型等。
- 扩展性:支持插件和扩展,可以添加新的功能和模块。支持外部表(Foreign Tables),可以访问其他数据源的数据。
- 备份和恢复:支持物理备份和逻辑备份。支持点-in-time 恢复(PITR)。
- 性能优化:支持查询优化器,可以生成高效的查询计划。支持分区表,可以将大表分成多个小表,提高查询性能。
PostgreSQL 的扩展和存储层
虽然 PostgreSQL 只有一种默认的存储引擎,但它通过扩展机制支持其他存储层和功能。以下是一些常见的扩展:
- TimescaleDB:
- 一个专门为时间序列数据设计的 PostgreSQL 扩展。
- 支持高效的时间序列数据存储和查询。
- Citus:
- 一个用于水平扩展 PostgreSQL 的扩展,支持分布式查询和数据分片。
- 适用于大数据和高并发场景。
- PostGIS:
- 一个用于地理空间数据的扩展,支持 GIS(地理信息系统)功能。
- 支持空间索引、空间操作和地理数据类型。
- pg_stat_statements:
- 一个用于收集和报告查询统计信息的扩展。
- 帮助优化查询性能和识别慢查询。
- pg_partman:
- 一个用于管理和维护分区表的扩展。
- 支持自动分区和维护分区表的生命周期。
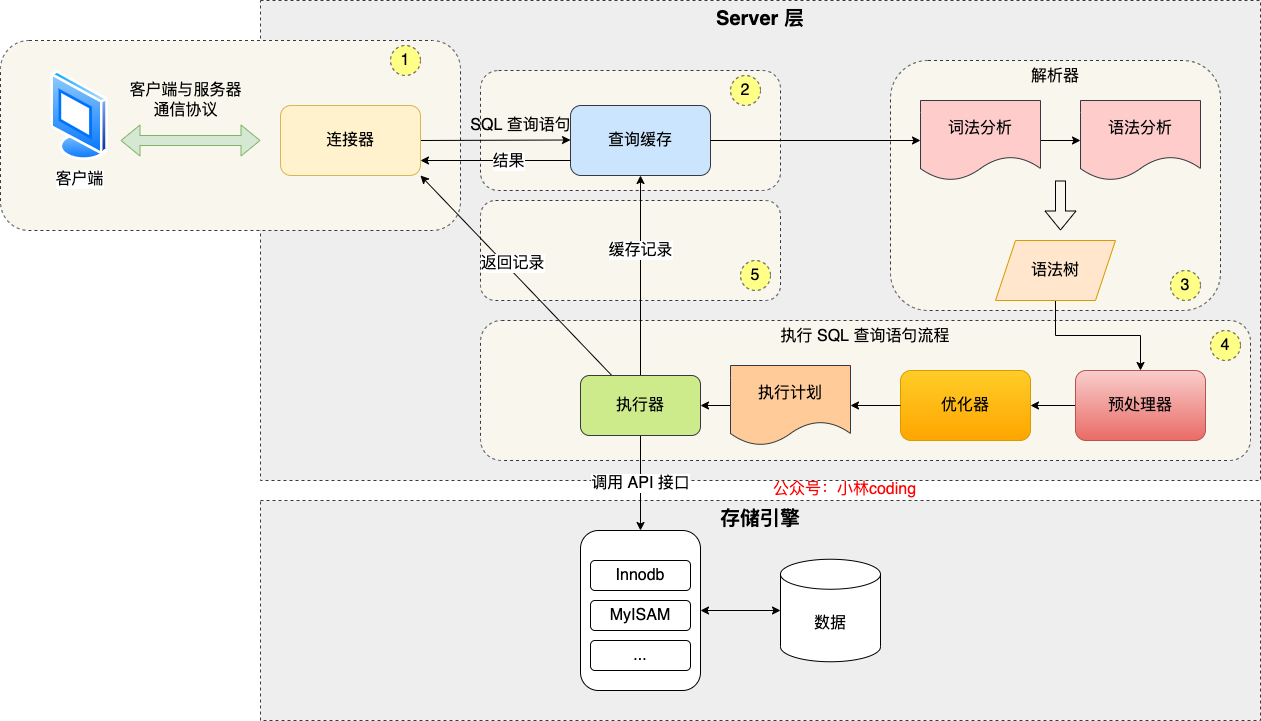
SQL语句在MySQL中的执行过程
(参数映射、sql解析、执行和结果处理)
- 连接器: 身份认证和权限相关(登录 MySQL 的时候)。
- 查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
- 分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- 优化器: 按照 MySQL 认为最优的方案去执行。
- 执行器: 执行语句,然后从存储引擎返回数据。
终极SQL分析——Hikvision
1 | WITH Sales_Summary AS ( |
这段 SQL 语句是一个较为复杂的查询,使用了多个公共表表达式(Common Table Expressions,简称 CTE),主要用于汇总和分析不同产品类别的销售数据、产品数量以及客户满意度,并找出每个产品类别中销售额最高的地区。下面是对这段 SQL 的详细分析:
SQL 语句分析
这段 SQL 使用 CTE 可以使查询语句更加简洁、清晰,并且提高了可维护性和可读性。
1. Sales_Summary CTE
1 | WITH Sales_Summary AS ( |
- 作用:计算每个产品类别在不同地区的总销售额,并为每个地区分配一个排名。
- 字段说明:
Product_Category:产品类别。Region:地区。Total_Sales_Region:该地区内的总销售额。rn:在相同产品类别下,按总销售额降序排列的地区排名。
2. Product_Summary CTE
1 | Product_Summary AS ( |
- 作用:计算每个产品类别的销售总额和不同产品的数量。
- 字段说明:
Product_Category:产品类别。Total_Sales:该产品类别的总销售额。Number_of_Different_Product_IDs:该产品类别下不同产品的数量。
3. Satisfaction_Averages CTE
1 | Satisfaction_Averages AS ( |
- 作用:计算每个产品类别的平均客户满意度。
- 字段说明:
Product_Category:产品类别。Average_Satisfaction_Score:该产品类别的平均满意度得分(保留两位小数)。
4. 主查询
1 | SELECT |
- 作用:最终查询结果,展示每个产品类别的总销售额、不同产品的数量、平均满意度以及销售额最高的地区。
- 字段说明:
ps.Product_Category:产品类别。ps.Total_Sales:该产品类别的总销售额。ps.Number_of_Different_Product_IDs:该产品类别下不同产品的数量。sa.Average_Satisfaction_Score:该产品类别的平均满意度得分。ss.Region AS Top_Sales_Region:销售额最高的地区。
WITH ... AS 用法解释
WITH ... AS 是 SQL 中的一个构造,用于定义公共表表达式(CTE)。CTE 是一个临时的结果集,只存在于包含它的查询中。它可以简化复杂的查询语句,使其更易读和维护。
优点
- 提高可读性:通过将复杂的查询拆分为多个CTE,可以使查询更加模块化和清晰。
- 减少重复:可以多次引用同一个CTE,避免重复编写相同的子查询。
- 提高性能:CTE 只执行一次,并且只在主查询需要时才执行,可以减少不必要的计算。
语法
1 | WITH CTE_Name (Column1, Column2, ...) |
对思考 last_updated 字段的意义
- 数据同步和一致性。在主从同步中,从数据库同步主数据库时,通过对比本地的
last_updated和主节点的last_updated,可以知道需要同步哪些数据 - 审计和追踪。
last_updated字段可以帮助定位最后一次更新的时间,进而确定变动的来源和责任人。 - 并发控制(乐观锁)。不必单独设置一个字段
version,但需要手动维护last_updated - 数据备份和恢复。在数据备份和恢复过程中,
last_updated字段可以用来判断哪些数据是最新的,哪些数据需要恢复。特别是在系统发生故障或数据丢失时,备份数据可能并非实时更新,因此需要依赖last_updated字段来进行增量恢复。 - 数据预热。在处理定期批量更新操作时,系统只需要查询那些
last_updated字段在某个时间范围内的数据,而不必每次都处理所有数据,减少了不必要的查询负担。
SQL优化方案
总结
表的设计优化
根据实际情况选择合适的数值类型(tinyint、int、bigint)
根据实际情况选择合适的字符串类型(char、varchar)
索引优化
对数据量打的表创建索引
对常作为查询条件、排序、分组的字段创建索引
尽量创建联合索引
控制索引的数量
……
SQL语句优化
合理编写SQL语句(避免直接使用select *、用union all代替union、能用inner join 就不用left join、right join、避免在where子句中对字段进行表达式操作)
避免SQL语句造成索引失效的写法(使用函数或表达式处理索引列、隐式类型转换、使用不等于(<> 或 !=)操作……)
主从复制、读写分离
分库分表
定位慢查询的方法
SQL执行很慢,可能有一下原因:聚合查询、多表查询、表数据量过大查询、深度分页查询
需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
1 | # 开启MySQL慢日志查询开关 |
配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息 /var/lib/mysql/localhost-slow.log

当然,也有相关的工具:
调试工具:Arthas
运维工具:Prometheus 、Skywalking
分析SQL语句
1 | - 直接在select语句之前加上关键字 explain / desc |

然后需要关注以下字段:
type:当前sql的连接的类型,性能由好到差为NULL、system、const、eq_ref、ref、range、 index、all
system:查询系统中的表
const:根据主键查询
eq_ref:主键索引查询或唯一索引查询
ref:索引查询
range:范围查询
index:索引树扫描
all:全盘扫描possible_key:当前sql可能会使用到的索引key:当前sql实际命中的索引key_len:索引占用的大小Extra:额外的优化建议Using where; Using Index:查找使用了索引,需要的数据都在索引列中能找到,不需要回表查询数据
Using index condition:查找使用了索引,但是需要回表查询数据
*例:给 JSON 类型字段添加虚拟列
eg. 以一张用户信息表为例
1 | CREATE TABLE `student` ( |
查询 json 类型的字段会走全表索引,耗时比较长,因此这时可以用虚拟列
1 | INSERT INTO student |
创建虚拟列及其索引,虚拟列的值会与 json字段中的指定的键值对匹配更新,如果没有就为null,非常省心
1 | ALTER TABLE student |
再分析sql性能,发现已经走虚拟列索引了(如果没走索引还是走全表,可能是数据量太少了)
1 | SELECT * |
—————————————
数据库-索引(MySQL)
索引
索引创建原则
- 数据量较大,且查询比较频繁的表
- 常作为查询条件、排序、分组的字段
- 字段内容区分度高
- 内容较长,使用前缀索引
- 尽量创建联合索引
- 控制索引的数量
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
索引失效情况
- 违反最左前缀法则
- 范围查询右边的列
- 在索引列上进行运算操作
- 字符串不加单引号
- 以%开头的Like模糊查询
索引不一定有效的原因
- 选择性差:如果索引列包含大量重复值(即选择性差),则查询优化器可能会决定全表扫描比使用索引更高效。
- 索引列少:如果查询涉及到多个条件,而索引只覆盖了部分条件,则可能不会被使用。
- 索引列顺序不当:对于复合索引,如果最左边的列不是查询中最常过滤的列,则索引可能不会被有效地利用。
- 数据范围广:如果查询返回的数据行接近整个表的大小,那么索引可能没有帮助,因为查询优化器可能会认为全表扫描更优。
- 未使用合适的访问类型:如使用
LIKE开头字符匹配或IN子句等,可能导致 MySQL 无法使用索引。 - 统计信息过时:MySQL 使用统计信息来决定是否使用索引,如果数据分布发生变化,需要更新统计信息。
B+树索引
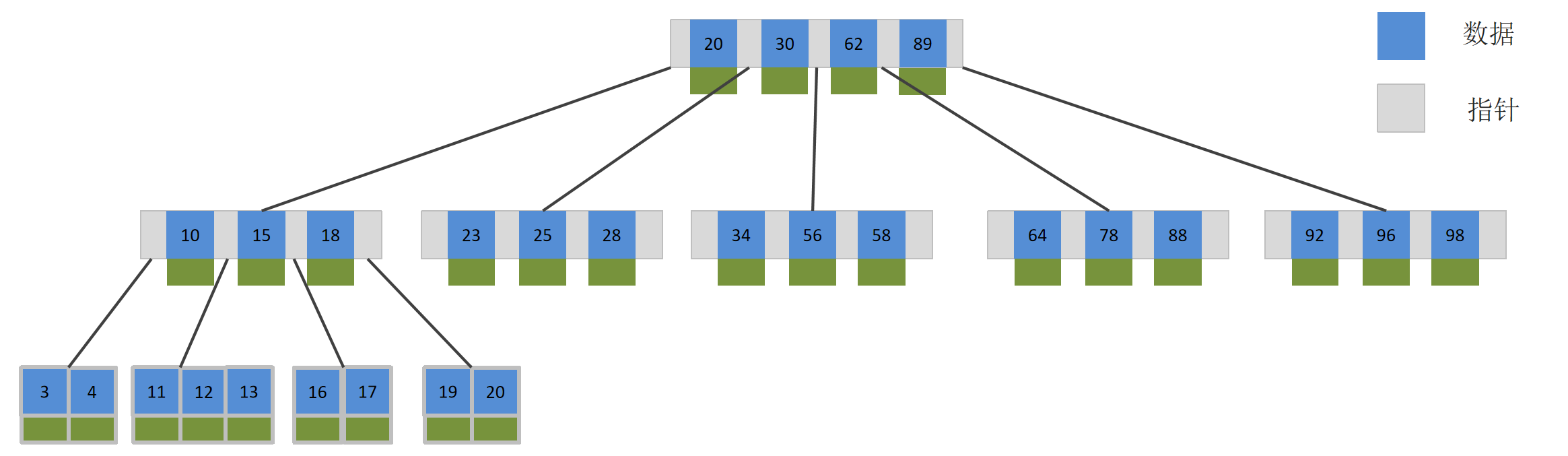
除了B+树类型的索引,还有全表索引、哈希索引……只是不太常用
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
特点:
- 索引是帮助MySQL高效获取数据的数据结构(有序)
- 提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
优点:
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点:
- 创建、维护索引或对表进行操作需要重构索引。
- 索引需要使用物理文件存储,也会耗费一定空间。
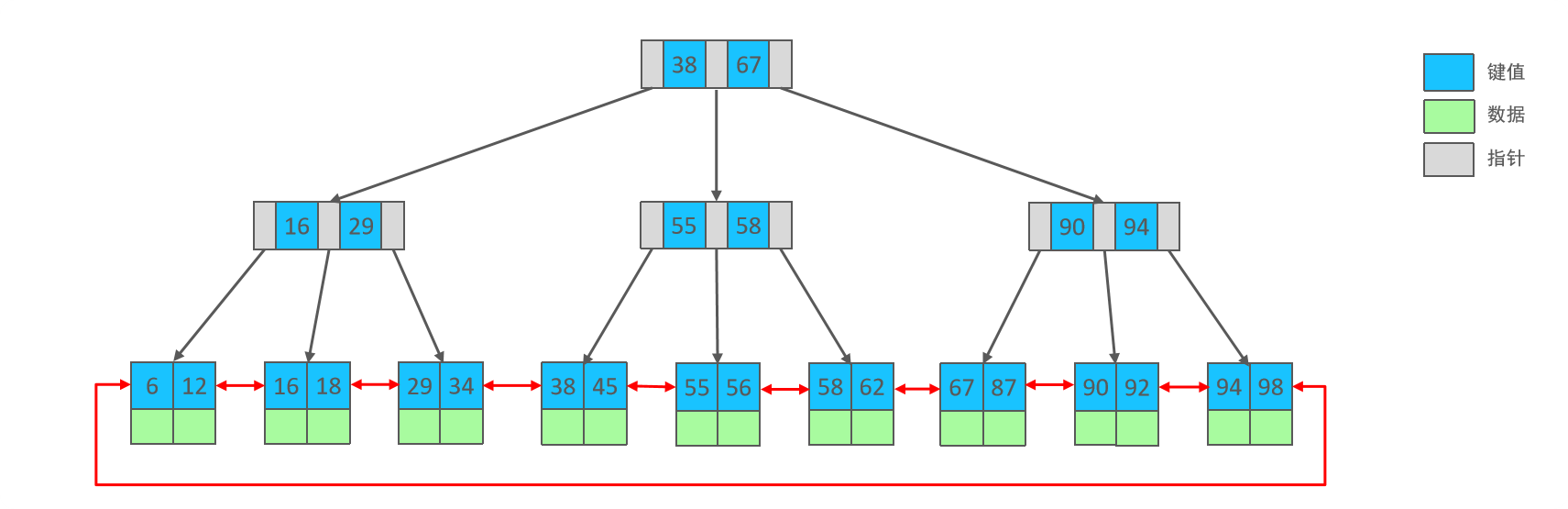
B树与B+树的区别是什么?
B+树比B树查找效率更高的原因:
- B+树的所有的数据都会出现在叶子节点,所以查找时首先只需考虑如何找到索引值,而不需要比较值;
- B+树叶子节点是一个有序的双向链表,适合进行范围区间查询。
- B树
- B+树
聚索引 & 非聚集索引
聚集索引:非叶子节点存储主键id,叶子节点存放主键id和整行数据。一张表有且只有一个聚集索引。
非聚集索引:非叶子节点存放索引字段,叶子节点存放索引字段和主键id。一张表可以有多个非聚集索引。
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚簇索引和非聚簇索引有的时候又称为主索引树和辅助索引树
回表查询
回表查询:通过二级索引找到对应的主键值,到聚集索引中查找整行数据,这个过程就是回表。
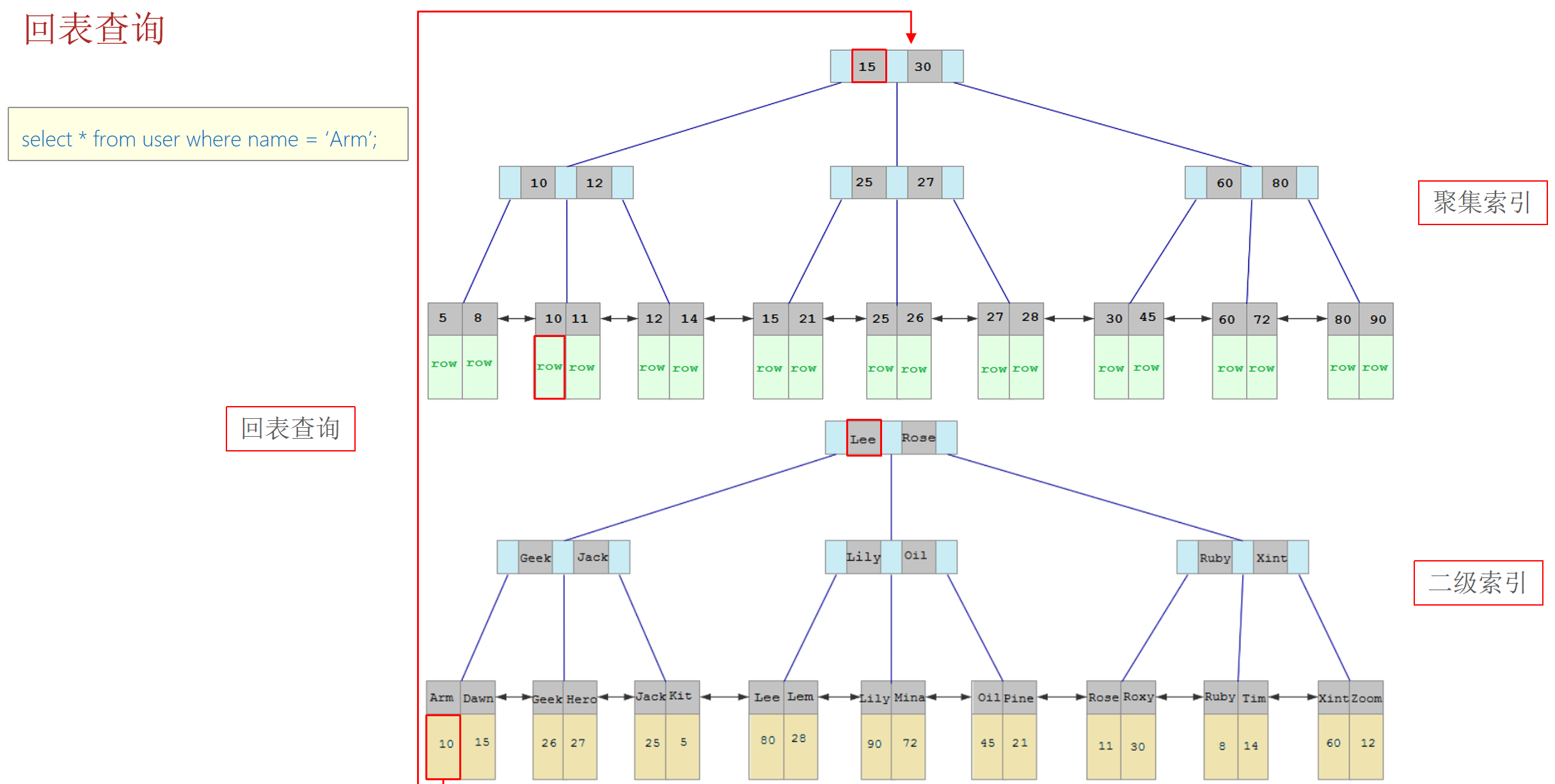
覆盖索引
覆盖索引:是指二级索引中包含了查询所需的所有字段,从而使查询可以仅通过访问二级索引而不需要访问实际的表数据(主键索引)。
- 使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
- 如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用
select *
超大分页处理方案
在数据量比较大时,limit分页查询,需要对数据进行排序,效率低,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引+子查询形式进行优化。
例如,该查询语句可以这样优化:
2
3
(select id from user order by id limit 9000000,10) a
where u.id = a.id;解释:采用子查询通过主键索引查询到了第9000000行的数据,接着顺序读取10行得到10个id,然后将这10行id与外部sql做一个自连接,通过主键索引树查询直接得到了第9000000后的10行数据。
索引的维护
索引的数据结构
首先通过两个类实现B+树非叶子节点和叶子结点:
非叶子节点类
InternalNode:1
private List<AbstractTreeNode<K, V>> childrenNodes; // 孩子节点
叶子节点类
LeafNode1
2
3private List<K> keys; // 叶子节点中的键,即主键索引值
private List<V> values; // 叶子节点中的值,即整行数据
private LeafNode<K, V> next; // 下一个叶子节点的指针
B+树的增删查改操作
**查 (Search)**:从根节点开始二分查找,B+树中使用二分查找可能在一个节点中找不到对应的结点,所以需要根据键值去子节点的孩子节点中遍历查找,直到找到叶子节点中对应的key和整行数据。

**改 (Update)**:先去查询,如果键已存在,更新其值;如果键不存在,则修改失败。
**删 (Delete)**:先去查询,进行删除,可以用
逻辑删除或删除-合并:逻辑删除:只清空整行记录,不清除键,保持B+树的形状。删除-合并:删除后如果节点元素过少,需要进行合并。
**增 (Insert)**:先去查询,查找插入位置,插入后判断是否需要分裂。分裂算法:new一个新的叶子节点,将当前叶子节点一半的键和键对应的值移动到新的叶子节点,然后将新的叶子节点插入到原本的叶子节点链表中。之后更新父节点的索引,将新的叶子节点中最小 的 key 传递给父节点,父节点插入这个新的 key 作为索引。如果父节点也超出了最大容量,同样会进行分裂并向上传递。当一个非叶子节点分裂时,都需要将分裂产生的新的 key 上移到父节点。如果父节点也满了,继续分裂并将
key递归上传。
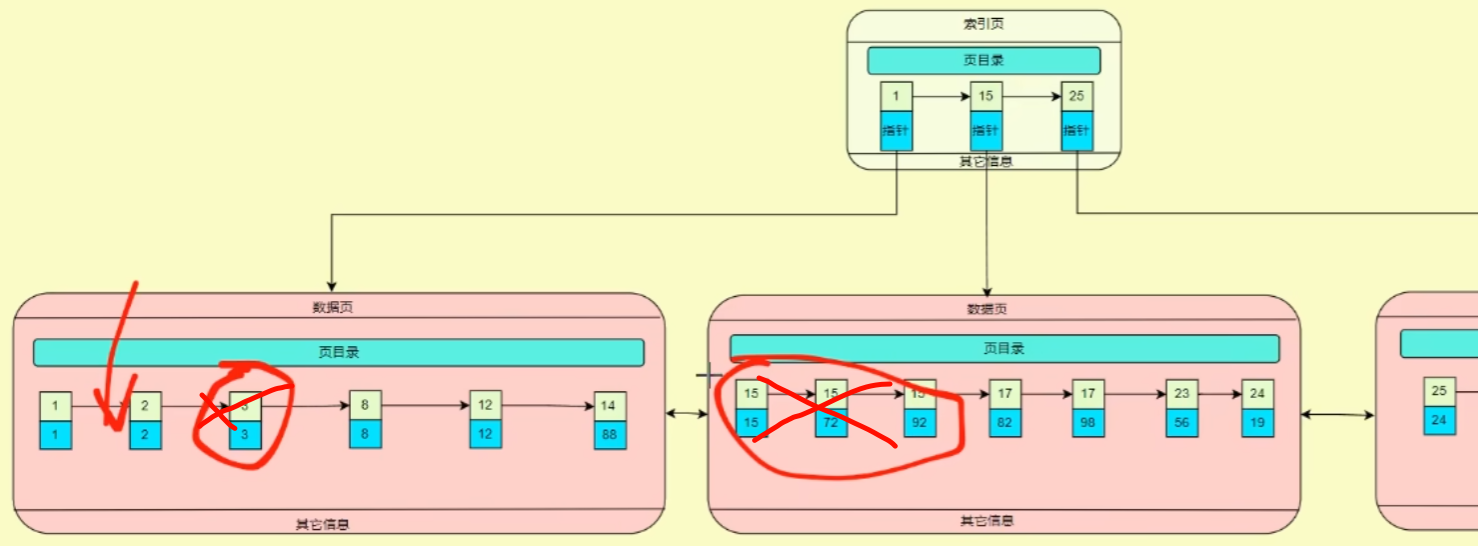
主键索引的维护
例如在执行下面这句话时:
1 | update user set id=id+1 where age=18; |
数据库会从 id 索引找到对应的数据行,然后更新 id 值。对于主键索引来说,更新主键值可能导致数据页移动,因为主键值是数据页的物理位置标识。
非主键索引的维护
非聚集索引的叶子节点存储了指向实际数据行的指针,如果修改了索引列的值,那么非聚集索引对应的叶子节点也会相应更新。
例如在执行下面这句话时:
1 | update user set money=1000 where age=18; |
- 根据
age主键索引去查询符合条件的的记录,对找到的行上排他锁 (X lock),保证并发事务的安全性和一致性,避免脏读、不可重复读等问题; - 对找到的行进行更新操作,去
money的非主键索引树修改money的数据。数据库会先删除原来的数据,然后按序将之前修改删除的索引结点插入在某个叶子结点后面; - 更新完成后,会释放所持有的锁,并提交事务。
底层原理:order by 的实现原理(MySQL 5.7)
这涉及到两种排序规则:
- 全字段排序(有主键的情况走这种,几乎所有情况都是这样的)
- row id排序(没有主键的情况走这种,不太常见)
假设有以下SQL语句,
1 | SELECT name,age,city |
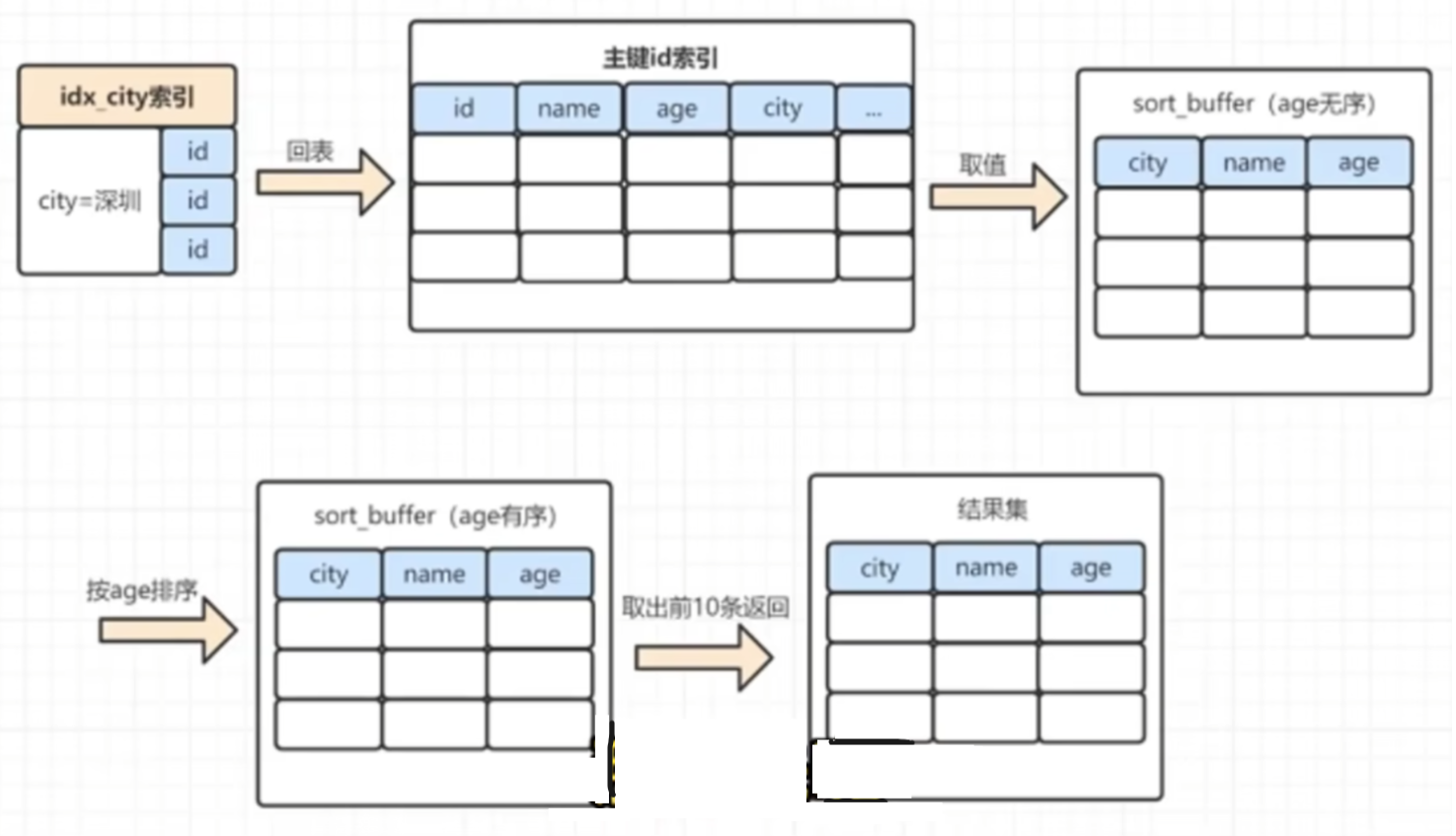
全字段排序加载过程
最普遍的情况,有主键的情况下采用全字段排序
- 根据索引从聚集索引树中找到对应的ID;
- 在聚集索引树找到对应的整行数据;
- 将查询字段(很多人会用
*,导致内存消耗很大)和排序字段加载到sort buff; - 在sort buff中根据关键字进行排序;
- 取出前10条数据,返回结果集。
row id排序加载过程
row id排序比全字段排序多了一次回表,但是比全排序占用更少的内存
- 根据索引从非聚集索引树中找到对应的ID;
- 在聚集索引树找到对应的整行数据;
- 将数据的主键(省内存的原因)和排序字段加载到sort buff;
- 在sort buff中根据关键字进行排序;
- 取出前10条数据,再去进行一次回表查询得到整行数据;
- 根据查询的字段值,返回结果集。
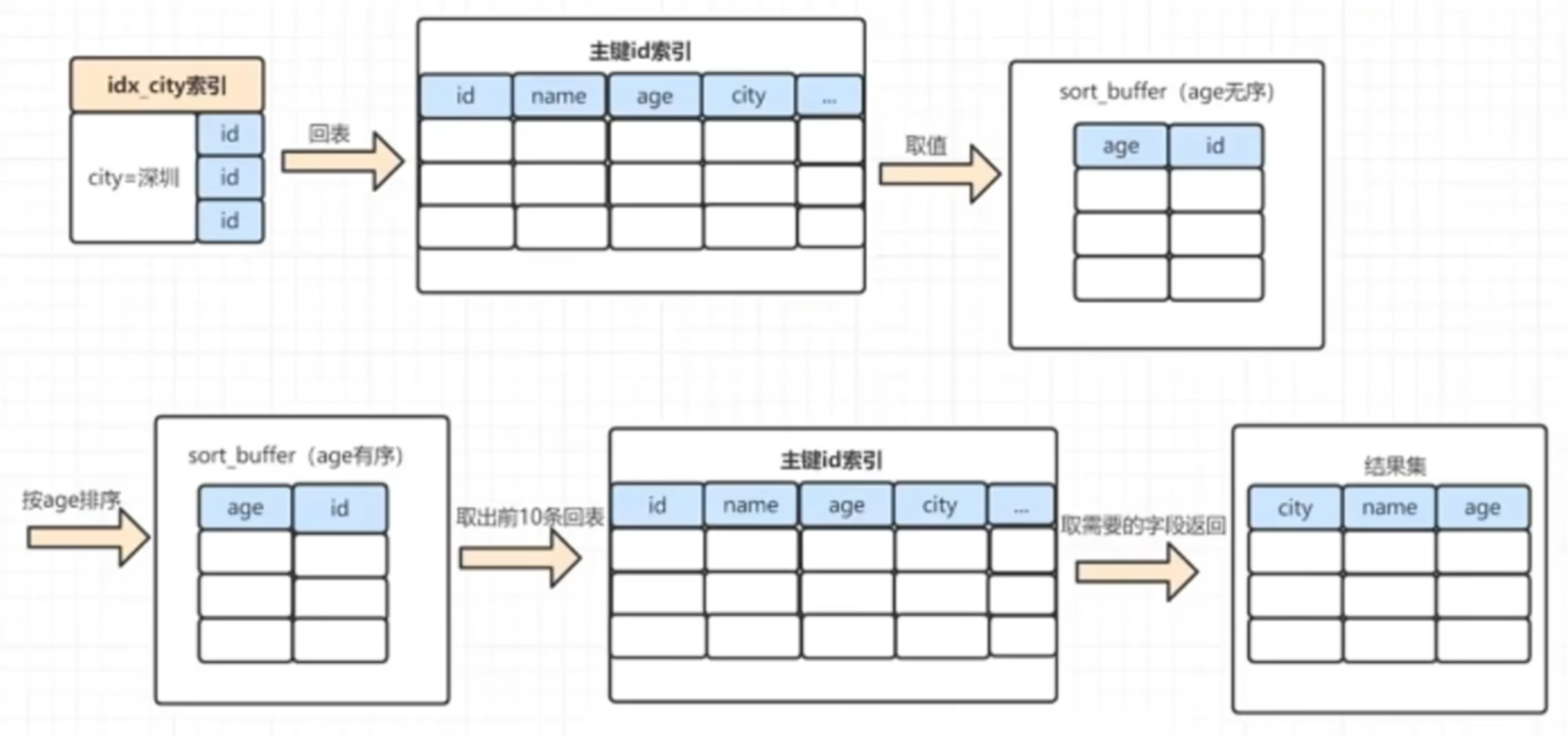
拓展:sort buffer
sort buffer的作用
sort buffer 指的是用于排序操作的内存缓冲区。当执行排序操作时,例如使用 ORDER BY 子句对结果集进行排序,数据库可能会使用一个或多个排序缓冲区来存储数据。
- 减少I/O操作:通过在内存中暂存要排序的数据,可以减少从磁盘读取数据的次数,从而提高排序速度。
- 提高排序效率:在内存中进行排序通常比在磁盘上进行排序更高效。因此,使用
sort buffer可以帮助加快排序过程。
sort buffer的工作原理
- 数据加载:当数据库需要对查询结果进行排序时,它首先会将部分数据加载到
sort buffer中。 - 排序操作:数据加载完成后,数据库会在
sort buffer内执行排序算法。如果数据量超过了sort buffer的容量,则可能需要将部分数据写入临时文件,并进行外部排序。 - 结果输出;排序完成后,数据库会将排好序的数据返回给客户端或用于进一步处理。
如何配置 sort buffer
在MySQL中,sort_buffer_size是一个全局或会话级别的系统变量,用于控制每个客户端连接可用的 sort buffer 的大小。
可以通过以下命令查看或修改该参数:
1 | SHOW VARIABLES LIKE 'sort_buffer_size'; |
调整 sort_buffer_size 可以影响排序操作的性能。如果设置得过小,可能导致频繁地将数据写入磁盘,从而降低性能;如果设置得过大,则可能消耗过多内存资源。
—————————————
数据库-事务(InnoDB)
锁
表锁
表级锁是最粗粒度的锁,会对整个表进行锁定,导致并发性能较差。MyISAM 支持以下两种类型的锁:
- 读锁(READ LOCK):当 SELECT 语句执行时,会自动获得读锁,此时其他事务可以读取数据,但不能修改数据。
- 写锁(WRITE LOCK):当 INSERT、UPDATE 或 DELETE 语句执行时,会自动获得写锁,此时其他事务既不能读也不能写。
由于 MyISAM 已经不再推荐使用,并且在新版本的 MySQL 中逐渐被淘汰,因此表级锁的使用也逐渐减少。
行锁
行级锁对表中的行进行锁定,而不是整个表,这样可以大大提高并发性能。InnoDB 支持以下几种类型的锁:
- 共享锁(Shared Locks, S-Locks):当 SELECT 语句带有 FOR SHARE 或者事务处于可重复读隔离级别时,会请求共享锁。共享锁允许其他事务读取数据,但阻止其他事务修改同一行数据。
- 排他锁(Exclusive Locks, X-Locks):当事务需要写入数据时,会请求排他锁。排他锁不允许其他事务读取或修改同一行数据。
其他类型的锁
除了上述的锁类型外,InnoDB 还有一些特殊的锁机制:
- 意向锁(Intention Locks):这是一种元锁,它并不锁住具体的行,而是表明事务打算对表中的行加锁。例如,意向共享锁(IS)表明事务打算对某行加共享锁,意向排他锁(IX)表明事务打算对某行加排他锁。
- 间隙锁(Gap Locks):间隙锁锁定的是索引项之间的“间隙”,防止其他事务插入新的行到这个间隙中。在可重复读RR隔离级别下,InnoDB 默认会使用间隙锁。
- Next-Key Locks:Next-Key 锁是 InnoDB 默认使用的锁类型,它是共享锁或排他锁与间隙锁的组合。它不仅锁住索引项本身,还会锁住索引项之间的间隙,以防止幻读现象。
死锁检测的基本原理
- 定时检测:使用定时检测。如果发现等待队列(Wait Queue)增长到一定长度时,就会触发一次死锁检测。
- 图算法:使用图算法。它构建了一个等待图(Wait-for Graph),在等待图中,节点代表事务,边表示事务间的等待关系。如果有环路(Cycle)存在,那么就表示发生了死锁。
死锁解决机制
一旦检测到死锁,InnoDB 就会采取措施来解决它。具体做法如下:
- 选择牺牲者:当检测到死锁时,InnoDB 会选择一个或多个事务作为“牺牲者”,这些事务将被回滚,以解除死锁。
- 选择标准:InnoDB 根据一定的标准来选择牺牲者。一般情况下,InnoDB 会选取一个最小的事务作为牺牲者。这个最小事务通常是基于事务的开始时间、事务的大小(即所持有的锁的数量)等因素来决定的。
- 通知用户:InnoDB 在回滚了某个事务后,会生成一条错误信息(如 Error 1213 Deadlock found when trying to get lock),并通过客户端 API 返回给应用程序。应用程序可以根据这个错误信息来进行相应的处理。
事务
事务的ACID特性?事务的并发解决方案?
- 事务的特性:
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
- 事务并发的问题:
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另外一个事务还没有提交的数据。 |
| 不可重复读 | 并发更新时,另一个事务前后查询相同数据时的数据不符合预期。 |
| 幻读 | 并发新增、删除这种会产生数量变化的操作时,另一个事务前后查询相同数据时的不符合预期 |
- 事务的并发解决方案:对事务进行隔离
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read Uncommitted 读未提交:可以直接读取到其他事务未提交的事务 | × | × | × |
| Read Committed 读已提交:要等待其他事务提交后才能读取 | √ | × | × |
| Read Repeatable 可重复读 (默认) :通过MVCC机制确保一个事务内多次执行相同的查询会得到相同的结果 | √ | √ | × |
| Serializable 串行化:加入读锁,阻塞式处理事务 | √ | √ | √ |
长事务可能会导致哪些问题?
会有性能问题,具体如下:
- 锁定资源:可能会占用大量的锁资源。
- 死锁(Deadlock):存在两个或更多事务互相等待对方释放资源。
- 内存消耗:长事务占用较多的内存资源,特别是回滚段(undo segment)的空间,从而影响系统的性能。
- 日志文件增长:长事务会导致日志文件快速增长,这需要更多的磁盘空间,并且在恢复时需要更多的时间。
底层原理:TRANSACTION语法的意义
START TRANSACTION;
当执行 START TRANSACTION; 命令时,MySQL 将当前的会话设置为非自动提交模式。这意味着任何随后的 SQL 操作都不会自动持久化到磁盘上,而是保存在事务的内存缓冲区中。在这个阶段,数据库会记录每一步操作的日志到redo log和undo log中,以备提交或回滚。
底层原理:
- 事务开启:创建一个事务记录,并初始化事务的状态为活动状态。
- 非自动提交模式:**设置会话的自动提交标志为
false**,这样后续的 SQL 操作不会立即生效。 - 记录日志:对于每一个 SQL 操作,都会记录对应的重做日志(Redo Log),用于事务提交时的数据恢复。
COMMIT;
执行 COMMIT; 命令表示事务已经成功完成,所有的事务操作都应该被永久地保存到数据库中。此时,数据库将确保所有事务中的更改都已正确地应用,并且任何后续的操作都不能影响到这些更改。
底层原理:
- 事务提交:事务进入提交阶段,数据库系统会将事务中的所有更改标记为永久有效。
- 写入磁盘:将事务期间记录的所有重做日志(redo Log)写入到磁盘上的日志文件中,确保即使在系统崩溃的情况下也能恢复数据。
- 释放资源:事务完成后,释放事务期间占用的资源,如锁定的行或表等。
- 通知监听器:事务提交后,可能会通知正在等待该事务完成的其他事务或监听器。
ROLLBACK;
执行 ROLLBACK; 命令表示事务中的所有操作都将被撤销,数据库将回到事务开始前的状态。这意味着事务中所做的任何更改都不会被保存到数据库中。
底层原理:
- 事务回滚:事务进入回滚阶段,数据库系统会恢复到事务开始前的状态。
- 撤销更改:通过事务日志(undo Log)来撤销事务期间所做的更改。
- 释放资源:事务回滚后,同样会释放事务期间占用的资源,如锁定的行或表等。
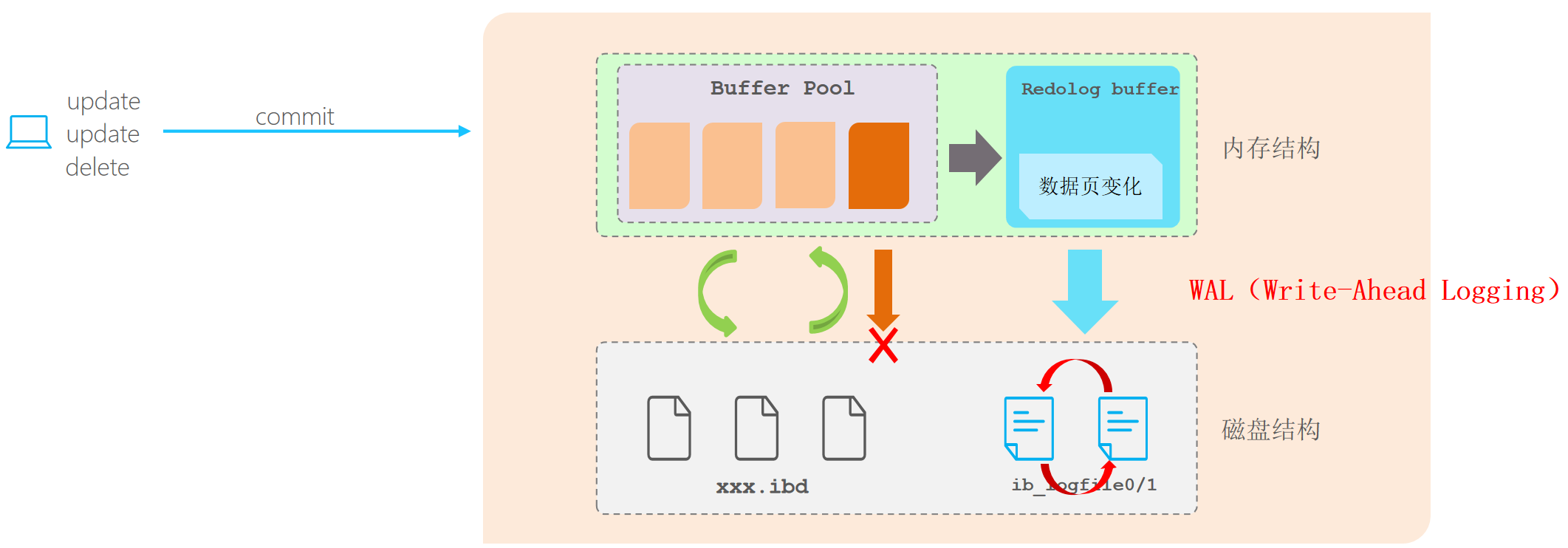
WAL
WAL(预写日志,Write-Ahead Logging)是一种数据保护机制,它在对数据进行实际写操作之前,先将这些操作记录到日志文件中,确保在数据库对外部变化(如崩溃、电源中断等)进行恢复时,数据的一致性和持久性。
WAL 的工作过程
- 日志条目的写入:当数据库要进行更改时,不是直接更改数据文件,而是先将这些更改记录到 WAL 文件中。只有在这些日志条目已经安全地存储到磁盘之后,数据库才会开始更新实际的数据。这种方法允许数据库在意外崩溃之后,通过查阅 WAL 文件来恢复所有未完成的事务,进而恢复到一致的状态。
- 检查点机制:为了保障 WAL 文件不会无限制地增长,数据库会定期创建检查点。这些检查点允许删除旧的 WAL 文件,并减少恢复所需的时间。
WAL 的优点
- 数据恢复:WAL 是保证数据一致性的重要手段。它提供了一种在出现故障时快速恢复数据库的方法。通过读取 WAL 文件,数据库可以重做(redo)在崩溃前进行的所有操作,从而恢复到崩溃时的状态。
- 写性能优化:由于可以将多个更改合并成一个大块进行写入,WAL 有助于优化磁盘写入性能。这减少了对磁盘的频繁小量写操作。
- 异步备份:WAL 文件可以用于进行异步日志传输,提供了数据库的备份和恢复方案,支持只读副本和灾难恢复。
WAL 与 MVCC
- MVCC 机制用来管理并发事务,
- WAL 文件则用来记录事务的更改历史。
在故障恢复时,先使用 WAL 恢复未提交的事务,然后根据 MVCC 的版本控制进行数据的回滚。
MVCC
MVCC是如何保证数据的可恢复性的?
MVCC需要保障如下两条原则:
正在进行的事务不会读取未提交的事务产生的数据。
正在进行的事务不会修改未提交的事务修改或产生的数据。
于是,MVCC就通过如下步骤实现了数据回滚:
MVCC通过维护每个事务的开始时间和版本号来判断是否需要回滚。当事务试图读取或修改数据时,系统会比较当前数据版本与事务的开始时间。如果事务尝试访问的版本在其开始时间之后已被其他事务提交,那么该事务会被标记为需要回滚,因为它基于过时的数据进行操作。这种机制确保了数据的一致性和隔离性。
行的可见性判定
每一行都有两个特殊的字段:
xmin:创建这个行的事务 IDxmax:删除/更新它的事务 ID
当一个事务读取数据时,它会根据 xmin 和xmax 判断当前事务的可见性。
那么一条记录什么时候是可见的呢?
满足如下两个条件:
xmin对应的事务已经提交xmax对应的事务未提交或未开始
什么是事务日志 / redo log,undo log?
总结:
1 | redo log: 记录的是数据页的物理变化,服务宕机可用来同步数据 |
redo log:重做日志,确保了已提交的事务在数据库崩溃重启后,能够保持数据的持久性和一致性。redo log是物理日志,它包含以下两种类型的信息:
- 物理页的变化:某些数据库系统(如Oracle)可能直接记录数据页变化后的状态。这意味着在重做日志中,你会看到一个数据页在某次操作之后的样子。
- 操作的描述:另一些数据库系统(如MySQL的InnoDB存储引擎)则记录了如何重做某个特定操作的信息,即记录了需要对哪些页进行什么样的更新才能重现这些页在事务提交后的状态。
undo log:回滚日志,确保了未提交的事务在数据库崩溃重启后,不会对数据库的数据造成影响,实现隔离性。此外在可重复读取隔离等级下,undo log 还可以维持读取视图的一致性,即保证同一个查询在事务内多次执行时返回相同的结果。undo log是逻辑日志,它的基本结构特点如下:
- 版本链(Version Chain):
- 在 InnoDB 存储引擎中,每个数据页都有一个版本链,其中包含了该页上所有行的多个版本。这些版本信息是由 Undo Log 维护的。
- 重做片段(Undo Segments):
- Undo Log 通常被组织成 Undo Segments,每一个 Undo Segment 包含一个或多个 Undo Records。Undo Segments 可以进一步分为两类:Insert Undo Segments 和 General Undo Segments。
- Insert Undo Segments 主要用于插入操作的事务,当事务只包含插入操作时,可以使用 Insert Undo Segments。一旦事务提交,这部分 Undo Log 就不再需要,可以被重用。
- General Undo Segments 用于包含删除、更新等操作的事务,这类事务提交后,Undo Log 需要保留一段时间,直到不再有活跃事务需要访问这些旧版本。
- Undo Log 通常被组织成 Undo Segments,每一个 Undo Segment 包含一个或多个 Undo Records。Undo Segments 可以进一步分为两类:Insert Undo Segments 和 General Undo Segments。
- 重做记录(Undo Records):
- 每个 Undo Record 包含了数据项在某个时间点的值,以及指向其前后版本的指针。这样可以构建出一个版本链,用于追踪数据项的历史版本。
- 回滚指针(Rollback Pointer):
- 每个事务都有一个 Rollback Pointer 指向 Undo Log 中的一个位置,这个位置标识了事务开始时的数据状态。当事务需要回滚时,系统可以根据 Rollback Pointer 从该位置开始恢复数据到事务开始前的状态。
- 时间戳(Timestamps):
- Undo Log 中还包括时间戳信息,这有助于判断版本的有效性,特别是在 MVCC 环境下,用于决定哪个版本对于给定的查询是可见的。
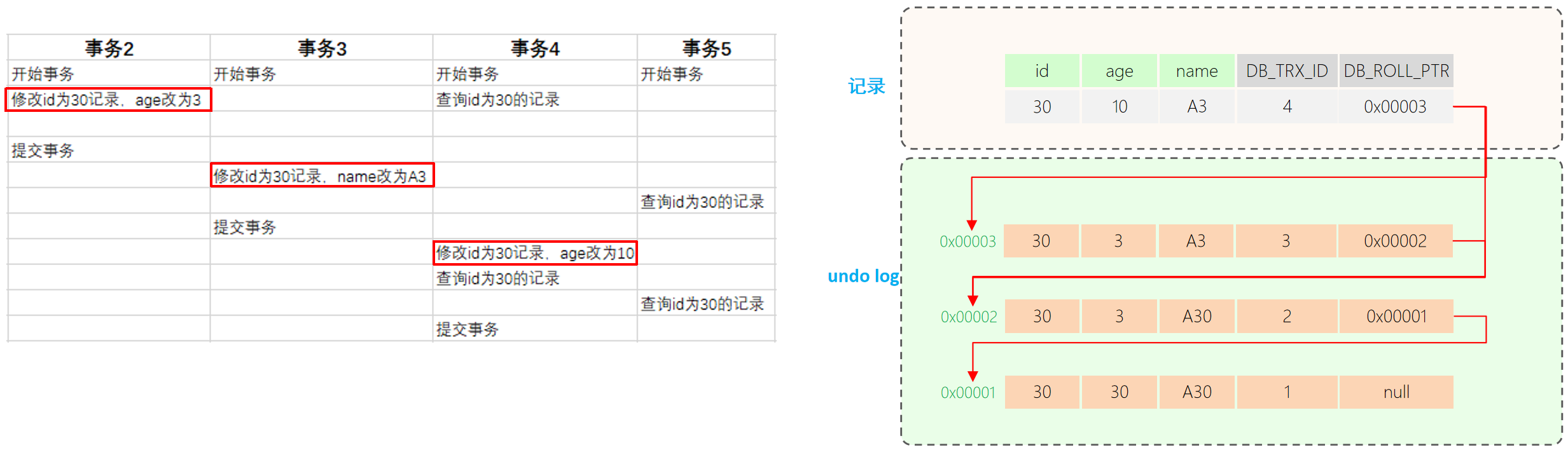
MVCC 实现一致性和隔离性的原理
MVCC机制下一条记录会有多个版本,每次修改记录都会存储这条记录被修改之前的版本。多版本之间串联起来就形成了一条版本链,这样不同时刻启动的事务可以无锁地获得不同版本的数据(普通读)。此时读(普通读)写操作不会阻塞,写操作可以继续写,无非就是多加了一个版本,历史版本记录可供已经启动的事务读取。
这一切的实现主要依赖于每条记录中的隐式字段、undo log日志、ReadView。
1. 隐式字段
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。 |
| (DB_ROW_ID) | (隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。) |
2. undo log
回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志。
undo log版本链:不同事务或相同事务对同一条记录进行修改,会导致该记录的undo log生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录
3. ReadView 读取视图
ReadView解决了一个事务查询选择版本的问题,根据ReadView的匹配规则和当前的一些事务id判断该访问那个版本的数据。
ReadView是一个事务在开始时可见的数据快照。每当一个事务启动时,系统会创建一个ReadView,记录当前活跃事务的列表和事务的时间戳。通过这个视图,事务可以访问在其开始时已经提交的版本,而忽略后续提交的变更。这确保了事务的隔离性,使得它在执行过程中看到的数据始终保持一致,避免了幻读和脏读问题。
不同的隔离级别快照读:RC(读已提交):每一次执行快照读时生成ReadView、RR(可重复读):仅在事务中第一次执行快照读时生成ReadView,后续复用。
工作过程:快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
当前读:写操作时(update、insert、delete(排他锁),select … lock in share mode(共享锁),select … for update),读取的是记录的最新版本,读取时会对读取的记录进行加锁,保证其他并发事务不能修改当前记录。
快照读:select时,非阻塞式地读取记录数据的可见版本,有可能是历史数据。
- Read Committed:每次执行select,都生成一个快照读,这个新生成的快照读可能会造成不可重复读。
- Repeatable Read(默认):仅在事务开始时生成ReadView,后续复用。
ReadView是一个数据结构,包含了四个核心字段:
字段 含义 m_ids 当前活跃的事务ID集合 min_trx_id 最小活跃事务ID max_trx_id 预分配的事务ID,当前最大事务ID+1 creator_trx_id ReadView创建者的事务ID
—————————————
分布式数据库
数据库集群
主从同步的原理
主从复制的核心就是二进制日志
主从复制步骤:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件Binlog中。
- 从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log。
- Slave重做中继日志中的事件,将改变反映它自己的数据。
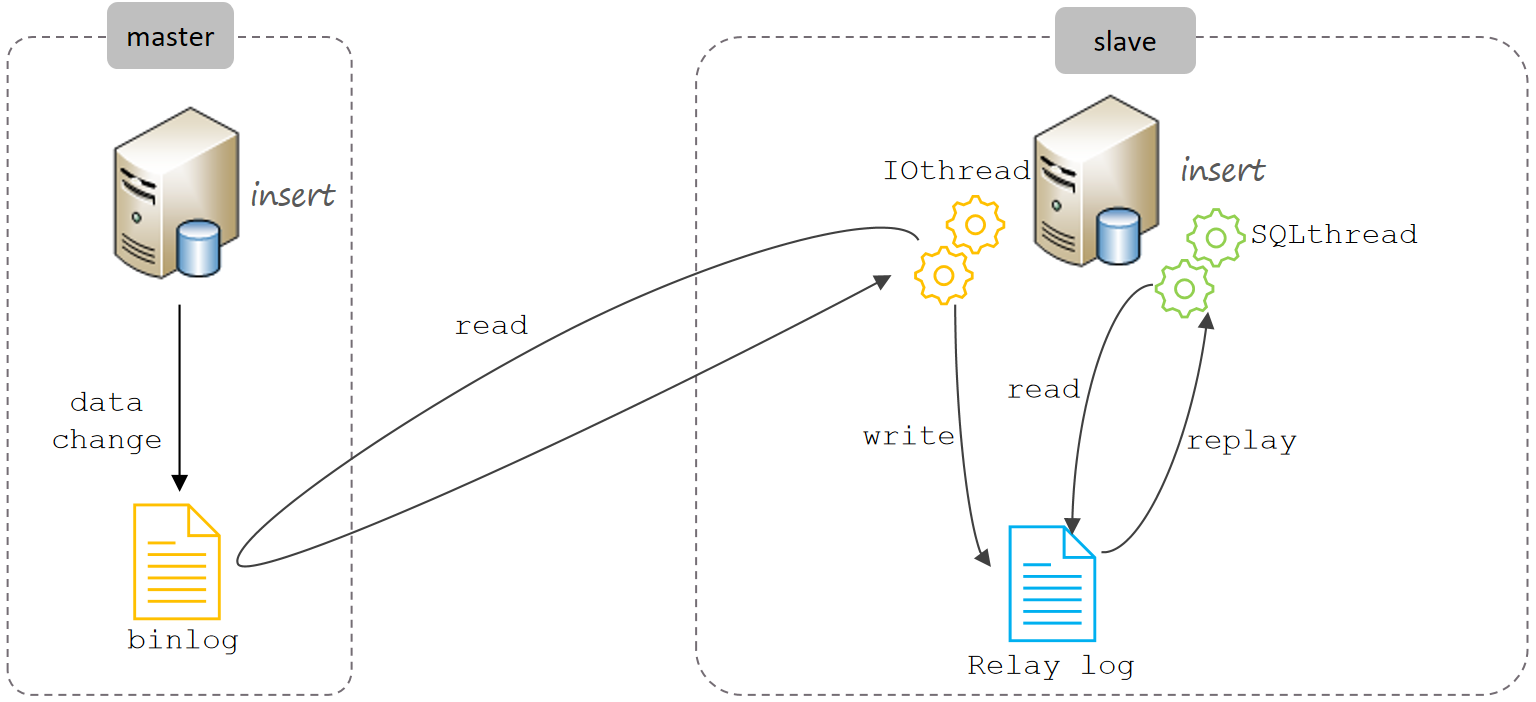
如何保证主从的数据一致性?
- 利用读写分离框架特性,如ShardingJDBC可以要求下一条SELECT强制走主库。但会增大主库压力,可能出现性能瓶颈。
- 采用MGR(MySQL Group Replication)全同步复制,强一致数据同步没完成主从同步之前,jdbc.insert()方法无法得到结果新项目推荐:无需改代码,真正的一致性方案,老项目不推荐,传统应用集群向MGR迁移成本高、风险大
分库分表时机
- 项目业务数据逐渐增多,或业务发展比较迅速
- 优化已解决不了性能问题(主从读写分离、查询索引…)
- IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)
分表分库策略
- 垂直分库,根据业务进行拆分,高并发下提高磁盘IO和网络连接数
- 垂直分表,冷热数据分离,多表互不影响
- 水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题
- 水平分表,解决单表存储和性能的问题
分库
分库(Database Sharding)是指将一个大的数据库拆分成多个小的数据库,每个数据库称为一个“分片”(Shard)。每个分片包含部分数据,通过某种策略将数据分布到不同的分片中。
分库策略
- 范围分片:根据某个字段的值范围进行分片,例如按用户 ID 的范围。
- 哈希分片:根据某个字段的哈希值进行分片,例如按用户 ID 的哈希值。
- 列表分片:根据某个字段的具体值进行分片,例如按城市名称。
分库的实现方式
- 应用层分片:在应用层实现分片逻辑,通过路由算法将请求分发到不同的数据库分片。
- 中间件分片:使用数据库中间件(如 MyCAT、ShardingSphere)来管理分片,提供透明的分片和路由功能。
优点、缺点
提高性能:通过将数据分散到多个数据库中,可以减少单个数据库的负载,提高查询和写入性能。
增加可伸缩性:可以轻松地通过增加更多的分片来扩展系统。
提高可用性:即使某个分片出现故障,其他分片仍然可以正常工作,提高了系统的可用性。
复杂性增加:需要管理多个数据库实例,增加了系统的复杂性。
跨分片查询:跨分片的查询和事务管理更加复杂,可能需要额外的中间件支持。
数据迁移:随着数据量的增长,可能需要重新分片,数据迁移和维护成本较高。
分表
分表(Table Partitioning)是指将一个大的表拆分成多个小的表,每个小表称为一个“分区”(Partition)。每个分区包含部分数据,通过某种策略将数据分布到不同的分区中。
分表策略
- 范围分区:根据某个字段的值范围进行分区,例如按日期范围。
- 列表分区:根据某个字段的具体值进行分区,例如按地区代码。
- 哈希分区:根据某个字段的哈希值进行分区,例如按用户 ID 的哈希值。
- 复合分区:结合多种分区策略,例如先按日期范围分区,再按地区代码分区。
分表的实现方式
- 物理分区:在数据库中创建多个物理表,每个表存储部分数据。
- 逻辑分区:使用数据库的分区功能(如 PostgreSQL 的表分区、MySQL 的分区表)来创建逻辑分区。
优点、缺点
提高查询性能:通过将数据分散到多个分区中,可以减少单个分区的数据量,提高查询性能。
优化存储:可以将冷数据和热数据分开存储,优化存储空间和访问效率。
简化维护:可以单独对某个分区进行维护操作,如备份、索引重建等。
复杂性增加:需要管理多个表分区,增加了系统的复杂性。
跨分区查询:跨分区的查询和事务管理更加复杂,可能需要额外的优化和索引支持。
分区管理:需要定期维护分区,例如添加新的分区、删除旧的分区等。
分片
分片(Database Sharding)涵盖了分库和分表的概念。分片是指将数据分散到多个节点或分区中,每个节点或分区包含部分数据,通过某种策略将数据分布到不同的节点或分区中。
分片的类型
- 水平分割:数据库分片是指将数据库中的数据水平地分割成多个部分,并将这些部分分布到不同的物理数据库服务器上。这意味着每台服务器上只存储一部分数据,而不是全部数据。
- 垂直分割:与水平分割相对的是垂直分割(Vertical Partitioning),即将不同的表分割到不同的服务器上。然而,垂直分割通常不是我们讨论的“分片”的主要内容,而是另一种优化策略。
分片的目的
- 提高性能:通过将数据分布在多个服务器上,可以并行处理更多的请求,从而提高整体性能。
- 负载均衡:分片可以将负载均衡到多个服务器上,避免单点过载。
- 提高可用性:如果一个分片服务器宕机,其他分片服务器仍然可以继续提供服务,提高了系统的可用性。
- 数据地理分布:分片还允许将数据存储在不同的地理位置,以减少延迟并满足数据驻留法规要求。
分片的实现方式
- 应用层分片:在应用层实现分片逻辑,通过路由算法将请求分发到不同的节点或分区。
- 中间件分片:使用数据库中间件(如 MyCAT、ShardingSphere)来管理分片,提供透明的分片和路由功能。
分片带来的挑战
- 数据一致性:在分布式环境中,保持数据的一致性是一个挑战,需要使用如分布式事务、分布式锁等技术来保证。
- 数据迁移:当需要增加或移除分片时,涉及到大量的数据迁移工作。
- 查询复杂性:跨分片的查询变得复杂,可能需要在多个分片上执行查询并合并结果。
- 故障恢复:分片系统需要设计有效的故障恢复机制,以确保在某个分片失效时系统仍然可以正常运行。
分库、分表、分片的示例
分库示例
假设你有一个电商系统,用户分布在不同的城市。可以按城市进行分库:
- 数据库1:北京用户
- 数据库2:上海用户
- 数据库3:广州用户
分表示例
假设你有一个订单表,订单数据按日期进行分表:
- 订单表1:2023年1月的数据
- 订单表2:2023年2月的数据
- 订单表3:2023年3月的数据
分片示例
假设你有一个全球用户系统,用户分布在不同的国家和地区。可以按国家和城市进行分片:
- 分片1:中国北京用户
- 分片2:中国上海用户
- 分片3:美国纽约用户
- 分片4:英国伦敦用户
总结
- 分库:适用于大规模数据和高并发场景,通过将数据分散到多个数据库中,提高系统的可伸缩性和性能。
- 分表:适用于单个表数据量过大的场景,通过将数据分散到多个表中,提高查询性能和存储效率。
- 分片:涵盖了分库和分表的概念,通过将数据分散到多个节点或分区中,提高系统的性能和可伸缩性。
怎么设计数据库分片?
分片键
确定分片键(Sharding Key),这将决定数据如何分配到不同分片。
常见的分片键包括:
- 用户ID:适用于社交网络、电子商务等场景。
- 地理位置:适用于需要根据地理位置存储数据的应用。
- 时间戳:适用于日志记录、历史数据存储等场景。
分片算法
根据选定的分片键,设计分片算法。
常见的分片算法包括:
范围分片:根据某个字段的值范围进行分片,例如按用户 ID 的范围。
- 数据根据某个字段(如用户ID)的值范围分配到不同的分片上。
- 优点是可以根据数据的自然分布来进行分片,易于理解和实现。
- 缺点是如果数据分布不均,可能导致某些分片负载过高。
哈希分片:根据某个字段的哈希值进行分片,例如按用户 ID 的哈希值。
- 数据根据一个或多个字段的哈希值分配到不同的分片上。
- 优点是哈希值的均匀分布可以较好地平衡各分片的负载。
- 缺点是当增加或移除分片时,需要重新哈希分配数据,可能导致大规模的数据迁移。
列表分片:根据某个字段的具体值进行分片,例如按城市名称。
复合分片:结合多种分片策略,例如先按日期范围分片,再按地区代码分片。
一致性哈希算法
一种特殊的哈希分片算法,用于解决哈希分片在动态调整分片数量时的问题。
通过虚拟节点来模拟环形拓扑结构,使得在添加或移除分片时,只需要重新分配受影响的数据部分。
如何保证数据的分布一致性?
数据映射规则
需要定义一个映射规则,将数据映射到具体的分片上。
例如,可以使用模运算来实现哈希分片:
1 | int shardId = userId.hashCode() % numberOfShards; |
分片存储
每个分片存储在不同的数据库实例上,需要确保每个实例上的数据是相互独立的。可以使用如下方法来实现:
- 使用不同的数据库实例:每个分片对应一个数据库实例。
- 使用同一个数据库实例的不同表或Schema:适合数据量不大,且对性能要求不高的场景。
如何保证分片数据的一致性?
分布式事务
分片后,跨分片的事务处理变得更加复杂。需要使用分布式事务来保证数据的一致性。常用的方法包括:
- 两阶段提交(Two-Phase Commit, 2PC):协调多个分片上的事务。
- 三阶段提交(Three-Phase Commit, 3PC):在2PC的基础上增加了预准备阶段,提高了可靠性。
- 最终一致性(Eventual Consistency):通过消息队列或事件驱动的方式,在事务完成后异步同步数据。
分布式锁
在并发场景下,需要使用分布式锁来保证数据的一致性。常用的技术包括:
- ZooKeeper:提供分布式锁服务。
- Redis:使用Redis的SETNX等命令实现分布式锁。
数据同步
对于需要实时同步的数据,可以使用以下方法:
- 主从复制(Master-Slave Replication):将数据从主分片复制到其他分片。
- 异步消息队列:使用Kafka、RabbitMQ等消息队列进行数据同步。
————————————
#缓存
缓存是一种用于提高数据访问速度和系统性能的技术。通过将频繁访问的数据存储在内存或其他快速访问介质中,缓存可以显著减少数据访问的延迟和减轻后端系统的负载。
常见的缓存类型
内存缓存
- Redis:一个高性能的键值存储系统,支持多种数据结构(如字符串、哈希、列表、集合等),广泛用于缓存和会话管理。
- Memcached:一个高性能的分布式内存对象缓存系统,主要用于加速动态Web应用程序。
文件缓存
- 本地文件系统:将数据缓存到本地文件系统中,适用于静态内容的缓存。
- 分布式文件系统:如 HDFS(Hadoop Distributed File System),用于大规模数据存储和缓存。
数据库缓存
- 查询缓存:数据库系统内部的缓存机制,用于缓存查询结果,减少对磁盘的访问。
- 结果集缓存:将查询结果缓存到内存中,减少对数据库的访问次数。
应用程序缓存
- 本地缓存:应用程序内部的缓存,通常使用 HashMap 或其他数据结构实现。
- 分布式缓存:使用分布式缓存系统(如 Redis、Memcached)在多个应用程序实例之间共享缓存数据。
更新策略
- 写穿策略:每次写操作都同时更新缓存和后端数据源。
- 读穿策略:每次读操作都先检查缓存,如果未命中则从后端数据源获取数据并更新缓存。
- 写回策略:写操作只更新缓存,定期或在某些条件下将缓存中的数据同步到后端数据源。
- 刷新策略:定期或在某些条件下清空缓存,强制从后端数据源重新加载数据。
失效策略
- 时间失效:设置缓存数据的有效时间,超过时间后自动失效。
- 容量失效:当缓存达到最大容量时,使用 LRU(最近最少使用)、LFU(最不经常使用)等算法移除一些数据。
- 显式失效:应用程序显式地从缓存中移除数据,通常在数据更新时使用。
应用场景
- 网页缓存:缓存静态内容(如 HTML、CSS、JavaScript 文件),减少服务器负载,提高页面加载速度。
- 数据库查询缓存:缓存数据库查询结果,减少对数据库的访问次数,提高查询性能。
- API 响应缓存:缓存 API 响应,减少后端服务的调用次数,提高 API 响应速度。
- 会话缓存:缓存用户会话信息,提高用户会话管理的性能。
- 全文搜索缓存:缓存搜索结果,提高搜索性能。
最佳实践
- 合理设置缓存时间:根据数据的更新频率和重要性,合理设置缓存的有效时间。
- 使用缓存预热:在系统启动或高峰期前,预先加载常用数据到缓存中。
- 缓存降级:在缓存失效或不可用时,提供合理的降级策略,确保系统仍能正常运行。
- 监控和告警:监控缓存系统的状态,设置告警机制,及时发现和处理问题。
- 数据一致性管理:使用合理的缓存更新和失效策略,确保缓存数据和后端数据源的一致性。
优点、缺点
提高性能:通过减少对后端系统的访问次数,提高数据访问速度和系统性能。
减轻负载:减少后端系统的负载,提高系统的可用性和稳定性。
提高用户体验:加快数据访问速度,提升用户的使用体验。
节省资源:减少对计算和网络资源的消耗,降低运营成本。
数据一致性问题:缓存数据和后端数据源之间的数据一致性难以保证,可能导致数据不一致的问题。
复杂性增加:引入缓存机制会增加系统的复杂性,需要管理和维护缓存系统。
内存占用:缓存数据占用内存,如果管理不当可能导致内存溢出等问题。
缓存击穿:大量请求同时访问同一个缓存数据,导致缓存失效后的瞬间大量请求涌入后端系统,造成后端系统压力过大。
多级缓存架构
缓存是提升性能最直接的方法 多级缓存分为:客户端,应用层,服务层,数据层
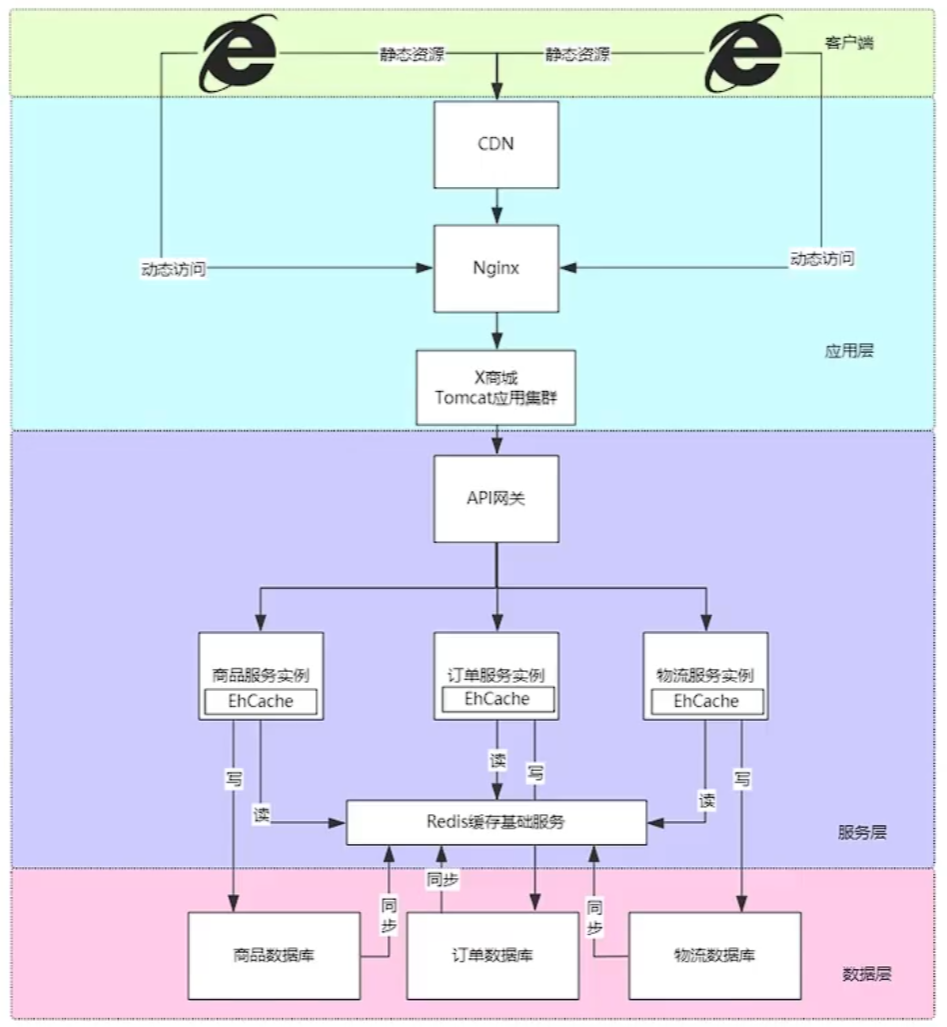
客户端缓存
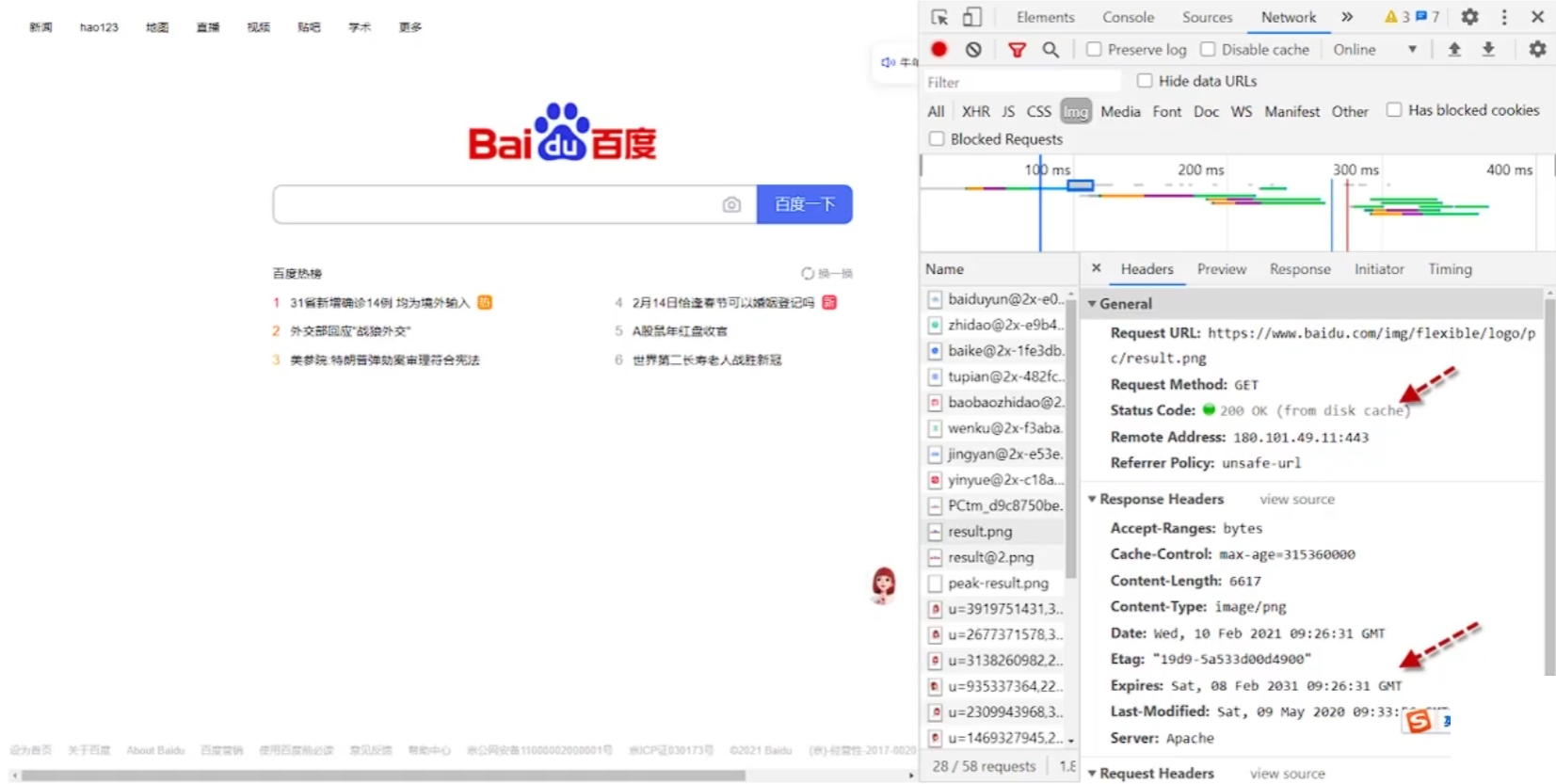
客户端缓存:主要对浏览器的静态资源进行缓存 通过在浏览器设置Expires,时间段内以文件形式把图片保存在本地,减少多次请求静态资源带来的带宽损耗(解决并发手段) 。
例如:百度的logo,可以给logo设置一个过期时间,第一次请求时缓存logo图片和过期时间,之后每次请求时都查看过期时间,如果还没过期就从磁盘读取。
应用层缓存
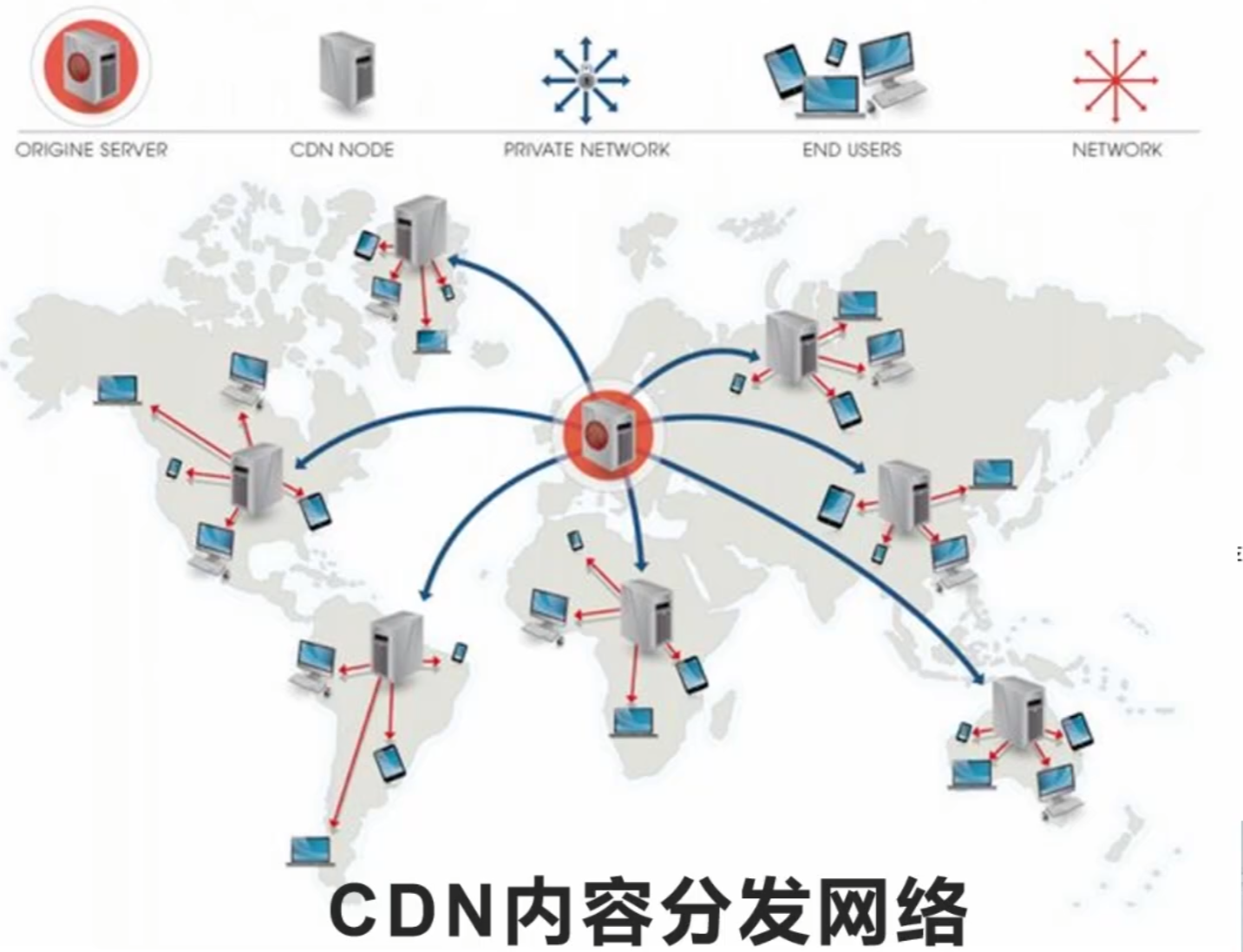
CDN(重量级)
CDN内容分发网络是静态资源分发的主要技术手段,有效解决带宽集中占用以及数据分发问。
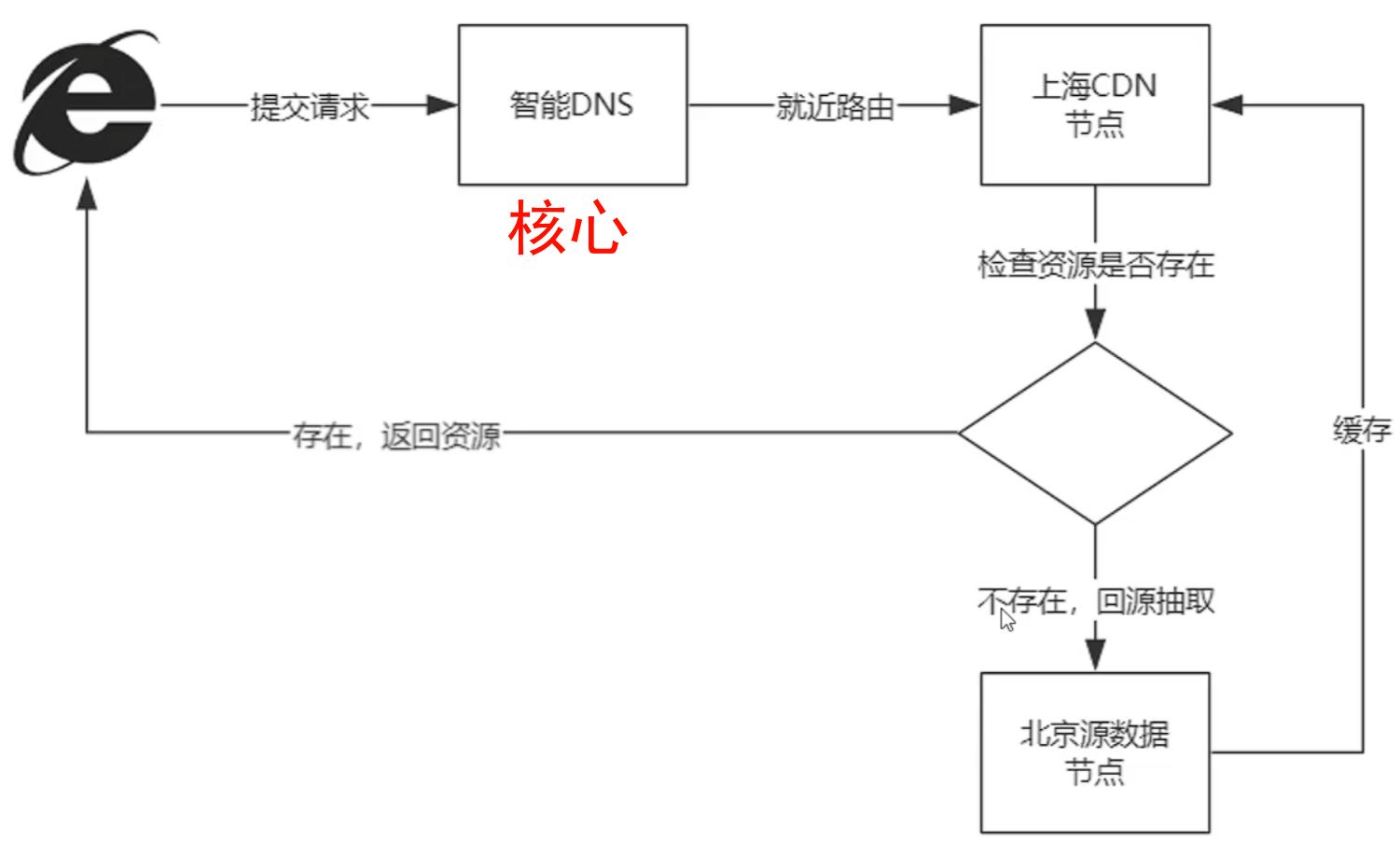
CDN是一项基础设施,一般由云服务厂商提供。
CDN的核心技术: 根据请求访问DNS节点, 自动转发到就近CDN节点,检查资源是否被缓存,若已缓存则返回资源否则回源数据节点提取,并缓存到就近CDN节点,再由就近CDN节点进行返回。
CDN的使用(aliyun):
响应头Expires和Cache-control的区别:
- 均为通知浏览器进行文件缓存
Expires指在缓存的过期时间Cache-control指缓存的有效期
响应头的设置:Expires 设置时间,Cache-Control 设置时长。
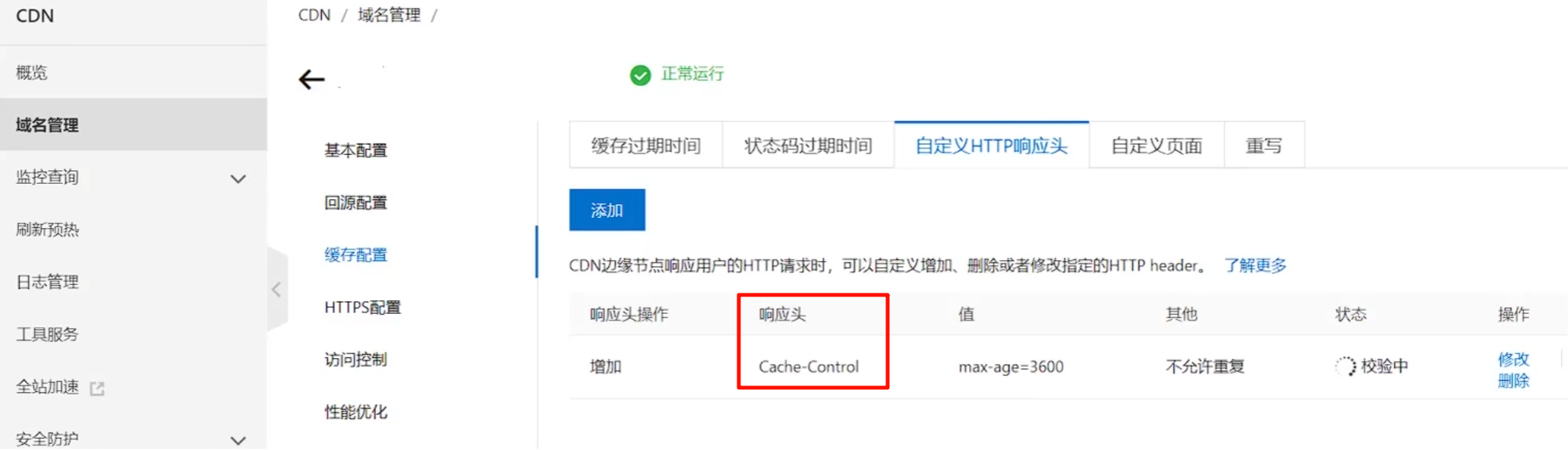
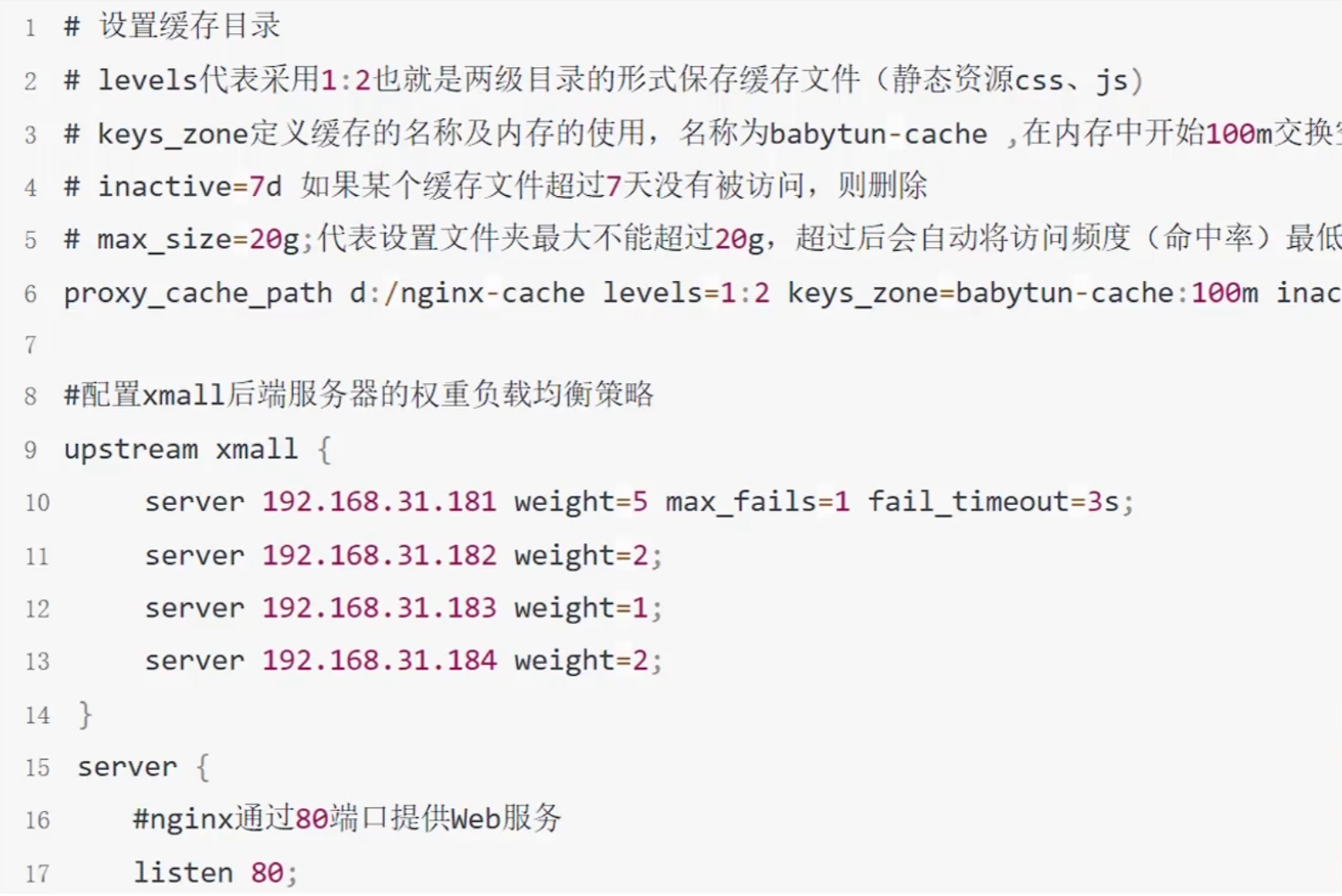
Nginx(轻量级)
Nginx对Tomcat集群做软负载均衡,提供高可用性。有静态资源缓存和压缩功能(在本地缓存文件)
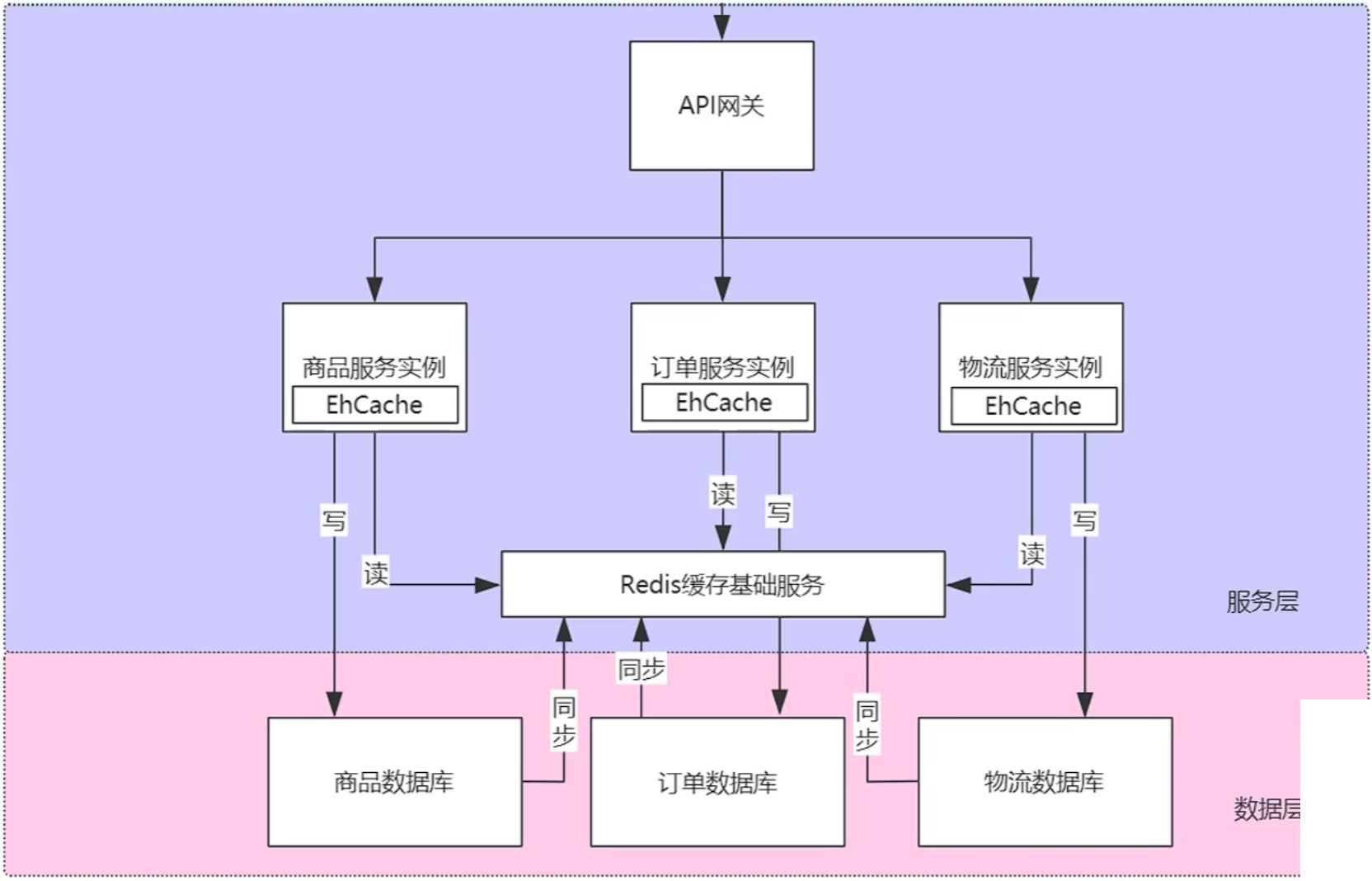
服务层缓存
服务层缓存:进程内缓存和进程外缓存
- 进程内缓存:在应用程序的内存中,数据运行时载入程序开辟的缓存,存储在应用程序进程内部,访问速度非常快,因为它不需要通过网络或其他进程间通信机制来访问数据。
- 开源实现:HashMap、EhCache、Caffeine、Hibernate一二级缓存、Mybatis一二级缓存,SpringMVC页面缓存
- 进程外缓存:独立于应用程序运行,存储在应用程序进程之外的缓存系统,具备更好的持久性、更高的并发性和更好的伸缩性。进程外缓存可以跨越多个服务器,提供分布式的服务,从而支持更大规模的应用程序。
- 开源实现:Redis、Memcached、Ignite、Hazelcast、Voldemort
数据层缓存
第一种情况,缓存的数据是稳定的。例如:邮政编码、地域区块、归档数据……
第二种情况,瞬时可能会产生极高并发的场景。例如:股市开盘、商品秒杀……
第三种情况,一定程度上允许数据不一致。例如:网站公告……
一种数据同步方案:
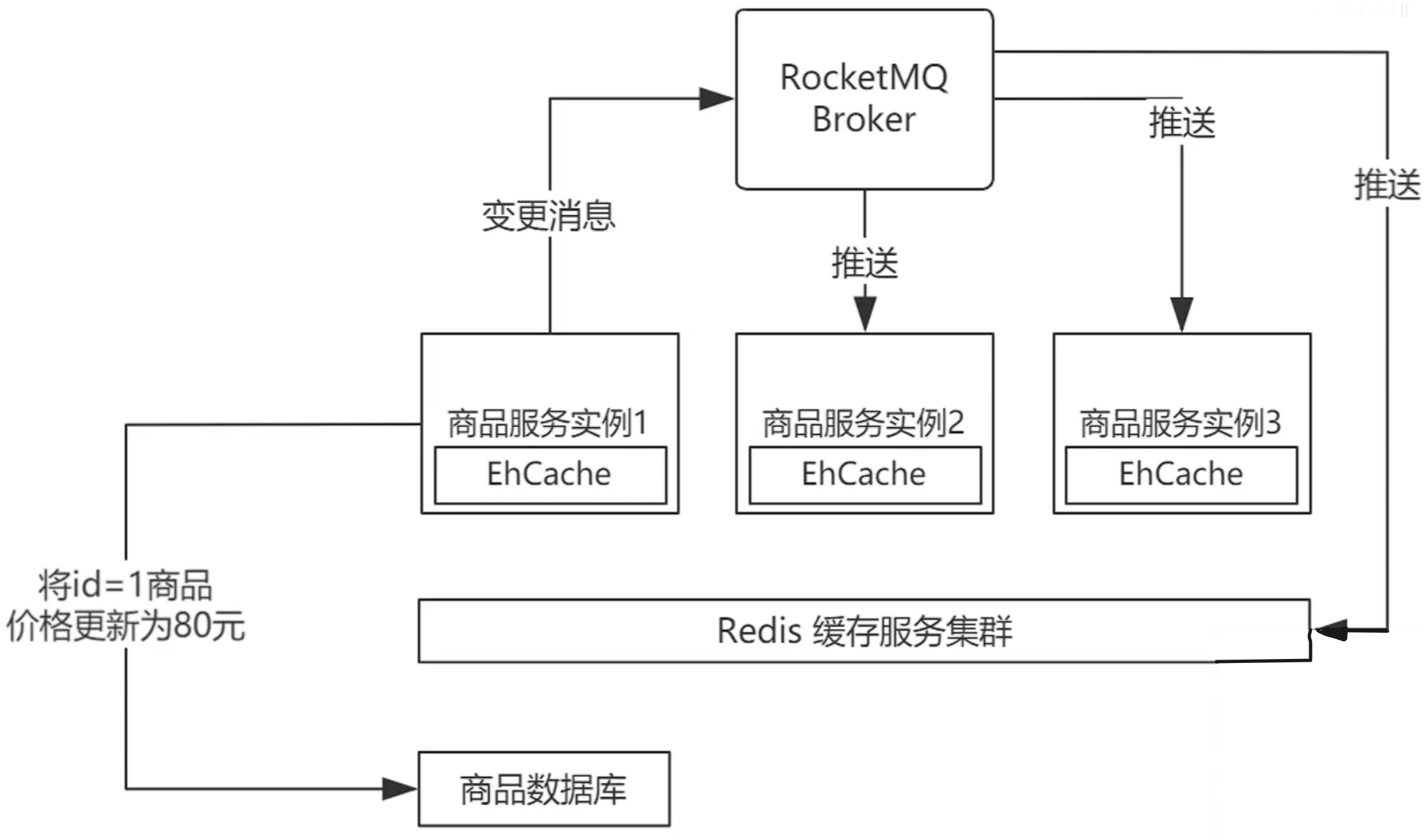
进程外缓存(SpringCache)
只适合单体项目,遇到分布式,一碰就碎!纯FW!
SpringCache
Spring Cache 是 Spring 框架提供的一个抽象层,用于简化缓存的使用。它提供了一种声明式的方式,在方法调用时自动管理缓存。
特点:
- 声明式缓存:通过注解(如
@Cacheable、@CachePut、@CacheEvict)来管理缓存,无需手动编写缓存逻辑。 - 多种缓存提供商支持:支持多种缓存提供商,如 Redis、Caffeine、EhCache 等。
- 灵活的缓存策略:可以通过配置文件或注解来定义缓存策略,如缓存键生成、缓存失效等。
Caffeine
Caffeine 专注于本地缓存,继承了 Google Guava 缓存的优点,并进行了优化,提供了更好的性能和灵活性。
特点:
- 高性能:使用高效的并发数据结构和算法,提供极高的吞吐量和低延迟。
- 自动内存管理:支持自动清除未使用的缓存项,避免内存泄漏。
- 丰富的缓存策略:支持多种缓存策略,如 LRU(最近最少使用)、LFU(最不经常使用)、TTL(生存时间)等。
EhCache
EhCache 支持本地缓存和分布式缓存,广泛应用于各种企业级应用中,提供高性能的缓存解决方案。
特点:
- 本地缓存:支持内存和磁盘存储,可以灵活配置缓存策略。
- 分布式缓存:支持多种分布式缓存模式,如 RMI、JGroups、Terracotta 等。
- 丰富的配置选项:提供详细的配置选项,如缓存大小、缓存过期时间、缓存策略等。
- 集成广泛:可以与多种框架和工具集成,如 Spring、Hibernate、MyBatis 等。
对比
| 特性/功能 | Caffeine | EhCache |
|---|---|---|
| 类型 | 本地缓存 | 本地缓存 + 分布式缓存 |
| 缓存提供商 | 本地缓存 | 本地缓存 + 分布式缓存 |
| 性能 | 高性能 | 高性能 |
| 配置方式 | 代码 + 配置文件 | 配置文件 |
| 缓存策略 | 多种策略(LRU、LFU、TTL等) | 多种策略(LRU、LFU、TTL等) |
| 集成 | 易于与 Spring 集成 | 广泛集成(Spring、Hibernate等) |
| 分布式支持 | 不支持分布式缓存 | 支持多种分布式缓存模式 |
| 内存管理 | 自动内存管理 | 手动配置内存管理 |
总结
- Caffeine:高性能的本地缓存库,适合对性能要求较高的场景,特别是单机应用。
- EhCache:支持本地缓存和分布式缓存,适合需要分布式缓存支持的企业级应用。
进程内缓存(Redis)
缓存的使用场景
缓存:穿透、击穿、雪崩、双写一致、持久化、数据过期策略,数据淘汰策略
分布式锁:setnx、redisson
消息队列、延迟队列
常见数据类型的应用场景
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
Redis 的I/O多路复用模型
简单来说有以下几个原因:
- 完全基于内存的,C语言编写
- 采用单线程,避免不必要的上下文切换可竞争条件
- 使用多路I/O复用模型,非阻塞IO
例如:bgsave 和 bgrewriteaof 都是在后台执行操作,不影响主线程的正常使用,不会产生阻塞
详细的说有以下几个原因
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
I/O多路复用是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/O多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能。
I/O多路复用模型是Redis的网络模型,它结合事件的处理器来应对多个Socket请求,比如,提供了连接应答处理器、命令回复处理器,命令请求处理器;
在Redis6.0之后,为了提升更好的性能,在命令回复处理器使用了多线程来处理回复事件,在命令请求处理器中,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程
Redis 的两种数据持久化
RDB(Redis Database Backup file:Redis数据备份文件)
RDB:是一个二进制的快照文件,它是把Redis内存存储的数据写到磁盘上,当Redis实例宕机恢复数据的时候,方便从RDB的快照文件中恢复数据
开启RDB:在redis.conf文件中找到,格式如下:
1
2
3save 900 1 # 900秒内,如果至少有1个key被修改,则执行bgsave
save 300 10 # 原理同上
save 60 10000 # 原理同上RDB执行原理:bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
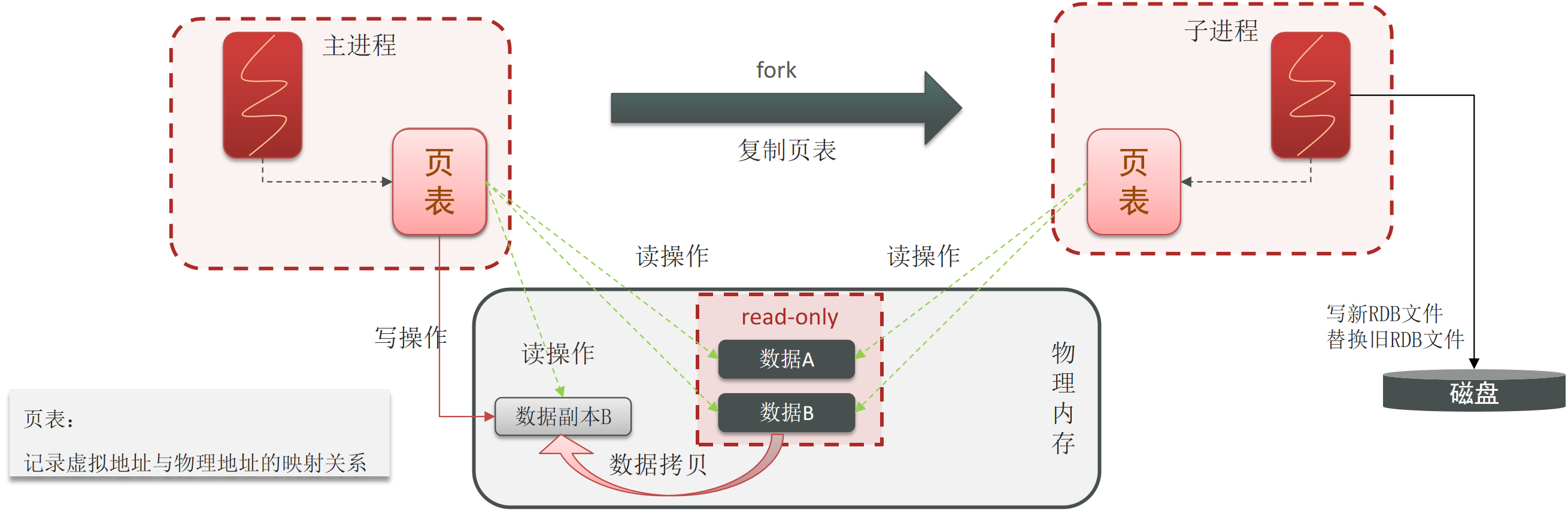
AOF(Append Only File:追加文件)
AOF:Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件
开启AOF:
1
2
3
4# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"修改AOF的记录频率:
1
2
3
4
5
6# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no配置项 刷盘时机 优点 缺点 always 同步刷盘 可靠性高,几乎不丢数据 性能影响大 everysec 每秒刷盘 性能适中 最多丢失1秒数据 no 操作系统控制 性能最好 可靠性较差,可能丢失大量数据 修改AOF的自动去重写阈值:
1
2
3
4
5
6# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync noRDB与AOF对比:
** ** RDB AOF 持久化方式 定时对整个内存做快照 记录每一次执行的命令 数据完整性 不完整,两次备份之间会丢失 相对完整,取决于刷盘策略 文件大小 会有压缩,文件体积小 记录命令,文件体积很大 宕机恢复速度 很快 慢 数据恢复优先级 低,因为数据完整性不如AOF 高,因为数据完整性更高 系统资源占用 高,大量CPU和内存消耗 低,主要是磁盘IO资源但AOF重写时会占用大量CPU和内存资源 使用场景 可以容忍数分钟的数据丢失,追求更快的启动速度 对数据安全性要求较高常见
Redis 的 Pipeline 功能是什么?
pipeline(管道)使得客户端可以一次性将要执行的多条命令封装成块一起发送给服务端
优点:
- 减少网络往返次数:
- Pipeline 可以将多次网络往返减少为一次,显著提高了执行效率。
- 提高吞吐量:
- 对于批量操作,使用 Pipeline 可以显著提高吞吐量,尤其是在高延迟网络环境中。
- 简化代码逻辑:
- 对于批量操作,使用 Pipeline 可以简化客户端代码,避免频繁地打开和关闭连接。
缓存的常见问题
缓存穿透
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
解决方案:
- 缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存(简单,但是消耗内存,且可能会发生不一致的问题)
- 布隆过滤器(内存占用较少,没有多余key,但是实现复杂,存在误判)
布隆过滤器原理:布隆过滤器是一个以(bit)位为单位的很长的数组,数组中每个单元只能存储二进制数0或1。当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样一来,三个数组的位置就能标明一个key的存在。
布隆过滤器在项目中的使用流程:
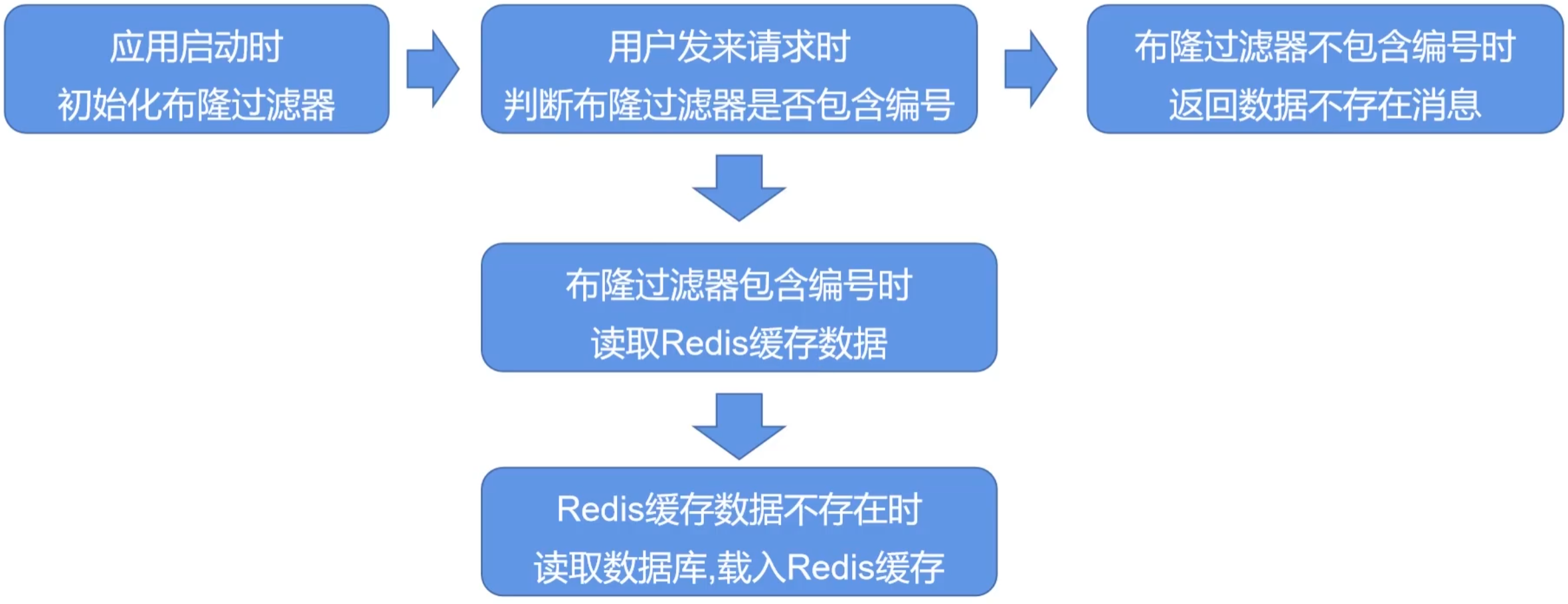
如果数据被删除了怎么办?1). 定时异步重建布隆过滤器;2). 换用“计数型布隆过滤器”
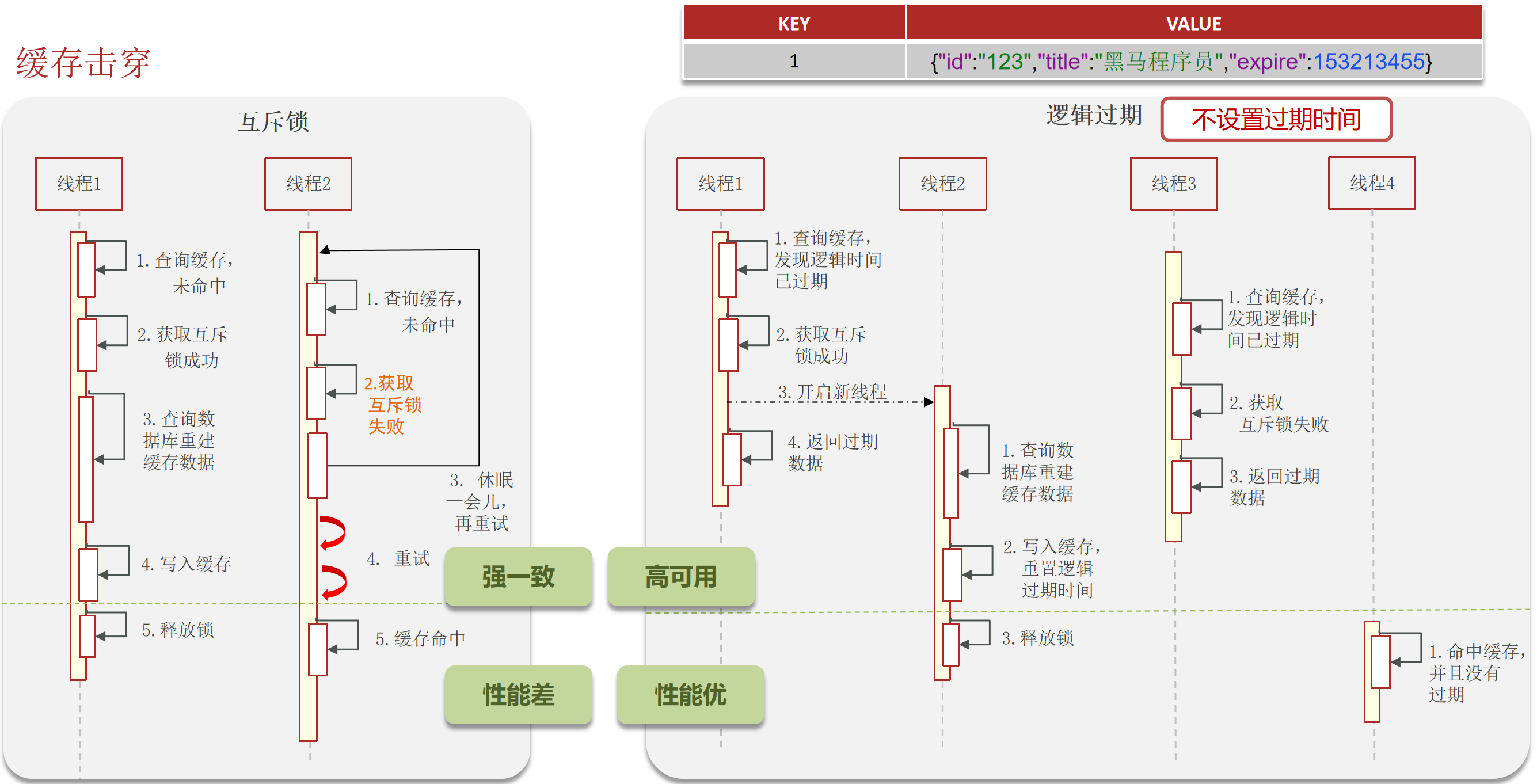
缓存击穿
缓存击穿:key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
解决方案:
- 互斥锁(强一致性,但是性能差)
- 逻辑过期(高可用性、性能优,但是有一致性问题)
缓存雪崩
缓存雪崩:是指在同一时段大量的缓存key同时效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性(哨兵模式、集群模式)
- 给缓存业务添加降级限流策略(ngxin或spring cloud gateway)
- 给业务添加多级缓存(Guava或Caffeine)
大Key问题
什么是 大 key?
- String 类型的值大于 10 KB;
- Hash、List、Set、ZSet 类型的元素的个数超过 5000个;
大 key 带来的问题
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
如何找到大 key ?
1、–bigkeys 查找大key
可以通过 redis-cli –bigkeys 命令查找大 key:
1 | redis-cli -h 127.0.0.1 -p 6379 |
使用的时候注意事项:
- 最好选择在从节点上执行该命令。因为主节点上执行时,会阻塞主节点;
- 如果没有从节点,那么可以选择在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用 -i 参数控制扫描间隔,避免长时间扫描降低 Redis 实例的性能。
该方式的不足之处:
- 这个方法只能返回每种类型中最大的那个 bigkey,无法得到大小排在前 N 位的 bigkey;
- 对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大;
2、使用 SCAN 命令查找大 key
使用 SCAN 命令对数据库扫描,然后用 TYPE 命令获取返回的每一个 key 的类型。
对于 String 类型,可以直接使用 STRLEN 命令获取字符串的长度,也就是占用的内存空间字节数。
对于集合类型来说,有两种方法可以获得它占用的内存大小:
- 如果能够预先从业务层知道集合元素的平均大小,那么,可以使用下面的命令获取集合元素的个数,然后乘以集合元素的平均大小,这样就能获得集合占用的内存大小了。List 类型:
LLEN命令;Hash 类型:HLEN命令;Set 类型:SCARD命令;Sorted Set 类型:ZCARD命令; - 如果不能提前知道写入集合的元素大小,可以使用
MEMORY USAGE命令(需要 Redis 4.0 及以上版本),查询一个键值对占用的内存空间。
3、使用 RdbTools 工具查找大 key
使用 RdbTools 第三方开源工具,可以用来解析 Redis 快照(RDB)文件,找到其中的大 key。
比如,下面这条命令,将大于 10 kb 的 key 输出到一个表格文件。
1 | rdb dump.rdb -c memory --bytes 10240 -f redis.csv |
数据一致性问题
先删除缓存,还是先修改数据库?
先修改数据库,再删除缓存
- 原子性:数据库操作通常是原子的,这意味着它可以作为一个单一的工作单元执行,要么完全成功,要么完全失败。因此,先修改数据库可以确保数据的一致性。
- 降低脏读的风险:如果在修改数据库之前删除了缓存,那么在缓存被重新填充之前,其他请求可能会读取到旧的(或脏)数据。
- 简化逻辑:通常,在修改数据库后,删除缓存是一个简单的操作,因为缓存中的条目可以通过其键来直接定位。
先删除缓存,再修改数据库,再删除一遍缓存
- 降低延迟:在某些场景中,先删除缓存可以减少缓存与数据库之间的数据不一致时间,因为一旦缓存被删除,后续请求将直接从数据库读取数据。
- 避免并发问题(一致性):在某些高并发的场景下,如果先修改数据库再删除缓存,可能会出现一个请求A修改数据库但还未删除缓存,此时另一个请求B读取到旧的缓存数据并基于旧数据进行了某些操作,然后请求A删除了缓存,此时如果请求B的数据操作依赖于最新的数据库数据,就可能出现问题。
数据一致性的组件、设计
组件:
- 使用Canal实现数据同步:不更改业务代码,部署一个Canal服务。Canal服务把自己伪装成MySQL的一个从节点,当MySQL数据更新以后,Canal会读取bin log数据,然后在通过Canal的客户端获取到数据,更新缓存即可。
- 采用Redisson实现读写锁,在读的时候添加共享锁,可以保证共享读操作,互斥读写操作。当更新数据的时候,添加排他锁,互斥读写和读操作,确保在写数据的避免读脏数据。
设计:
- 同步双写:实时性较好,实现简单,但是需要改造大量程序。
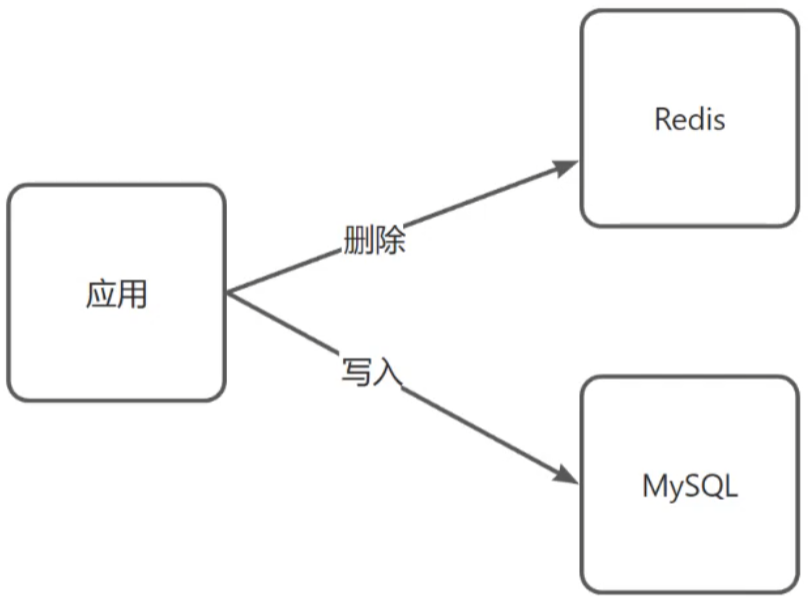
- 基于MQ异步多写:适合分布式场景,耦合低,延迟取决于MQ的消费速度。
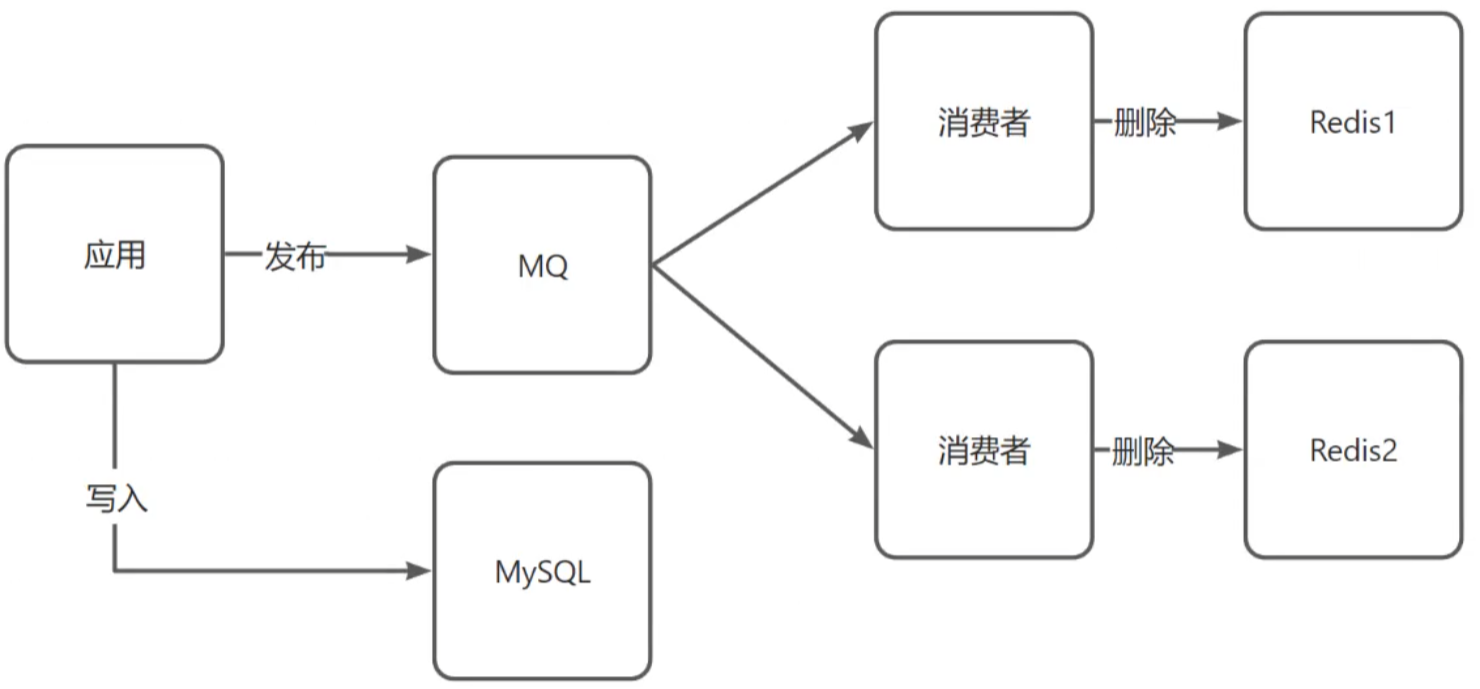
- 定时任务:效率最高,但是延迟最高。需要业务表中设计一个last-update字段。
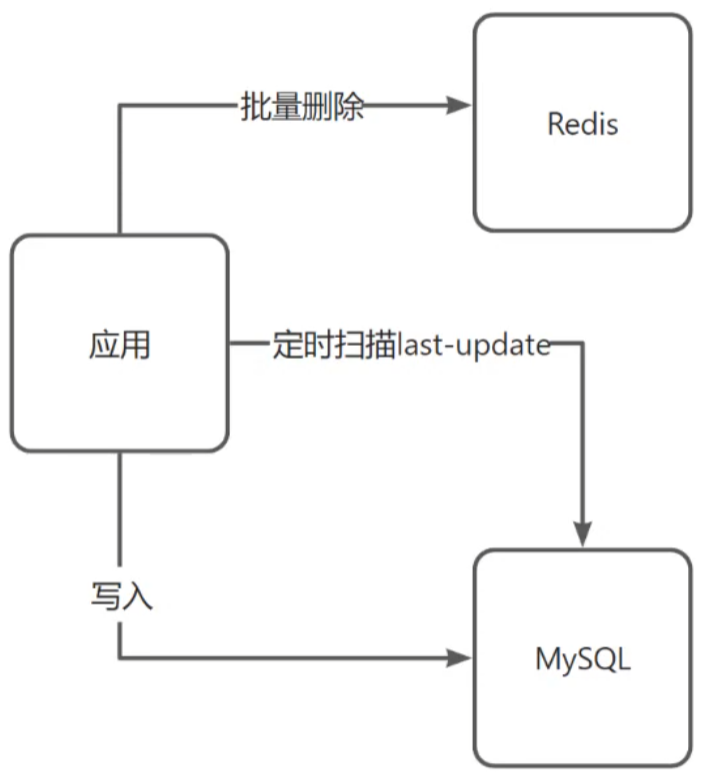
- 闪电缓存:实现最简单,不需要对缓存进行管理,但会加大数据库的压力。
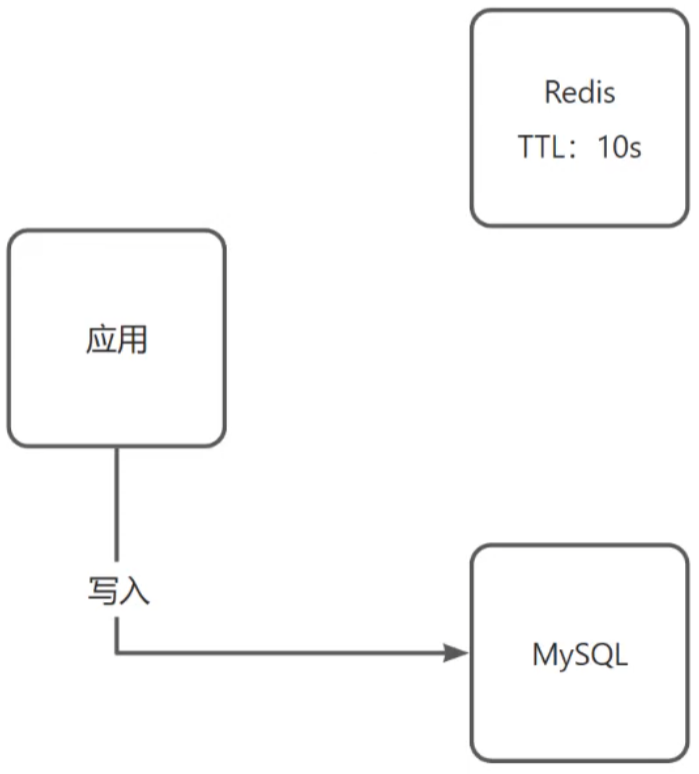
- binlog监听:让Flink-CDC伪装成slave,通过监听数据库二进制日志(Binlog)来实现对缓存的同步更新。
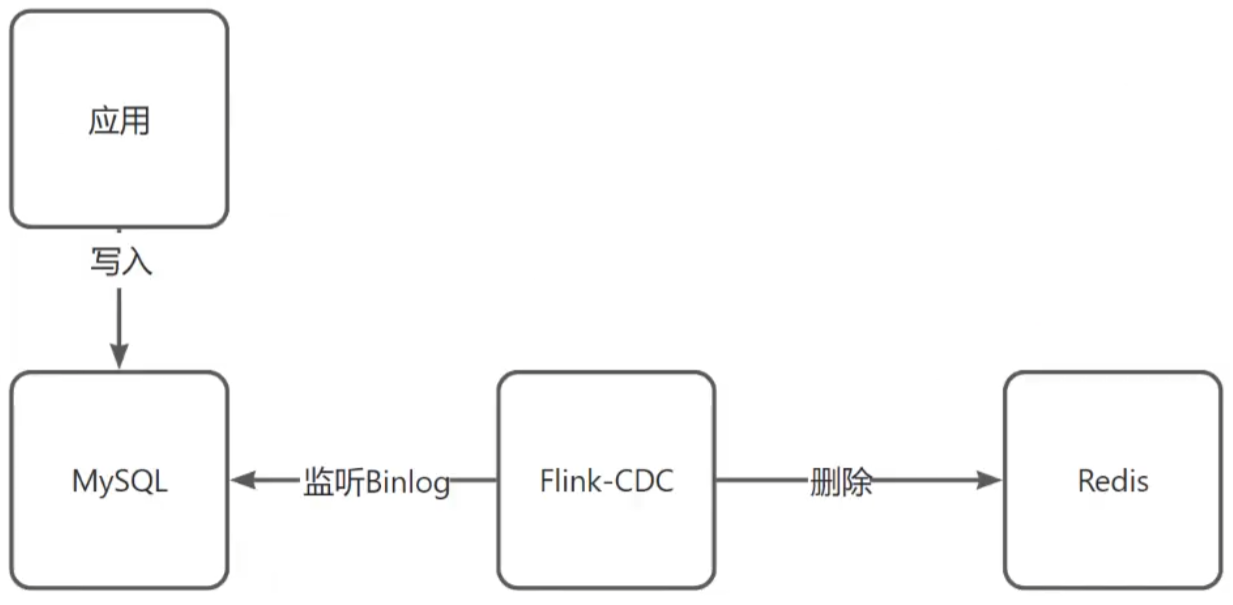
数据删除策略
惰性删除,在设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
定期删除,就是说每隔一段时间,我们就对一些key进行检查,删除里面过期的key。
定期清理的两种模式:
- SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的 hz 选项来调整这个次数。
- FAST模式执行频率不固定,每次事件循环会尝试执行,但两次间隔不低于2ms,每次耗时不超过1ms。
数据淘汰策略
- noeviction(默认): 不淘汰任何key,但是内存满时不允许写入新数据。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰。
- allkeys-random:对全体key ,随机进行淘汰。
- volatile-random:对设置了TTL的key ,随机进行淘汰。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
LRU(Least Recently Used):最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU(Least Frequently Used):最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
数据淘汰策略-使用建议:
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random ,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
保证热点数据可以使用 allkeys-lru (挑选最近最少使用的数据淘汰)淘汰策略,那留下来的都是经常访问的热点数据
缓存更新策略
- Cache Aside(旁路缓存)策略;
- Read/Write Through(读穿 / 写穿)策略;(仅存在于理论中)
- Write Back(写回)策略;(仅存在于理论中)
实际开发中,Redis 和 MySQL 的更新策略用的是 Cache Aside,另外两种策略应用不了。
Cache Aside(旁路缓存)策略
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。
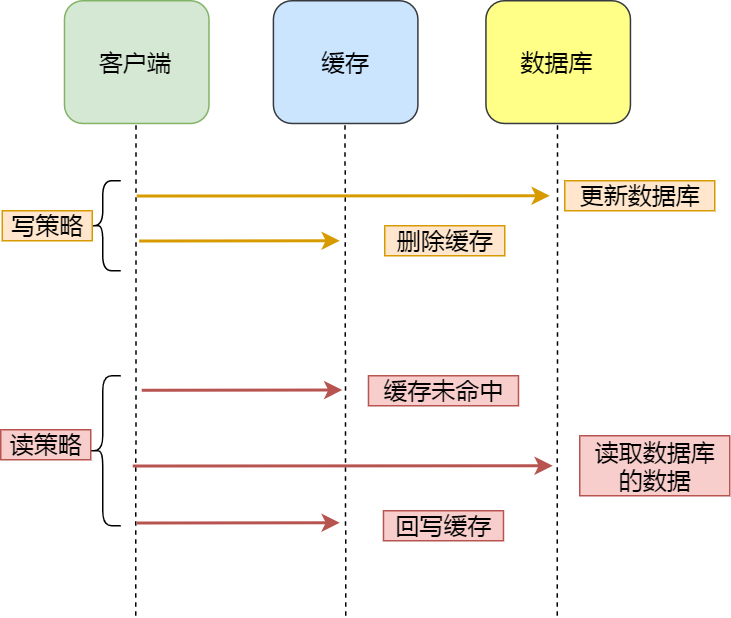
Read/Write Through(读穿 / 写穿)策略
Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
1、Read Through 策略
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
2、Write Through 策略
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
- 如果缓存中数据已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,然后缓存组件告知应用程序更新完成。
- 如果缓存中数据不存在,直接更新数据库,然后返回;
下面是 Read Through/Write Through 策略的示意图:
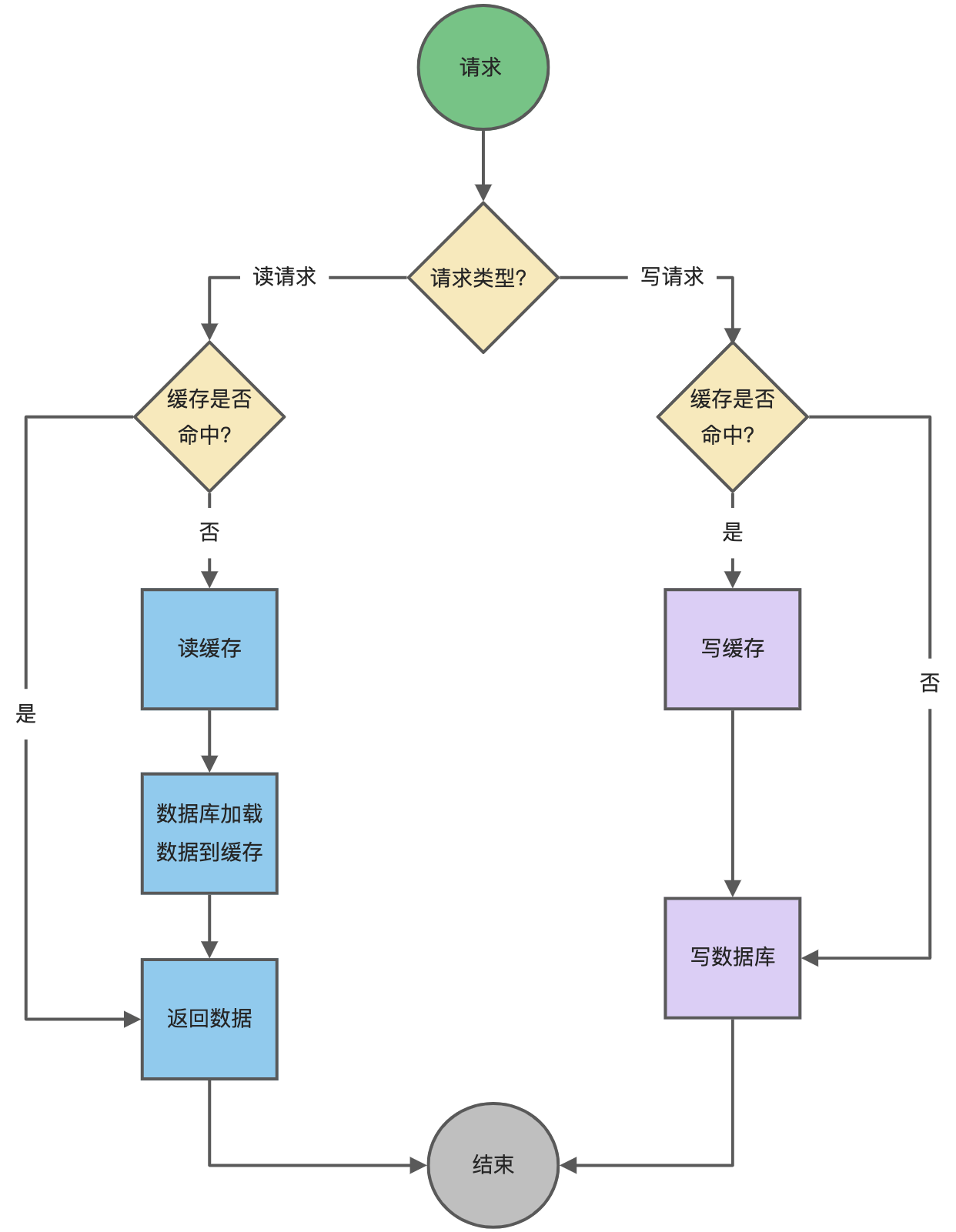
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
Write Back(写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
实际上,Write Back(写回)策略也不能应用到我们常用的数据库和缓存的场景中,因为 Redis 并没有异步更新数据库的功能。
Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作系统中文件系统的缓存都采用了 Write Back(写回)策略。
Write Back 策略特别适合写多的场景,因为发生写操作的时候, 只需要更新缓存,就立马返回了。比如,写文件的时候,实际上是写入到文件系统的缓存就返回了,并不会写磁盘。
但是带来的问题是,数据不是强一致性的,而且会有数据丢失的风险,因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
这里贴一张 CPU 缓存与内存使用 Write Back 策略的流程图:
—————————————
分布式缓存
分布式集群中的概念
Raft选举算法
Raft算法是一种流行的分布式一致性算法,它旨在简化 Paxos 算法的理解和实现。
Raft 的优势:易于理解、分布式强一致性
Raft算法将节点分为三种状态:跟随者(Follower)、候选人(Candidate)和领导者(Leader)。
Raft 算法的主要步骤:
- 初始化状态:
- 每个节点初始状态都是跟随者(Follower)。
- 超时事件:
- 当跟随者没有在一定时间内接收到任何消息时(随机超时时间),它会变成候选人(Candidate)。
- 选举过程:
- 候选人发起选举,向其他节点发送投票请求(RequestVote RPC)。
- 其他节点接收到投票请求后,如果它们尚未投票给其他候选人,则可以投票给当前候选人。
- 如果候选人获得大多数节点的选票,则成为领导者(Leader)。
- 领导者的心跳机制:
- 领导者定期向所有节点发送心跳消息(AppendEntries RPC),以维持领导者的地位。
- 如果跟随者长时间未收到心跳消息,它会再次变成候选人并重新发起选举。
主从同步

主从同步:单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中
主从同步数据的流程:
全量同步:从节点第一次与主节点建立连接的时候会使用全量同步

- 从节点请求主节点同步数据,其中从节点会携带自己的replication id和offset偏移量。
- 主节点判断是否是第一次请求,主要判断的依据就是,主节点与从节点是否是同一个replication id,如果不是,就说明是第一次同步,那主节点就会把自己的replication id和offset发送给从节点,让从节点与主节点的信息保持一致
- 在同时主节点会执行bgsave,生成rdb文件后,发送给从节点去执行,从节点先把自己的数据清空,然后执行主节点发送过来的rdb文件,这样就保持了一致
当然,如果在rdb生成执行期间,依然有请求到了主节点,而主节点会以命令的方式记录到缓冲区,缓冲区是一个日志文件,最后把这个日志文件发送给从节点,这样就能保证主节点与从节点完全一致了,后期再同步数据的时候,都是依赖于这个日志文件,这个就是全量同步
增量同步:当从节点服务重启之后,数据就不一致了,所以这个时候,从节点会请求主节点同步数据,主节点还是判断不是第一次请求,不是第一次就获取从节点的offset值,然后主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步

哨兵模式
通过一组哨兵(通常是几个 Redis 实例)来监控多个 Redis 主从实例的运行状态,并在主实例发生故障时,自动完成故障转移。
哨兵机制的主要功能包括:
监控(Monitoring):哨兵会定期检查主节点(Master)和从节点(Slave),以及其他哨兵的状态。每个哨兵节点会定时向所有的 Master、Slave 以及其他的 Sentinel 发送 PING 命令来检查它们的健康状况。此外,哨兵也可以监控任意给定的函数,并在条件满足时触发动作。
故障转移(Failure Detection and Automatic Failover):当主节点失效时,哨兵能够自动将其中一个从节点升级为主节点,从而实现自动故障转移。这一过程涉及到哨兵之间的协商,确保只有一个哨兵进行实际的故障转移操作。哨兵之间使用 Raft 或类似的协议来达成一致,以防止脑裂(split-brain)情况的发生。
通知(Notification):在故障转移之后,哨兵会通知客户端新的主节点的位置。此外,哨兵还可以通过订阅与发布(PUB/SUB)机制来发送其他通知信息。
配置中心(Configuration Provider):哨兵充当了 Redis 集群的配置中心的角色。客户端可以通过哨兵获取当前集群的状态,包括主节点的位置等信息。
哨兵机制的关键概念
- 主观下线(Subjective Down):当一个哨兵认为一个主节点或从节点已经下线时,它会标记该节点为主观下线状态。
- 客观下线(Objective Down):当足够数量的哨兵(根据配置文件中的多数原则)同意一个节点已经下线时,该节点就会被标记为客观下线状态。此时,哨兵就可以开始故障转移的过程。
哨兵的工作流程
- 哨兵检测:每个哨兵节点独立地监控 Redis 主节点和从节点的健康状况。
- 共识形成:当多个哨兵确认主节点已经失效后,它们会通过共识算法(如 Raft)选出一个领导哨兵来进行故障转移。
- 故障转移:领导哨兵将从节点转换为主节点,并更新相关的从节点和客户端的配置信息。
- 通知客户端:哨兵通知客户端新的主节点的位置,使客户端可以继续正常工作。
分片集群
分片集群有什么作用?分片集群中数据是怎么存储和读取的?
分片集群主要解决的是海量数据存储的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,类似于哨兵模式。客户端请求可以访问集群任意节点,最终都会被转发到正确节点、
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽,集群中每个主节点绑定了一定范围的哈希槽范围, key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,通过槽找到对应的节点进行存储。
脑裂
由于网络等原因可能会出现脑裂的情况,master节点与sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到master,所以通过选举的方式提升了一个salve为master,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在old master那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将old master降为salve,这时再从新master同步数据,这会导致old master中的大量数据丢失。
解决方案:
- 设置尽量少的salve节点个数,比如设置至少要有一个从节点才能同步数据
- 设置主从同步的延迟超时时间,达不到要求就拒绝请求,就可以避免大量的数据丢失。
分布式锁
常见分布式锁
互斥锁、排他锁、可重入锁:锁的基本思想
读写锁:互斥锁的扩充
同步锁:本质就是互斥锁
表锁、行锁、间隙锁:数据库中的互斥锁
共享锁:数据库中的读写锁
排他锁:互斥锁的别名
悲观锁、乐观锁:一种抽象概念
分布式锁:分布式场景下的互斥锁
分布式锁有哪些应用场景?会发生什么问题?
有两种常见场景:
电商超卖
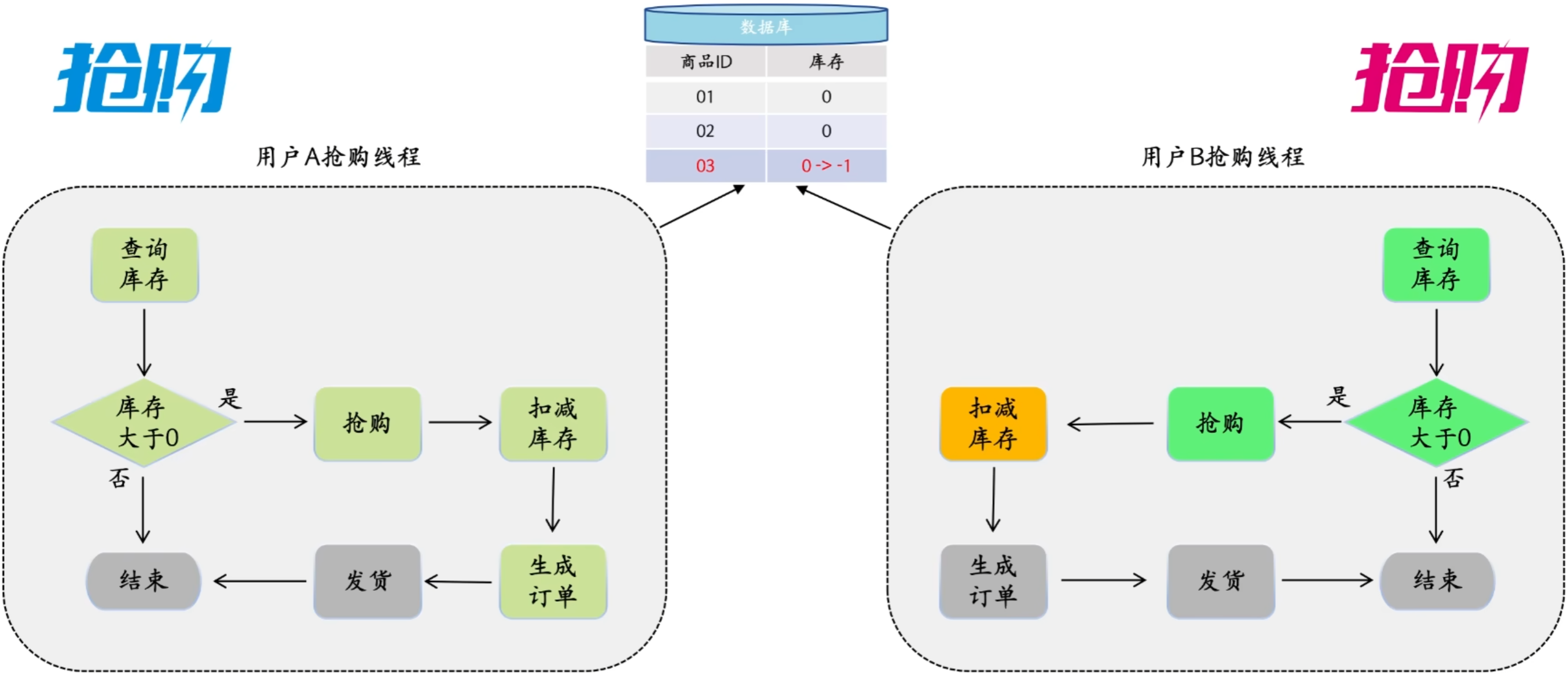
假脱机打印问题
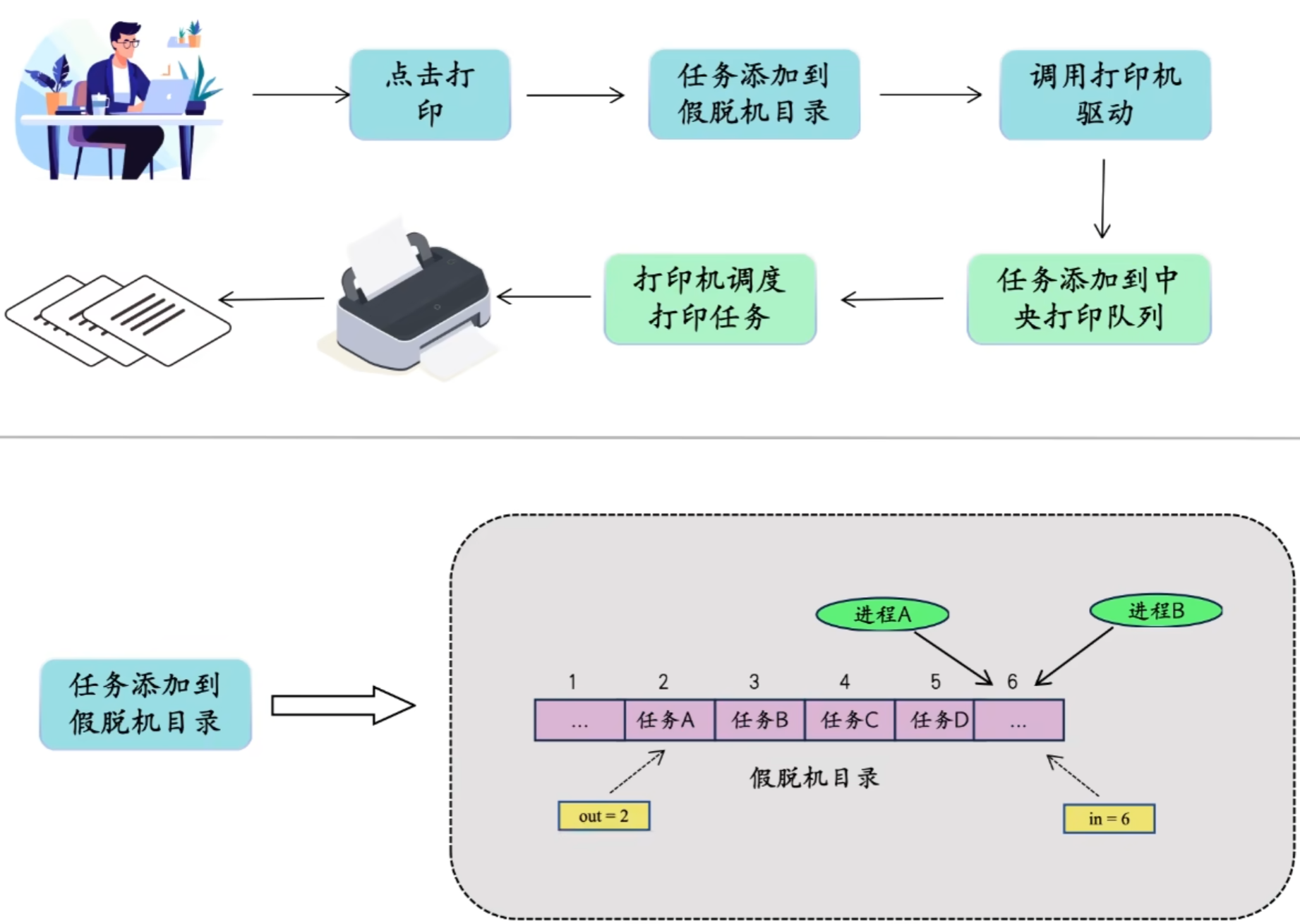
产生原因:多个执行体操作同一份共享数据。
在并发场景中,在需要操作同一个共享数据时,如果当前的进程或线程对数据的操作还没有结束的话,另一个进程或线程也开始操作这个数据,这个时候就会发生无法预测的结果。解决这个问题的一种思路就是:我们可以控制执行体的时序,在当前的这个执行体对共享数据的操作完成前,不允许其他的执行体去操作这个共享数据。具体我们可以设置一个公共的标记,这个标记对每个执行体都可见,当这个标记不可见的时候,执行体可以重新设置这个标记,这个标记就是锁,对于解决多线程、多进程、分布式服务同时竞争共享资源所产生的一系列问题思想都是加锁。
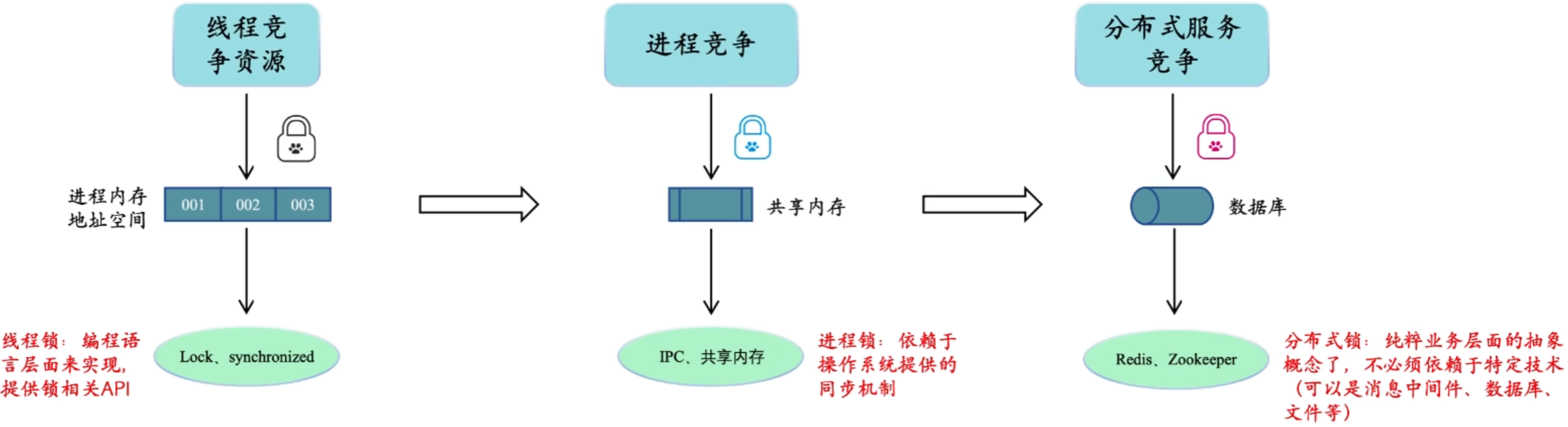
分布式锁的实现原理
加锁:使用SETNX命令设置一个键值对,如果键不存在则设置成功并获得锁
1
SET lock_key "lock_value" NX EX 30
获取锁
1
2
3
4WATCH lock_key
MULTI
SET lock_key "lock_value" NX EX 30
EXEC释放锁:删除该键值对
1
2
3
4
5
6
7EVAL "
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
" SHA 1 lock_key lock_value
实现细节
- 超时时间:设置一个合理的超时时间很重要,过长会导致资源浪费,过短可能导致锁的丢失。
- 重试机制:如果获取锁失败,客户端应该实现一个重试机制,并且在重试之间加入适当的延时,以避免争用。
- 公平性:上述实现并没有保证锁的获取公平性。如果需要公平锁,可以考虑在获取锁时加入时间戳或其他机制。
- 使用唯一标识符(如UUID)作为值,防止误删其他客户端的锁
- 考虑Redis主从复制的延迟问题,使用Redlock算法
分布式锁可能遇到的问题有哪些?
锁超时
- 锁未能正确释放、锁长时间不被释放,合理设置锁的超时时间;
- 锁频繁续期,合理设置锁的超时时间。
锁重试
- 锁被争用,导致性能下降,可以适当延长重试间隔时间。
- 锁因网络延迟等原因,无法及时获取或释放锁,可以在超时前多次尝试获取锁。
锁验证
- 锁被争用,是不公平的,使用时间戳机制实现公平锁。
- 锁被删除时验证锁的所有者,使用 Lua 脚本或UUID检查并删除锁。
Redisson的看门狗机制
作用:避免死锁。
实现原理:当锁住的一个业务还没有执行完成的时候,Redisson每隔一段时间就检查当前业务是否还持有锁,如果持有就增加加锁的持有时间,当业务执行完成之后需要使用释放锁就可以了。
—————————————
Spring
Spring、Spring MVC 和 Spring Boot 有什么区别
Spring
Spring 是一个 IoC(Inversion of Control,控制反转)容器,主要用于管理 Bean。通过依赖注入(Dependency Injection, DI)的方式实现控制反转,使得应用程序组件之间的依赖关系更加清晰,同时也便于测试和维护。Spring 提供了 AOP(Aspect Oriented Programming,面向切面编程)机制来解决 OOP(Object-Oriented Programming,面向对象编程)中代码重复的问题,允许开发者将不同类和方法中的共同处理逻辑(如日志记录、事务管理等)抽象成为切面,并自动注入到方法执行过程中。
Spring MVC
Spring MVC 是 Spring 对 Web 应用程序开发提供的一个解决方案。它引入了一个前端控制器 Servlet,负责接收 HTTP 请求。Spring MVC 定义了一套路由策略,用于将 URL 映射到具体的处理器(Handler)。前端控制器根据路由信息调用相应的处理器,并将处理器的返回结果通过视图解析器转换为最终的 HTML 页面呈现给用户。
Spring Boot
Spring Boot 是 Spring 社区提供的一个快速应用开发框架,旨在简化 Spring 应用程序的搭建和开发过程。它通过提供一系列默认配置,减少了开发者手动配置的时间,并且通过 Starter 机制整合了常用的第三方库和技术栈(如 Redis、MongoDB、Elasticsearch 等),使得开发者能够开箱即用地使用这些技术。Spring Boot 的目标是让开发者能够专注于业务逻辑的编写,而不是繁琐的配置工作。
延迟加载是什么?实现原理是什么?
延迟加载:查询一个实体类的时候,暂时不查询将其一对多的数据,当需要的时候,再查询,这就是延迟加载。
作用:提高响应速度、避免资源浪费。
实现原理:
- 使用CGLIB创建目标对象的代理对象
- 当调用目标方法时,进入拦截器invoke方法,发现目标方法是null值,执行sql查询
- 获取数据以后,调用set方法设置属性值,再继续查询目标方法,就有值了
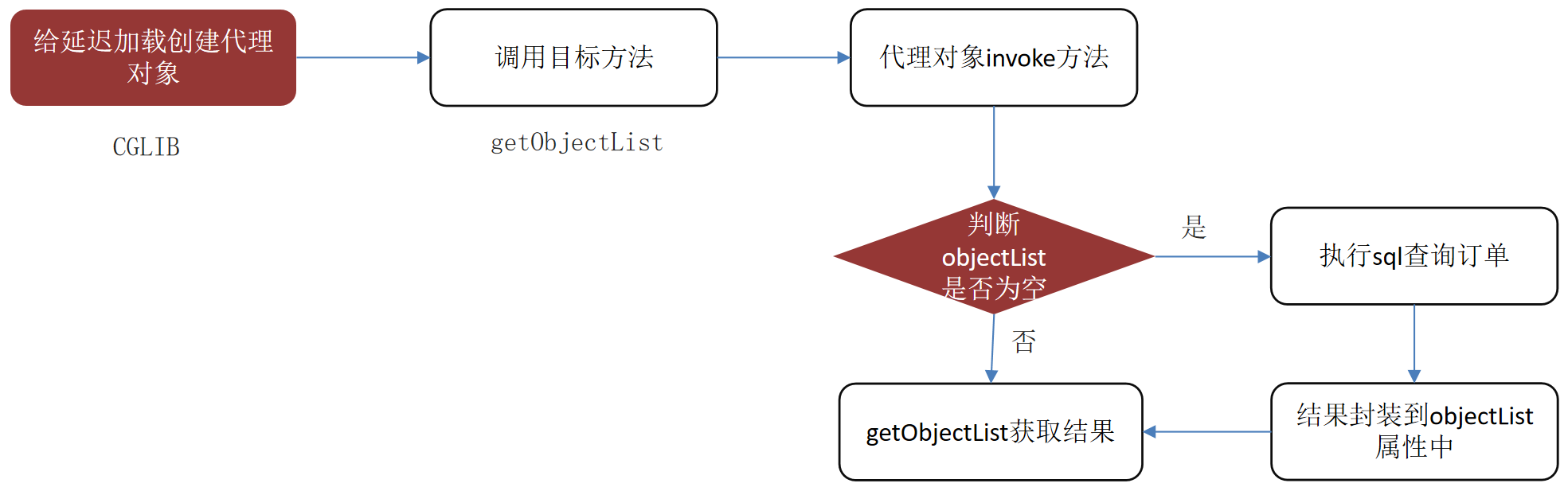
开启方式:开启方式由具体的框架决定。
常见注解
Spring注解
| 注解 | 说明 |
|---|---|
| @Component、@Controller、@Service、@Repository | 使用在类上用于实例化Bean |
| @Autowired | 使用在字段上用于根据类型依赖注入 |
| @Qualifier | 结合@Autowired一起使用用于根据名称进行依赖注入 |
| @Scope | 标注Bean的作用范围 |
| @Configuration | 指定当前类是一个 Spring 配置类,当创建容器时会从该类上加载注解 |
| @ComponentScan | 用于指定 Spring 在初始化容器时要扫描的包 |
| @Bean | 使用在方法上,标注将该方法的返回值存储到Spring容器中 |
| @Import | 使用@Import导入的类会被Spring加载到IOC容器中 |
| @Aspect、@Before、@After、@Around、@Pointcut | 用于切面编程(AOP) |
SpringMVC注解
| 注解 | 说明 |
|---|---|
| @RequestMapping | 用于映射请求路径,可以定义在类上和方法上。用于类上,则表示类中的所有的方法都是以该地址作为父路径 |
| @RequestBody | 注解实现接收http请求的json数据,将json转换为java对象 |
| @RequestParam | 指定请求参数的名称 |
| @PathViriable | 从请求路径下中获取请求参数(/user/{id}),传递给方法的形式参数 |
| @ResponseBody | 注解实现将controller方法返回对象转化为json对象响应给客户端 |
| @RequestHeader | 获取指定的请求头数据 |
| @RestController | @Controller + @ResponseBody |
Springboot注解
| 注解 | 说明 |
|---|---|
| @SpringBootConfiguration | 组合了- @Configuration注解,实现配置文件的功能 |
| @EnableAutoConfiguration | 打开自动配置的功能,也可以关闭某个自动配置的选 |
| @ComponentScan | Spring组件扫描 |
Bean
Bean的生命周期
Spring 中 Bean 的生命周期大致分为四个阶段:
- 实例化(Instantiation)
- 属性赋值(Populate)
- 初始化(Initialization)
- 销毁(Destruction)
Bean 生命周期大致分为 Bean 定义、Bean 的初始化、Bean的生存期和 Bean 的销毁4个部分。具体步骤如下:
- 通过BeanDefinition获取bean的定义信息
- 调用构造函数实例化bean
- bean的依赖注入
- 处理Aware接口(BeanNameAware、BeanFactoryAware、ApplicationContextAware)
- Bean的后置处理器BeanPostProcessor#before
- 初始化方法(InitializingBean、init-method)
- Bean的后置处理器BeanPostProcessor#before
- 销毁bean
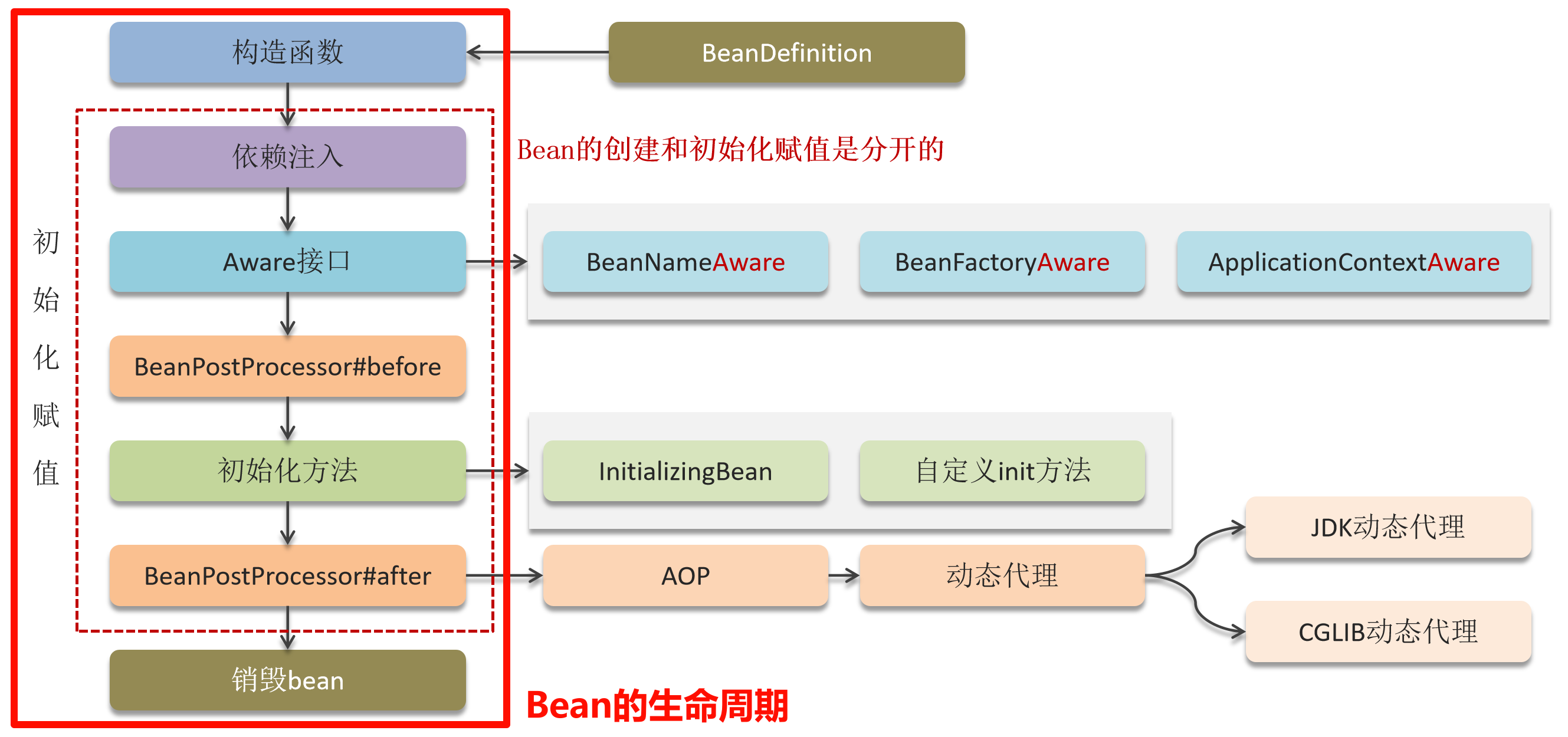
创建Bean的三种方式
定义 Bean 对象
1 | public class Orders implements BeanNameAware, BeanFactoryAware, ApplicationContextAware, InitializingBean { |
定义 BeanPostProcessor 后置处理器
1 |
|
1. 基于注解的方式
1 |
|
1 | public class Main { |
2. 基于配置文件的方式
1 |
|
1 | public class Main { |
3. 基于 BeanDefinition 编程方式
区别在于 Bean 的消息不是由 xml配置文件 定义,而是由 BeanDefinition 定义
1 | public class Main { |
Bean的生命周期哪些地方可以干预?
Bean的生命周期是由Spring容器自动管理的,其中有两个环节我们可以进行干预。
- 可以自定义初始化方法,增加
@PostConstruct注解,会在调用SetBeanFactory方法之后调用该方法。 - 可以自定义销毁方法,增加
@PreDestroy注解,会在自身销毁前调用这个方法。
Bean线程安全吗?如何解决线程不安全的Bean?
Bean不一定是线程安全的。
如果注入的对象是无状态的(String类),不需要线程安全问题的;
如果在bean中定义了可修改的变量,需要考虑线程安全问题。
解决方案:
- 使用多例。
- 使用加锁。
- 使用
@Scope注解,默认为singleton,改为prototype。
循环依赖及其解决办法
循环依赖:有多个类被Spring管理,它们在实例化时互相持有对方,最终形成闭环。

示例代码:
1 |
|
解决做法:先创建 A,此时的 A 是不完整的(没有注入 B),用个 map 保存这个不完整的 A,再创建 B ,B 需要 A,所以从那个 map 得到“不完整”的 A,此时的 B 就完整了,然后 A 就可以注入 B,然后 A 就完整了,B 也完整了,且它们是相互依赖的。
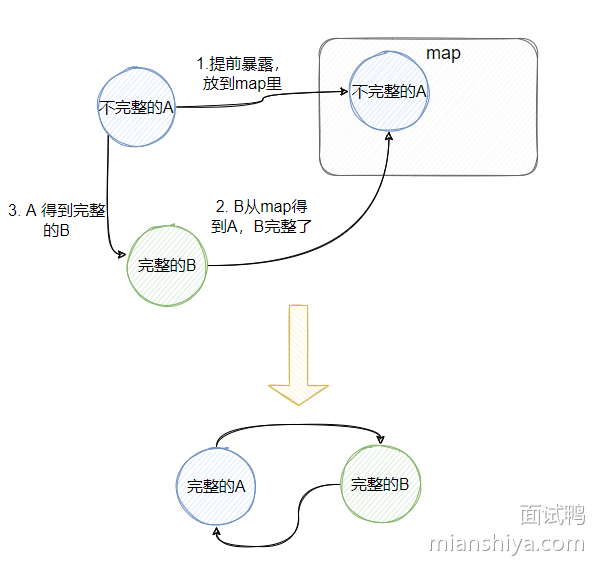
关键就是提前暴露未完全创建完毕的 Bean。
在 Spring 中,只有同时满足以下两点才能解决循环依赖的问题:
- 依赖的 Bean 必须都是单例
- 依赖注入的方式,必须不全是构造器注入,且 beanName 字母序在前的不能是构造器注入
Spring无法解决构造方法上出现的循环依赖,补救措施:在构造方法的参数上使用@Lazy。
非构造方法Spring通过三级缓存解决循环依赖:
Spring为单例搞的三个 map,也就是三级依赖:

| 缓存名称 | 源码名称 | 返回结果 | 作用 |
|---|---|---|---|
| 一级缓存 | singletonObjects | 存储所有已创建完毕的单例 Bean (完整的 Bean) | 单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象,只实现了singleton scope,解决不了循环依赖 |
| 二级缓存 | earlySingletonObjects | 存储所有仅完成实例化,但还未进行属性注入和初始化的 Bean | 缓存早期的bean对象(生命周期还没走完) |
| 三级缓存 | singletonFactories | 存储能建立这个 Bean 的一个工厂,通过工厂能获取这个 Bean,延迟化 Bean 的生成,工厂生成的 Bean 会塞入二级缓存 | 缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的 |
三级缓存的工作过程:
- 创建bean实例
- 将创建的bean实例放入三级缓存
- 填充属性
- 如果发现循环依赖,尝试从三级缓存中获取
- 没有循环依赖,将bean放入一级缓存
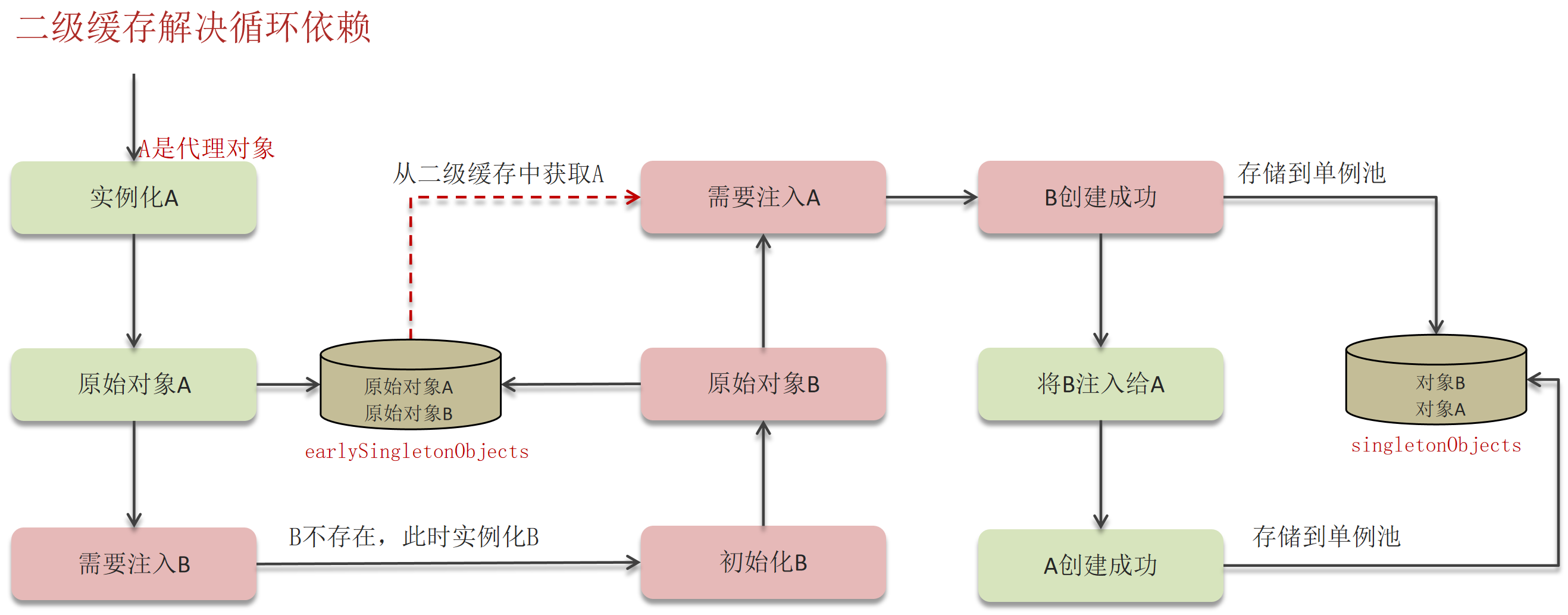
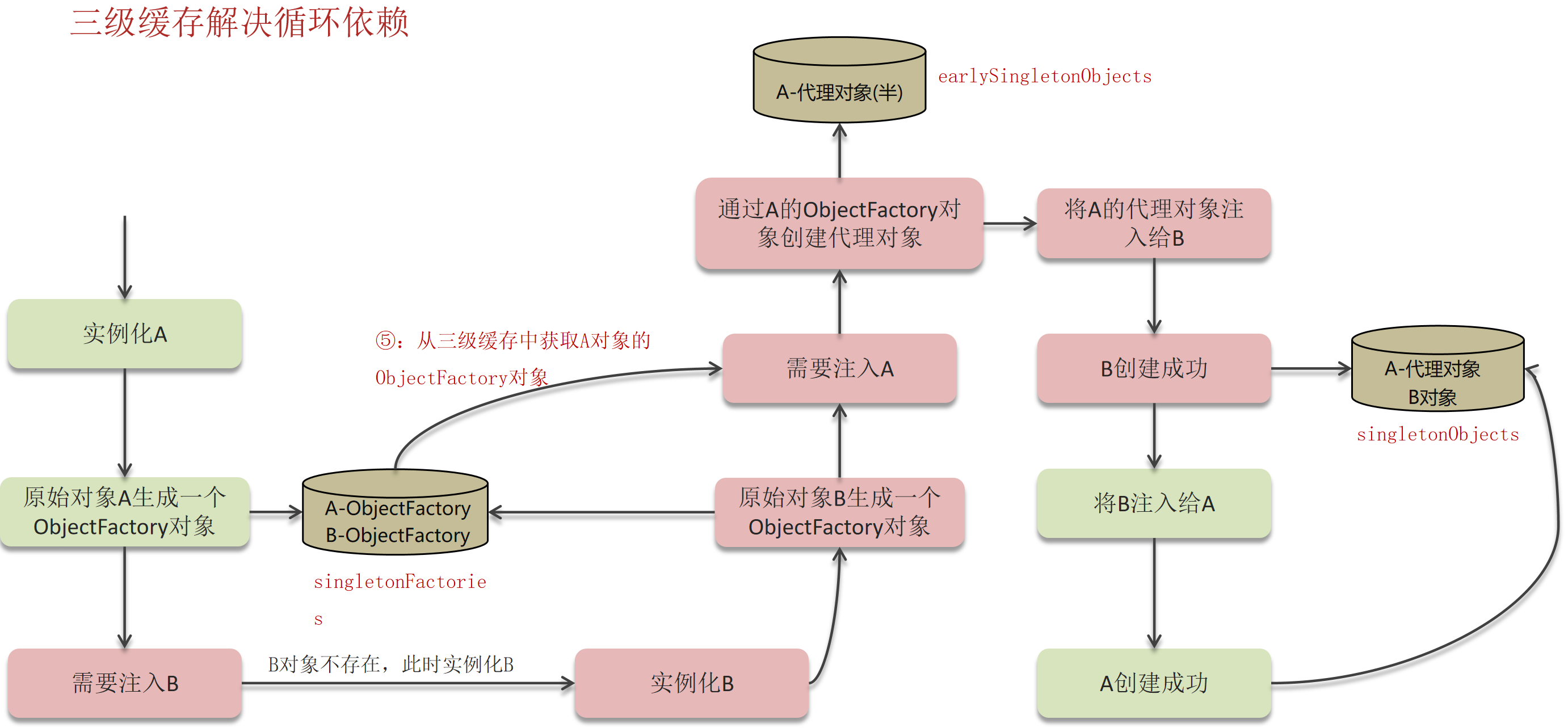
二级缓存和三级缓存解决循环依赖的过程:
- 首先,获取单例 Bean 的时候会通过 BeanName 先去 singletonObjects(一级缓存) 查找完整的 Bean,如果找到则直接返回,否则进行步骤 2。
- 看对应的 Bean 是否在创建中,如果不在创建中直接返回null,如果 Bean 正在创建中,则会去 earlySingletonObjects (二级缓存)查找 Bean,如果找到则返回,否则进行步骤 3
- 去 singletonFactories (三级缓存)通过 BeanName 查找到对应的工厂,如果存在 Bean 对应的 Bean工厂,则通过Bean工厂创建 Bean ,并且将 Bean 放置到 earlySingletonObjects (二级缓存)中。
- 如果三个缓存都没找到,则返回 null。
步骤 2 中如果查询发现 Bean 还未创建,就直接返回 null,返回 null 之后,说明这个 Bean 还未创建,这个时候会标记这个 Bean 正在创建中,然后再调用 createBean 来创建 Bean,而实际创建是调用方法 doCreateBean。doCreateBean 这个方法就会执行上面我们说的三步骤:实例化、属性注入初始化。在实例化 Bean 之后,会往 三级缓存(singletonFactories)塞入一个工厂,而调用这个工厂的 getObject 方法,就能得到这个 Bean。

IOC
什么是 IOC?IOC有什么好处
Spring 的 IOC(Inversion of Control,控制反转)是一种设计模式,用于减少代码间的耦合度,提高软件系统的可维护性、可扩展性和可测试性。在传统的程序设计中,对象的创建和依赖关系的管理是由对象自身负责的,而在使用 IOC 的情况下,这些职责被转移到了外部容器上,即 Spring 容器。
IOC 的概念:控制反转并不是一种具体的实现技术,而是一种设计理念。它描述的是对象的控制权从应用程序代码内部转移到外部容器的过程,即对象的创建和生命周期管理不再由程序员直接控制,而是交给框架来管理。
IOC容器和Bean的关系
1. IOC 容器
IOC 容器是 Spring 框架的核心部分,负责管理应用程序中的所有 Bean 的生命周期和配置。
IOC 容器通过读取配置元数据(通常是 XML 文件、Java 配置类或注解)来了解如何创建和管理 Bean。
IOC 容器的主要职责包括:
- Bean 的实例化:根据配置信息创建 Bean 实例。
- Bean 的装配:管理 Bean 之间的依赖关系,即依赖注入(DI)。
- Bean 生命周期管理:控制 Bean 的初始化、销毁等生命周期行为。
Spring 提供了两种主要的 IOC 容器:
- BeanFactory:这是一个基础的容器接口,提供了基本的依赖注入支持。它是一个轻量级的容器,适合于简单的应用场景。
- ApplicationContext:它是
BeanFactory的子接口,除了提供依赖注入功能外,还增加了许多企业级功能,如 AOP 支持、事件发布、国际化等。ApplicationContext更适合于复杂的大型企业应用。
2. Bean
Bean 是由 IOC 容器管理的对象。这些对象是在应用程序中执行特定任务的 Java 对象,它们的创建、装配和生命周期都由 IOC 容器负责。
Bean 的定义通常包括以下信息:
- 类名:Bean 所对应的 Java 类。
- Bean 名称:用于在容器中唯一标识 Bean。
- 作用域:定义 Bean 的生命周期和范围,如单例(Singleton)、原型(Prototype)等。
- 依赖关系:Bean 可能依赖的其他 Bean 或资源。
- 初始化和销毁方法:指定在 Bean 创建和销毁时调用的方法。
3. IOC 容器与 Bean 的关系
- Bean 的定义和注册:开发者通过配置文件(XML、Java 配置类)或注解(如
@Component、@Service、@Repository、@Controller)来定义 Bean,并将其注册到 IOC 容器中。 - Bean 的实例化:IOC 容器根据配置信息创建 Bean 实例。
- 依赖注入:IOC 容器管理 Bean 之间的依赖关系,通过构造器注入、设值方法注入或字段注入等方式将依赖对象注入到目标 Bean 中。
- 生命周期管理:IOC 容器管理 Bean 的生命周期,包括初始化、使用和销毁等阶段。可以通过配置初始化方法和销毁方法来控制 Bean 的生命周期行为。
依赖注入
依赖注入(Dependency Injection, DI)是实现 IOC 的具体方式之一。通过final+构造函数注入、set方法注入或者接口注入等方式,将对象的依赖关系注入到对象中,而不是让对象自己创建或查找依赖对象。
依赖注入的目的
依赖注入的主要目的是为了减少代码之间的耦合度,提高代码的可复用性和可测试性。通过依赖注入,对象的依赖关系不是由对象自身来创建或查找,而是由外部的容器(如 Spring 容器)在运行时自动注入。
在项目中,一个对象(我们称其为客户端对象)可能需要引用另一个对象(服务对象)来完成某些任务。没有依赖注入的情况下,客户端对象通常会自己创建或查找服务对象的实例,这种方式会导致客户端和服务对象之间存在紧密的耦合。依赖注入通过外部容器来管理这些依赖关系,从而解耦客户端和服务对象。
依赖注入的方式
Spring 框架支持三种主要的依赖注入方式:
构造器注入(Constructor Injection):
在对象创建时通过构造函数传递依赖对象。确保了对象一旦创建后,其依赖项就是不可变的,并且总是处于已初始化状态。
1
2
3
4
5
6
7
8public class Client {
private final Service service;
public Client(Service service) {
this.service = service;
}
}set方法注入(Setter Injection):
通过对象的 setter 方法来注入依赖对象。灵活,允许在对象创建后修改依赖关系。
1
2
3
4
5
6
7
8public class Client {
private Service service;
public void setService(Service service) {
this.service = service;
}
}字段注入(Field Injection):
直接在对象的字段上使用
@Autowired注解来注入依赖对象。简单,但灵活性较差,且不利于单元测试。1
2
3
4public class Client {
private Service service;
}接口注入(Interface Injection):
类似于set方法注入。通过实现特定的接口来注入依赖对象。这种方式在现代 Spring 应用中较少使用,但仍然是一种可行的注入方式。
1
2
3
4
5
6
7
8
9
10
11
12public interface ServiceAware {
void setService(Service service);
}
public class Client implements ServiceAware {
private Service service;
public void setService(Service service) {
this.service = service;
}
}
IOC / 依赖注入的好处
降低耦合度:通过依赖注入,对象之间的依赖关系由 Spring 容器来管理,而不是硬编码在对象内部,这大大降低了对象之间的耦合度。
增强灵活性:由于依赖关系可以在运行时通过配置文件或注解动态设置,因此可以在不修改代码的情况下改变对象的行为,增加了系统的灵活性。
易于测试:依赖注入使得对象更容易被单元测试,因为可以通过注入模拟对象(mock objects)来测试对象的行为,而不需要关心实际的依赖对象。
简化代码:对象的创建和管理都被移到了容器中,减少了初始化代码量,使得业务代码更加简洁明了。
集中管理:所有的依赖关系和对象的生命周期都可以在一个地方进行配置和管理,这有助于团队协作开发,也便于后期维护。
总之,Spring 的 IOC 容器通过提供依赖注入功能,有效地帮助开发者构建松耦合、高内聚的应用程序,提高了代码的质量和开发效率。
IOC容器启动过程
- 加载配置文件:Spring容器会读取并解析配置文件,或基于注解的配置类消息。
- 创建容器:Spring根据配置文件中定义的Bean信息,实例化并管理各个Bean对象。在容器启动过程中,Spring会创建一个BeanFactory或ApplicationContext容器对象。
- 注册Bean定义:Spring容器会根据配置文件中的Bean定义信息,将Bean对象注册到容器中,并配置Bean之间的依赖关系。
- 实例化Bean:容器启动后,会根据Bean定义信息实例化各个Bean对象,并根据需要填充Bean的属性。
- 注册BeanPostProcessor: Spring容器会注册BeanPostProcessor接口的实现类,这些类可以在Bean实例化之后、初始化之前和初始化之后对Bean进行处理。
- 初始化Bean:容器会调用Bean的初始化方法(如@PostConstruct注解标注的方法或实现initializingBean接口的方法)对Bean进行初始化。
- 完成容器启动:容器启动完成后,可以通过ApplicationContext接口提供的各种方法来获取和操作Bean对象。
总的来说,Spring的IOC容器启动过程就是将Bean注册到容器中、实例化Bean、初始化Bean、以及处理Bean之间的依赖关系等一系列操作。通过IOC容器,Spring实现了对象的创建、管理和协调,实现了松散耦合和可维护性,使得业务逻辑和对象的创建、销毁、依赖等不再紧密耦合在一起。
IOC容器装配Bean的详细流程
加载配置信息:创建
BeanFactory实例,加载配置文件创建BeanDefination对象,并将其注册到BeanFactory;实例化Bean:
BeanFactory根据BeanDefination的信息, 得到一个实例化的Bean;初始化Bean:填充
Bean属性,处理@Autowired、@Value等注解,得到一个初始化的Bean;检查依赖关系:检查
Bean之间的依赖关系,确保依赖关系已满足;注入容器中:将
Bean添加到单例池,对外提供使用。
AOP
AOP:将对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect)。
AOP的作用:
- 减少系统中的重复代码
- 降低模块间的耦合度
- 提高系统的可维护性
常见的AOP使用场景:
记录日志
缓存处理
事务处理
AOP的使用(以记录操作日志为例):使用环绕通知+切点表达式(找到要记录日志的方法),通过环绕通知的参数获取请求方法的参数(类、方法、注解、请求方式等),获取到这些参数以后,保存到数据库。例如以下步骤:
1 |
|
注解开发
为了使上面的 AOP 切面生效,我们需要在 Spring 应用上下文中启用 AOP 支持。
1 |
|
例:防重复提交(环绕通知)
代码实现
1 |
|
1 |
|
使用示例
1 |
|
例:分布式锁(环绕通知)
代码实现
1 |
|
1 | // 标记为切面 |
使用示例
1 |
|
例:统计接口调用次数(环绕通知)
代码实现
1 |
|
1 |
|
使用示例
1 |
|
获取调用次数
编写方法来获取某个接口在过去一分钟内的调用次数。
1 | public class RedisApiCallCounter { |
测试
编写单元测试来验证注解是否正确地记录了接口的调用次数。
1 |
|
过滤器也能实现
例:日志记录(前置通知、后置通知)
代码实现
1 | // 表示该注解只能用于方法级别 |
1 | // 标记为切面 |
使用示例
1 |
|
AOP 和 AspectJ 有什么区别?
Spring AOP 和 AspectJ 都是实现面向切面编程(AOP)的技术,但它们之间存在一些关键的区别,包括设计目的、实现机制、功能范围等方面:
设计目的与定位
- Spring AOP:
- 主要目的是为了提供一种简单易用的 AOP 实现,特别适合于那些只需要基本的 AOP 功能的应用程序。
- 它是 Spring 框架的一部分,因此与 Spring 的其他组件(如依赖注入)高度集成,使用起来更加方便。
- Spring AOP 更加关注于应用程序的服务层,特别是事务管理等横切关注点。
- AspectJ:
- 是一个完整的 AOP 框架,旨在提供更加强大和灵活的 AOP 功能。
- AspectJ 不仅限于服务层,还可以用于整个应用程序的任何部分,包括 UI 层和数据访问层。
- 它是一个独立的框架,可以独立于任何应用框架使用,也可以与 Spring 等其他框架集成。
实现机制
- Spring AOP:
- 基于代理模式实现,即通过创建目标对象的代理对象来实现切面逻辑的织入。
- 支持两种代理方式:JDK 动态代理和 CGLIB 动态代理。
- 只能在方法调用级别上应用通知(advice),不能在字段级别或构造函数级别上应用。
- AspectJ:
- 使用编译时织入(compile-time weaving)或加载时织入(load-time weaving)技术,可以在编译期或加载期将切面逻辑直接织入到目标类的字节码中。
- 提供了更多的切入点表达式(pointcut expression),能够匹配更复杂的场景,例如方法调用、字段访问、构造函数执行等。
- 支持更广泛的切面类型,如前置通知(before advice)、后置通知(after advice)、环绕通知(around advice)等。
功能范围
- Spring AOP:
- 提供了基本的 AOP 功能,如事务管理、安全控制等。
- 由于其设计上的限制,无法支持一些高级特性,例如字段级别的拦截。
- AspectJ:
- 提供了更为丰富的 AOP 特性,包括但不限于环绕通知、异常通知、引介通知等。
- 允许开发者定义更细粒度的切入点,从而更好地控制哪些代码应该被切面所影响。
性能考虑
- Spring AOP:
- 由于是基于代理的,所以在性能上可能会稍微逊色于 AspectJ,特别是在需要大量代理的情况下。
- 但是,对于大多数企业级应用来说,这种性能差异通常是可接受的。
- AspectJ:
- 因为它是在编译期或加载期直接修改字节码,所以理论上可以提供更好的运行时性能。
- 编译时织入可能会增加构建过程的时间,但这通常是一次性的成本。
Spring事务
Spring 的事务管理控制事务的开始、提交和回滚。
Spring 事务管理具有以下特点:
- 统一的事务管理接口:Spring 提供了一个抽象的事务管理接口
PlatformTransactionManager,它支持多种事务管理系统,如 JPA、Hibernate、JDBC 等。 - 编程式事务管理:通过手动调用
PlatformTransactionManager的方法来管理事务的开始、提交和回滚。 - 声明式事务管理:通过 XML 或注解的方式,在方法级别声明事务属性,使得事务管理更加简洁和灵活。
事务的使用方式
事务分为编程式事务和声明式事务:
编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用。
声明式事务管理:声明式事务管理建立在AOP之上的。其原理是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
事务失效的场景和原因
| 事务失效场景 | 原因 | 解决办法 |
|---|---|---|
| 异常捕获处理 | 代码自己处理了异常,没有抛出异常,Transactional没有知悉异常,就会失效。 | 手动抛出异常,在catch块添加throw new RuntimeException(e) |
| 抛出检查异常 | Transactional默认只会回滚非检查异常,当代码抛出检查异常(例如:FileNotFoundException )时就会失效。 | 配置rollbackFor属性@Transactional(rollbackFor=Exception.class) |
| 非public方法 | Spring 只能为 public 方法创建代理、添加事务通知 | 改为 public 方法 |
传播行为(Propagation)
传播行为定义了当一个方法被另一个事务性的方法调用时,应该如何处理事务。常见的传播行为包括:
- **
PROPAGATION_REQUIRED**:如果有事务活动,就加入当前事务;如果没有,就创建一个新的事务。 PROPAGATION_SUPPORTS:如果有事务活动,就加入当前事务;如果没有,就以非事务方式运行。PROPAGATION_MANDATORY:必须在现有的事务上下文中执行;如果没有事务,则抛出异常。PROPAGATION_REQUIRES_NEW:总是创建一个新的事务,无论当前是否存在事务。PROPAGATION_NOT_SUPPORTED:以非事务方式运行,并挂起任何存在的事务。PROPAGATION_NEVER:以非事务方式运行,如果存在事务,则抛出异常。PROPAGATION_NESTED:如果存在事务,则在嵌套事务内执行;如果没有,则行为类似于PROPAGATION_REQUIRED。
隔离级别(Isolation Level)
隔离级别定义了事务如何与其他事务相互作用,以防止不同的事务相互影响。常见的隔离级别包括:
ISOLATION_DEFAULT:使用底层数据库的默认隔离级别。ISOLATION_READ_UNCOMMITTED:最低的隔离级别,事务可以看到其他未提交事务所做的更改。ISOLATION_READ_COMMITTED:事务只能看到其他已提交事务所做的更改。ISOLATION_REPEATABLE_READ:事务可以多次读取同一数据,并且得到相同的结果,即使有其他事务在此期间进行了修改。ISOLATION_SERIALIZABLE:最高的隔离级别,事务之间完全隔离,就像按顺序执行一样。
只读事务(Read-Only Transactions)
只读事务是指那些只读取数据而不进行任何写操作的事务。标记为只读的事务可以带来性能上的好处,因为数据库可以优化只读事务的执行。
SpringBoot
自动配置原理
SpringBoot的自动配置通过注解 @SpringBootApplication 实现,这个注解是对三个注解进行了封装,分别是:
@SpringBootConfiguration:声明当前是一个配置类,与 @Configuration 注解作用相同。@ComponentScan:组件扫描,默认扫描当前引导类所在包及其子包。@EnableAutoConfiguration:SpringBoot实现自动化配置的核心注解,该注解通过@Import导入对应的配置选择器,它的核心是META-INF文件夹下的spring.factories文件,里面存放了需要扫描注解的类。在内部它读取了该项目和该项目引用的jar包的的classpath路径下META-INF/spring.factories文件中的所配置的类的全类名。 在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中。条件判断会有像@ConditionalOnClass或@ConditionalOnMissingBean这样的注解,判断是否有对应的class文件或bean对象,如果有则加载该类,把这个配置类的所有的Bean放入Spring容器中使用。
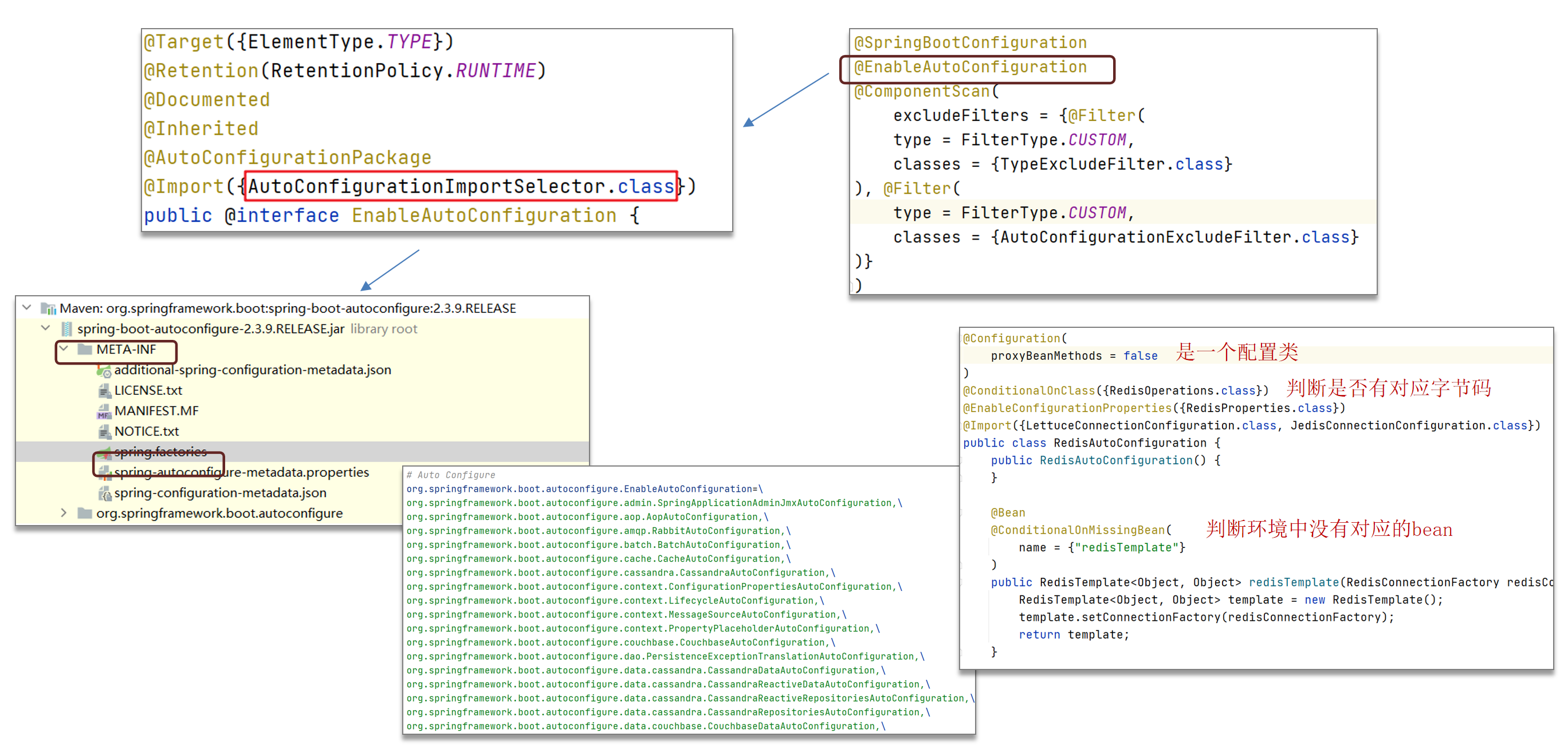
为什么默认使用CGlib?
- 不需要实现接口:JDK动态代理要求目标类必须实现一个接口,而CGLib动态代理可以直接代理普通类(非接口)。这意味着CGLib可以对那些没有接口的类进行代理,提供更大的灵活性。
- 代理对象的创建:JDK动态代理只能代理实现了接口的类,它是通过Proxy类和lnvocationHandler接口来创建代理对象。而CGLib动态代理可以代理任意类,它是通过Enhancer类来创建代理对象,无需接口。
- 性能更好:CGLib动态代理比JDK动态代理更快。JDK动态代理是通过反射来实现的,而CGLib动态代理使用字节码生成技术,直接操作字节码。JDK动态代理对代理方法的调用是通过InvocationHandler来转发的,而CGLib动态代理对代理方法的调用是通过FastClass机制来直接调用目标方法的,这也是CGLib性能较高的原因之一。
JDK 动态代理是基于接口的,所以要求代理类一定是有定义接口的。
CGLIB 基于 ASM 字节码生成工具,它是通过继承的方式生成目标类的子类来实现代理类,所以要注意 final 方法。
SpringMVC
执行流程
Springmvc的执行流程分为老的和新的:
- 视图阶段(老旧JSP年代)
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
- DispatcherServlet调用HandlerAdapter(处理器适配器)
- HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
- Controller执行完成返回ModelAndView对象
- HandlerAdapter将Controller执行结果ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView传给ViewReslover(视图解析器)
- ViewReslover解析后返回具体View(视图)
- DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet响应用户
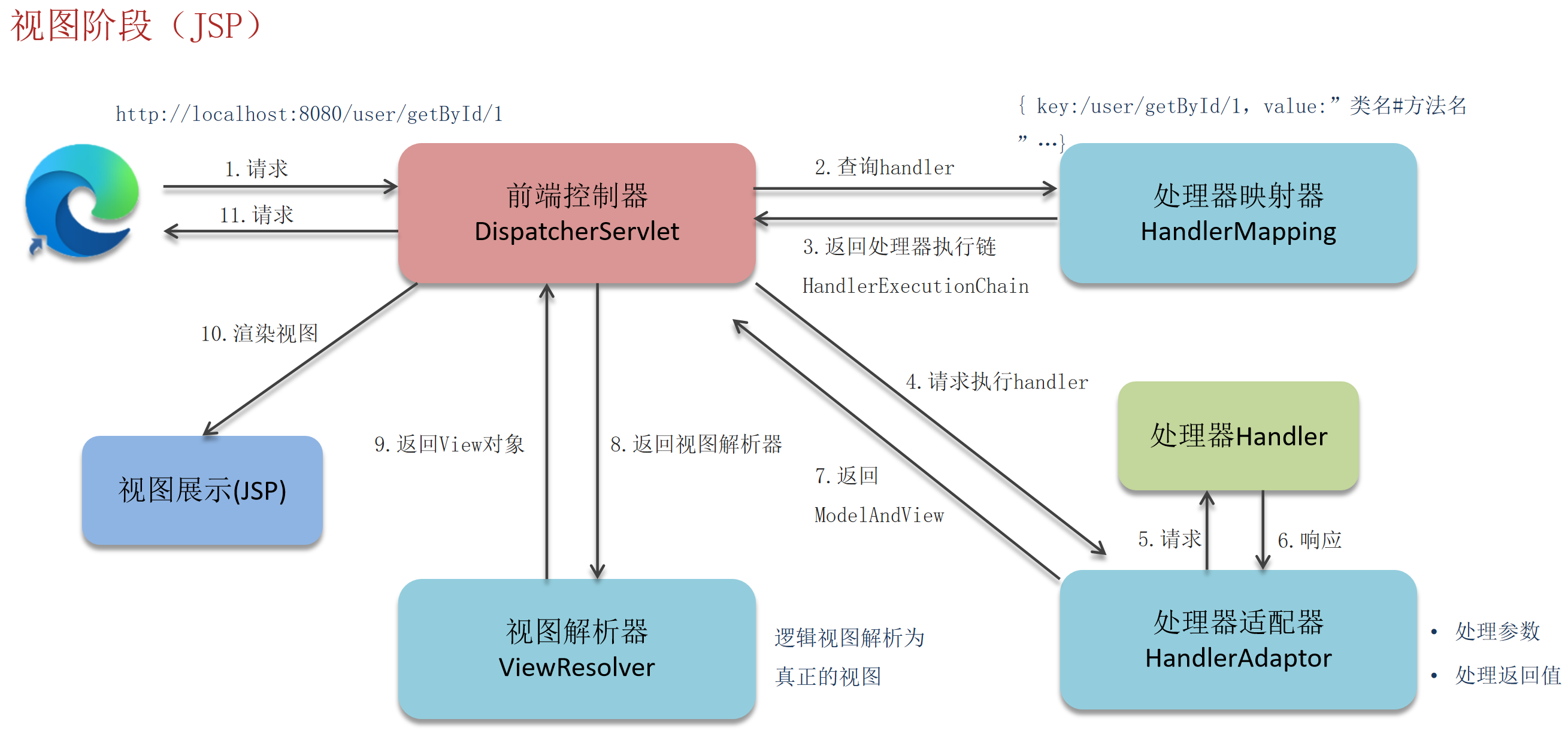
- 前后端分离阶段(接口开发,异步)
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
- DispatcherServlet调用HandlerAdapter(处理器适配器)
- HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
- 方法上添加了@ResponseBody
- 通过HttpMessageConverter来返回结果转换为JSON并响应
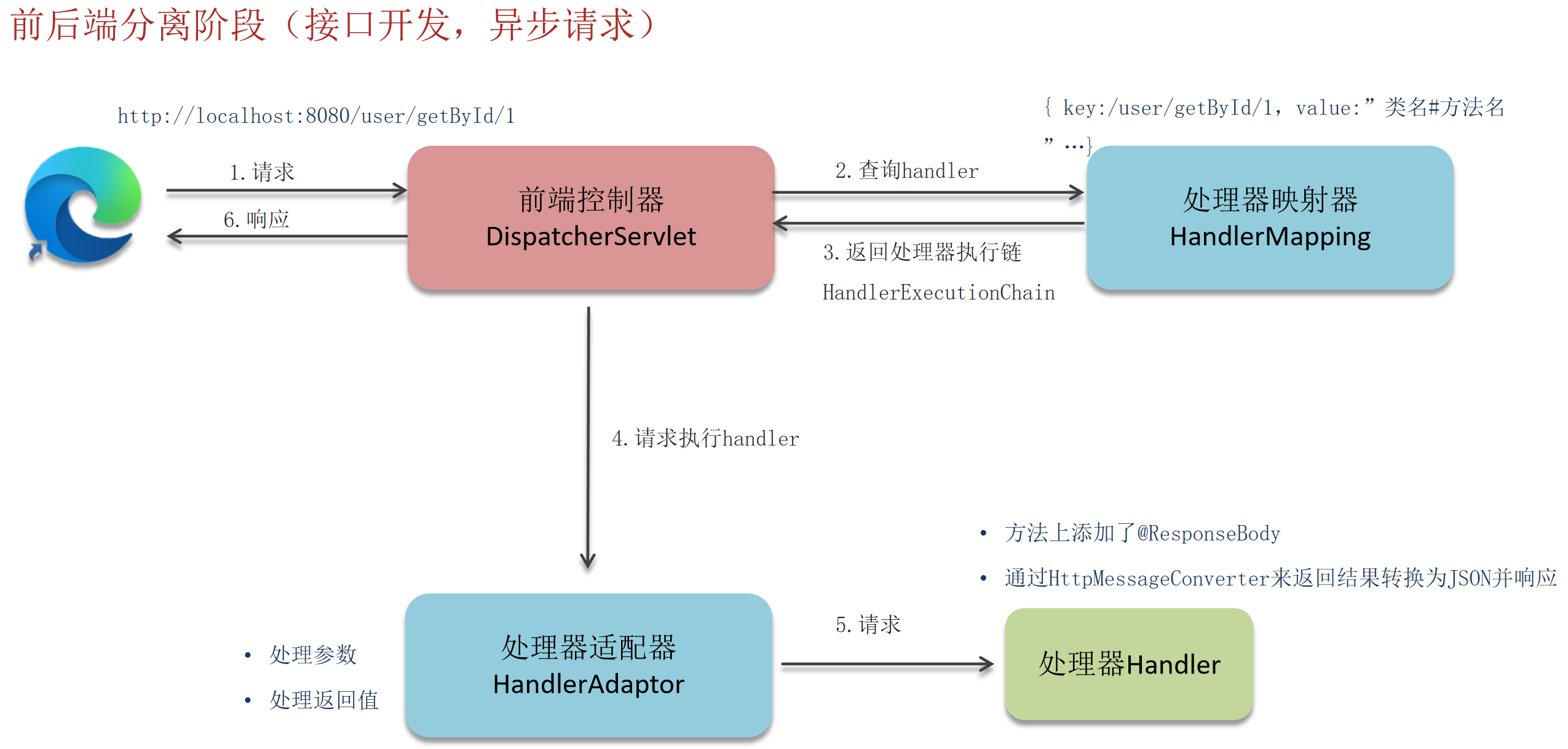
过滤器、拦截器
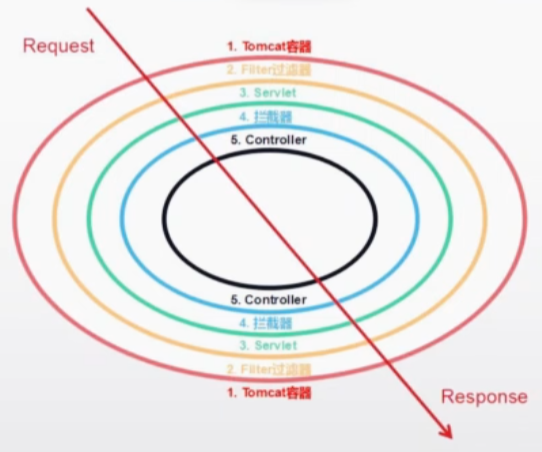
区别
- 生命周期管理:Filter的生命周期由Servlet容器管理;Interceptor则是由Spring MVC框架管理。
- 依赖关系:Filter依赖于Servlet容器;Interceptor依赖于Spring MVC框架。
- 作用范围:Filter可以拦截所有web资源(包括JSP页面、Servlet和其他静态资源);Interceptor则主要针对Spring MVC Controller请求。
过滤器(Filter)
- 用途:编码处理、视图响应、请求参数处理、URL重定向。
- 配置:
- 实现
jakarta.servlet.Filter接口来创建自定义过滤器。 - 重写
doFilter()方法来实现过滤逻辑。 - 可以创建注解来帮助配置过滤器的作用范围。
- 在启动类使用注解启用过滤器
@ServletComponentScan(basePackages = "com.hzx.filter")
- 实现
拦截器(Interceptor)
- 用途:身份认证与授权、接口的性能监控、跨域处理目志记录。
- 配置:
- 实现
org.springframework.web.servlet.HandlerInterceptor接口来创建自定义拦截器。 - 实现
preHandle()、postHandle()、afterCompletion()等方法来定义拦截逻辑。 - 在配置类中实现
WebMvcConfigurer接口,并重写addInterceptors()方法来注册拦截器。
- 实现
Restful 风格的接口
RESTful 接口的设计目标是使 Web 服务更加简单、直观和易于理解。以下是 RESTful 风格接口的主要特点和设计原则:
主要特点
- 无状态:每次请求都是独立的,服务器不保存任何客户端的状态信息。每个请求都包含所有必要的信息,服务器可以根据这些信息处理请求。
- 客户端-服务器架构:客户端和服务器是分离的,客户端负责用户界面和用户交互,服务器负责数据存储和业务逻辑。
- 无会话:服务器不保存客户端的会话状态,每个请求都包含所有必要的信息。
- 可缓存:响应可以被标记为可缓存的,客户端可以缓存这些响应以提高性能。
- 分层系统:客户端和服务器之间可以有中间层(如代理、网关),这些中间层可以改进系统的可伸缩性和性能。
- 按需编码(可选):服务器可以发送可执行代码(如 JavaScript)给客户端,客户端可以在运行时执行这些代码。
设计原则
- 资源:RESTful 接口的核心概念是资源。资源可以是任何东西,如用户、订单、文章等。资源通过 URI(Uniform Resource Identifier)来标识。
- HTTP 方法:使用标准的 HTTP 方法来操作资源。常见的 HTTP 方法包括:
GET:用于获取资源。POST:用于创建资源。PUT:用于更新资源。DELETE:用于删除资源。PATCH:用于部分更新资源。
- HTTP 状态码:使用标准的 HTTP 状态码来表示请求的结果。常见的状态码包括:
200 OK:请求成功。201 Created:资源已创建。204 No Content:请求成功,但没有返回内容。400 Bad Request:请求无效。401 Unauthorized:未授权。403 Forbidden:禁止访问。404 Not Found:资源未找到。405 Method Not Allowed:请求方法不被允许。500 Internal Server Error:服务器内部错误。
- 媒体类型:使用标准的媒体类型(如 JSON、XML)来表示资源的格式。常见的媒体类型包括:
application/jsonapplication/xml
优点
- 简洁:RESTful 接口设计简洁,易于理解和实现。
- 标准化:遵循标准的 HTTP 方法和状态码,提高了互操作性。
- 无状态:每个请求都是独立的,服务器不需要保存客户端的状态信息,提高了可伸缩性。
- 可缓存:响应可以被缓存,提高了性能。
缺点
- 复杂性:对于复杂的业务逻辑,RESTful 接口可能不够灵活,需要更多的设计和实现工作。
- 安全性:RESTful 接口依赖于 HTTP 方法和状态码,可能存在安全风险,需要采取适当的措施来保护接口。
ORM框架
Mybatis的执行流程
- 读取MyBatis配置文件:mybatis-config.xml加载运行环境和映射文件
- 构造会话工厂SqlSessionFactory
- 会话工厂创建SqlSession对象(包含了执行SQL语句的所有方法)
- 操作数据库的接口,Executor执行器,同时负责查询缓存的维护
- Executor接口的执行方法中有一个MappedStatement类型的参数,封装了映射信息
- 输入参数映射
- 输出结果映射
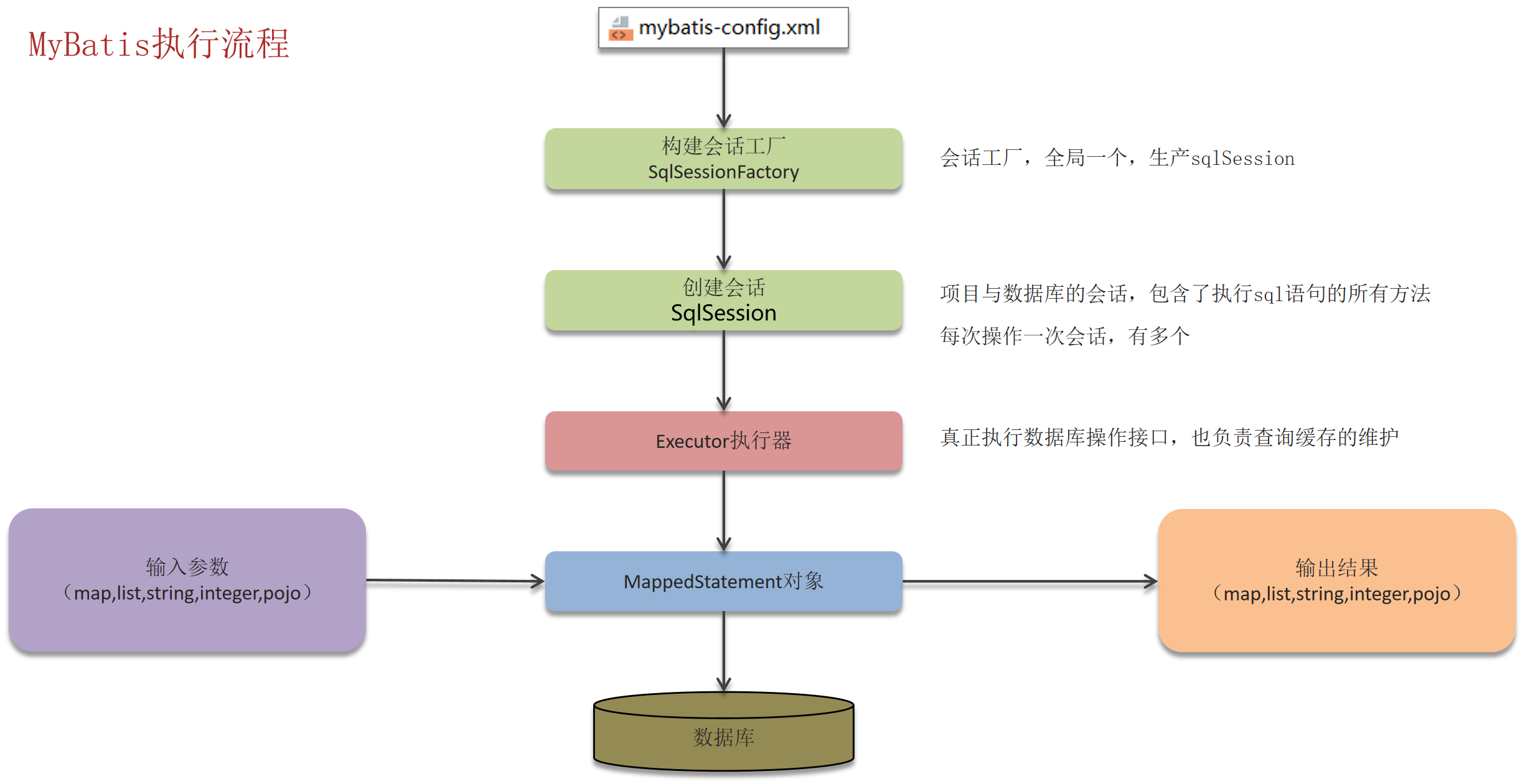
MapperStatement对象的结构:
MyBatis中 # 和 $ 区别
#{} 和 ${} 的区别:
#{}是预编译处理,会将参数替换为?${}是字符串替换,直接将参数值拼接到SQL中
使用场景:
#{}用于SQL语句中的值${}用于动态表名、列名等
安全性:
#{}可以防止SQL注入${}不能防止SQL注入
Mybatis一级缓存、二级缓存
- 一级缓存(默认开启):基于 PerpetualCache 的 HashMap 存储,其存储作用域为 当前的Session,当Session写操作或关闭后(commit、rollback、update、delete),一级缓存就将清空。
- 一级缓存的转移:当前Session提交或者关闭以后,一级缓存会转移到二级缓存。
- 二级缓存:基于namespace和mapper的作用域,不依赖于SQL session,默认也采用 PerpetualCache 的 HashMap 存储。使用二级缓存的数据需要实现Serializable接口。当某一个作用域Session的操作写操作后,默认该作用域下所有 select 中的缓存将被 clear。
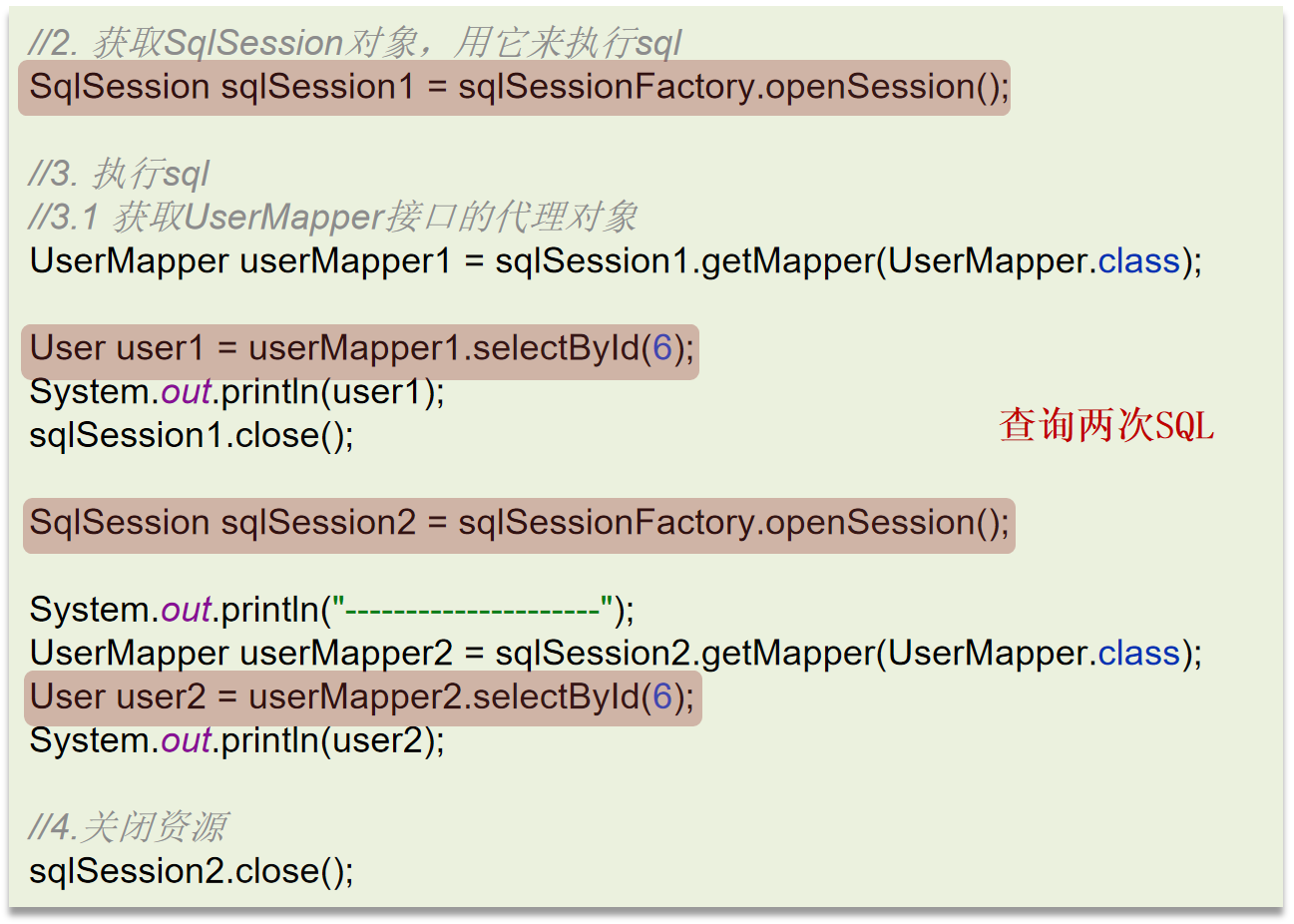
二级缓存开启方式:
- 全局配置文件
1
2
3<settings>
<setting name="cacheEnabled" value="true/>
</settings>- 映射文件
1
使用<cache/>标签让mapper.xml映射文件生效二级缓存
Mybatis一二级缓存的脏数据问题
多 SqlSession 或者分布式环境下,就可能有脏数据的情况发生,建议将一级缓存级别设置为 statement。
一级缓存有脏数据的情况,因为不同 SqlSession 之间的修改不会影响彼此,比如 SqlSession1 读了数据 A,SqlSession2 将数据改为 B,此时 SqlSession1 再读还是得到 A,这就出现了脏数据的问题。
二级缓存也会有脏数据的情况,比如多个命名空间进行多表查询,各命名空间之间数据是不共享的,所以存在脏数据的情况。
例如 A、B 两张表进行联表查询,表 A 缓存了这次联表查询的结果,则结果存储在表 A 的 namespace 中,此时如果表 B 的数据更新了,是不会同步到表 A namespace 的缓存中,因此就会导致脏读的产生。
可以看到 mybaits 缓存还是不太安全,在分布式场景下肯定会出现脏数据。
建议生产上使用 redis 结合 spring cache 进行数据的缓存,或者利用 guava、caffeine 进行本地缓存。
MyBatis 延迟加载的实现原理是什么?
实现原理
- 代理对象:MyBatis 使用动态代理技术来实现延迟加载。当查询一个对象时,MyBatis 并不会立即加载关联的对象,而是返回一个代理对象。
- 拦截器:当访问代理对象中的属性时,代理对象会拦截这些访问请求,并在第一次访问时触发实际的数据库查询。
- 缓存:查询结果会被缓存起来,以便后续访问时不再需要进行数据库查询。
MyBatis 是如何实现数据库类型和 Java 类型的转换的?
MyBatis 使用类型处理器(TypeHandlers)来实现数据库类型和 Java 类型之间的转换。类型处理器是一些实现了 org.apache.ibatis.type.TypeHandler 接口的类,它们负责将 Java 类型转换为数据库类型,反之亦然。
- 内置类型处理器:MyBatis 提供了许多内置的类型处理器,用于处理常见的数据类型转换,如
IntegerTypeHandler、StringTypeHandler等。 - 自定义类型处理器:用户可以自定义类型处理器来处理特定的数据类型转换。自定义类型处理器需要实现
TypeHandler接口,并在 MyBatis 配置文件中注册。
MyBatis 的优点和缺点?
优点
- 简单易学:MyBatis 的 API 设计简洁,易于学习和使用。
- 灵活性高:MyBatis 允许开发者编写 SQL 语句,提供了很大的灵活性。
- 支持动态 SQL:MyBatis 支持动态 SQL,可以根据条件动态生成 SQL 语句。
- 延迟加载:支持延迟加载,提高性能。
- 类型处理器:支持自定义类型处理器,方便处理复杂的数据类型转换。
缺点
- SQL 分离:SQL 语句写在 XML 文件中,与业务逻辑分离,不利于维护。
- 性能问题:对于复杂的查询,MyBatis 可能不如一些 ORM 框架优化得那么好。
- 学习曲线:虽然简单易学,但对于初学者来说,理解和掌握所有特性仍需时间。
—————————————
分布式理论
CAP定理
CAP 定理指出,在分布式系统中,不可能同时实现以下三个保证:
- 一致性(Consistency):所有节点在同一时刻看到相同的数据。
- 可用性(Availability):每个请求不管当前是否是集群的领导节点,都会收到系统的非错误响应。
- 分区容错性(Partition tolerance):即使存在信息丢失(即网络分区),系统仍然能继续运作。
根据 CAP 定理,一个分布式系统只能实现这三个特性中的两个。例如,可以选择一致性和分区容错性,放弃部分可用性;或者选择可用性和分区容错性,放弃一致性。
BASE理论
BASE 是 Basically Available(基本上可用)、Soft state(软状态)、Eventually consistent(最终一致性)这三个短语的首字母缩写。
BASE 是对 CAP 中 AP 选项的一种延伸,它强调的是即使不能保证强一致性,也可以通过牺牲一些一致性来换取系统的高可用性。
- 基本上可用(Basically Available):系统可以出现延迟增加的情况,但仍然能够处理请求,不会完全停止服务。
- 软状态(Soft state):允许系统内部的状态随着时间变化而变化,而不是始终维持不变。
- 最终一致性(Eventual Consistency):系统在经过一段时间后,会达到一个一致的状态。在这个过程中,系统可能会经历中间状态,这些状态可能不是一致的。
分布式组件
总结
| 功能 | 传统 Spring Cloud 组件 | Spring Cloud Alibaba 组件 |
|---|---|---|
| 注册中心 | Eureka | Nacos (同时作为配置中心) |
| 负载均衡 | Ribbon | Ribbon |
| 远程调用 / 服务调用 | Feign | Feign |
| 服务熔断 / 保护 | Hystrix | Sentinel |
| 服务网关 | Zuul | Gateway |
注册中心
Eureka的工作流程
Nacos的工作流程
Nacos 与 Eureka 的功能对比
| 功能 | Nacos | Eureka |
|---|---|---|
| 服务注册 | 支持 | 支持 |
| 服务拉取 | 支持 | 支持 |
| 心跳检测 | 支持(临时实例) | 支持 |
| 主动检测 | 支持(非临时实例) | 不支持 |
| 异常实例剔除策略 | 选择性剔除(临时实例会,非临时实例不会) | 自动剔除 |
| 服务变更推送模式 | 支持主动推送,服务列表更新更及时 | 不支持,只能被动询问 |
| 一致性模型 | 默认 AP(高可用),非临时实例时CP(强一致) | 默认 AP(高可用) |
| 配置中心 | 支持 | 不支持 |
负载均衡
Ribbon的工作流程
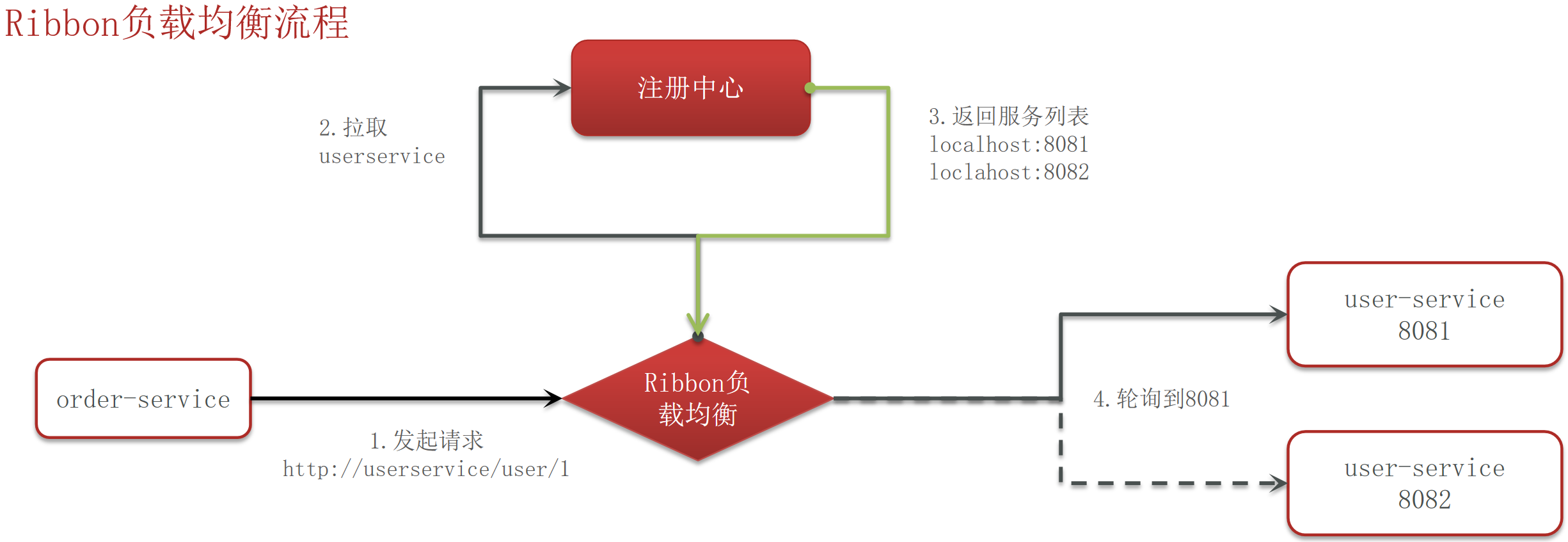
Ribbon的负载均衡策略
- RoundRobinRule:简单轮询服务列表来选择服务器
- WeightedResponseTimeRule:按照权重来选择服务器,响应时间越长,权重越小
- RandomRule:随机选择一个可用的服务器
- BestAvailableRule:忽略那些短路的服务器,并选择并发数较低的服务器
- RetryRule:重试机制的选择逻辑
- AvailabilityFilteringRule:可用性敏感策略,先过滤非健康的,再选择连接数较小的实例
- ZoneAvoidanceRule:以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询
Ribbon实现自定义负载均衡策略
- 全局:创建类实现IRule接口,可以指定负载均衡策略
- 局部:在客户端的配置文件中,可以配置某一个服务调用的负载均衡策略
RPC框架
RPC:Remote Procedure Call ,即远程过程调用
如何设计一个 RPC 框架?
其实就这么几点:
- 动态代理(屏蔽底层调用细节)
- 序列化(网络数据传输需要扁平的数据)
- 协议(规定协议,才能识别数据)
- 网络传输(I/O模型相关内容,一般用 Netty 作为底层通信框架即可)
生产级别的框架还需要注册中心作为服务的发现,且还需提供路由分组、负载均衡、异常重试、限流熔断等其他功能。
说到这就可以停下了,然后等面试官发问,正常情况下他会选一个点进行深入探讨,这时候我们只能见招拆招了。

细节:动态代理 / RPC的实现原理
通过动态代理实现的。
在 Dubbo 中用的是 Javassist,至于为什么用这个其实梁飞大佬已经写了博客说明了。
他当时对比了 JDK 自带的、ASM、CGLIB(基于ASM包装)、Javassist。
经过测试最终选用了 Javassist。
梁飞:最终决定使用JAVAASSIST的字节码生成代理方式。 虽然ASM稍快,但并没有快一个数量级,而Javassist的字节码生成方式比ASM方便,JAVAASSIST只需用字符串拼接出Java源码,便可生成相应字节码,而ASM需要手工写字节码。
RPC 会给接口生成一个代理类,我们调用这个接口实际调用的是动态生成的代理类,由代理类来触发远程调用,这样我们调用远程接口就无感知了。
动态代理,最常见的就是 Spring 的 AOP 了,涉及的有 JDK 动态代理和 cglib。

细节:序列化
序列化原因:网络传输的数据是“扁平”的,最终需要转化成“扁平”的二进制数据在网络中传输。
序列化方案:有很多序列化选择,一般需要综合考虑通用性、性能、可读性和兼容性。
序列化方案对比:
- 采用二进制的序列化格式数据更加紧凑
- 采用 JSON 等文本型序列化格式可读性更佳。
细节:协议
制定协议的原因:需要定义一个协议,来约定一些规范,制定一些边界使得二进制数据可以被还原。
一般 RPC 协议都是采用协议头+协议体的方式。
协议头放一些元数据,包括:魔法位、协议的版本、消息的类型、序列化方式、整体长度、头长度、扩展位等。
协议体就是放请求的数据了。
通过魔法位可以得知这是不是咱们约定的协议,比如魔法位固定叫 233 ,一看我们就知道这是 233 协议。
然后协议的版本是为了之后协议的升级。
从整体长度和头长度我们就能知道这个请求到底有多少位,前面多少位是头,剩下的都是协议体,这样就能识别出来,扩展位就是留着日后扩展备用。
例如Dubbo 协议:

细节:网络传输

一般而言用的都是 IO 多路复用,因为大部分 RPC 调用场景都是高并发调用,IO 复用可以利用较少的线程 hold 住很多请求。
一般 RPC 框架会使用已经造好的轮子来作为底层通信框架。
例如: Java 语言的都会用 Netty ,人家已经封装的很好了,也做了很多优化,拿来即用,便捷高效。
网关(Gateway)
如何实现过滤恶意攻击?
Spring Cloud Gateway 可以通过多种方式来实现对恶意攻击的过滤:
- 限流(Rate Limiting):
- 使用 RequestRateLimiterGatewayFilterFactory 过滤器来限制来自特定 IP 地址的请求频率。
- 可以根据 IP 地址或其他标识符限制请求频率,从而防止 DDoS 攻击。
- 黑名单(Blacklisting):
- 可以根据 IP 地址或其他标识符创建黑名单,拒绝来自黑名单中的请求。
- 白名单(Whitelisting):
- 只允许来自白名单中的请求通过,其他请求直接拒绝。
- 安全过滤器(Security Filters):
- 可以添加自定义的安全过滤器来检测和阻止恶意请求,如 SQL 注入、XSS 攻击等。
如何验证用户身份?
Spring Cloud Gateway 可以通过多种方式来实现用户身份验证:
- OAuth2 / OpenID Connect:
- 使用 OAuth2 或 OpenID Connect 来验证用户的令牌。
- 可以与 Keycloak、Auth0 等认证服务器集成,实现统一的身份验证。
- JWT(JSON Web Token):
- 使用 JWT 令牌来进行身份验证。
- 可以在请求头中携带 JWT 令牌,并在网关层解析和验证令牌的有效性。
- API 密钥(API Key):
- 使用 API 密钥进行身份验证。
- 可以在请求头或查询参数中传递 API 密钥,并在网关层验证密钥的有效性。
- 自定义认证逻辑:
- 可以添加自定义的过滤器来实现复杂的认证逻辑。
- 可以通过数据库查询用户的凭据,验证用户身份。
熔断 / 保护(Sentinel)
服务熔断和保护机制是微服务架构中常用的技术,用于提高系统的稳定性和可靠性。
Sentinel 是一个专门用于实现服务熔断、流量控制和系统保护等功能流行的开源项目。
Sentinel 是一个流量控制和熔断降级框架,可以在分布式系统中快速实现流量控制、熔断降级、系统自适应保护等功能。
Sentinel 提供了多种流量控制策略和熔断规则,能够有效防止雪崩效应,保障系统的稳定性和可用性。
1. 引入sentinel依赖的使用
1 | <!-- Sentinel 依赖 --> |
2. 配置 Sentinel
1 | spring: |
3. 创建限流规则
1 | import com.alibaba.csp.sentinel.annotation.SentinelResource; |
4. 创建熔断规则
1 | import com.alibaba.csp.sentinel.annotation.SentinelResource; |
Sentinel 控制台
Sentinel 提供了一个图形化的控制台,可以实时监控和管理流量控制、熔断降级等规则。通过控制台,可以动态调整规则,而不需要重启应用。
启动控制台
下载 Sentinel 控制台:
sh深色版本
1
2
3git clone https://github.com/alibaba/Sentinel.git
cd Sentinel
cd sentinel-dashboard构建并启动控制台:
sh深色版本
1
2mvn clean package -Dmaven.test.skip=true
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar target/sentinel-dashboard.jar访问控制台: 打开浏览器,访问
http://localhost:8080,使用默认用户名和密码sentinel登录。
服务治理
服务雪崩?怎么解决?
服务雪崩:就是一个服务失败,导致整条链路的服务都失败的情形。
解决:
- 服务熔断(Hystrix ):默认关闭,需要手动在引导类上添加注解
@EnableCircuitBreaker。如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制。之后每隔 5 秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求
- 服务降级(Feign):服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不崩溃,一般在实际开发中与feign接口整合,编写降级逻辑
1 |
|
1 |
|
如何监控微服务?有哪些检测工具?
常见APM工具:
- Springboot-admin
- Prometheus、Grafana
- zipkin
- Skywalking
Skywalking的监控流程:
- 用skywalking监控接口、服务、物理实例的一些状态。特别是在压测的时候了解哪些服务和接口比较慢,可以针对性的分析和优化。
- 在skywalking设置告警规则,如果报错可以给相关负责人发短信和发邮件,第一时间知道项目的bug情况,第一时间修复。
服务熔断(Circuit Breaker)
Sentinel的实现见上
服务熔断是一种保护机制,当一个服务出现故障或响应超时时,暂时停止对该服务的请求,直到其恢复正常。这样可以防止因单个服务的问题而导致整个系统崩溃。
实现服务熔断的方法包括:
- Hystrix:Netflix开源的容错库,支持服务熔断、超时和降级等功能。
- Resilience4j:轻量级的Java库,提供服务熔断等容错机制。
- Spring Cloud CircuitBreaker:基于Spring Boot的API,简化了服务熔断的集成。
- Envoy:边车代理可以集成服务熔断功能。
如何实现服务熔断:
- 监控请求:监控对积分模块的请求情况,包括成功率、响应时间等。
- 设置阈值:定义触发熔断的条件,如请求成功率低于一定比例、响应时间超过设定阈值等。
- 打开断路器:当达到阈值时,断路器打开,暂时阻止请求。
- 重试机制:设置重试间隔和次数,尝试重新建立连接。
- 半开放状态:在一定时间后,进入半开放状态,允许少量请求通过,以检查服务是否恢复正常。
- 关闭断路器:如果服务恢复正常,断路器关闭,恢复请求。
服务降级(Degradation)
服务降级是在系统面临过载时,主动降低服务质量,以保证核心功能的正常运作。
例如:可以暂时关闭积分模块中的非关键功能,以释放资源。
服务降级策略
- 预设降级策略:定义在何种情况下启动降级机制,如CPU使用率过高、内存不足等。
- 实现降级逻辑:在代码中实现降级逻辑,如返回默认值、简化处理流程等。
- 动态配置:根据实际情况动态调整降级策略,如通过配置中心实时更新。
- 记录降级事件:记录降级发生的次数和原因,便于后续分析和改进。
服务限流(Rate Limiting)
限制单位时间内请求的数量,防止服务被过多请求压垮。
服务限流算法
总结
- 令牌桶算法:平滑处理突发流量,适用于需要灵活调整限流策略的场景。
- 漏桶算法:平滑处理突发流量,适用于简单的限流需求。
- 计数器算法:简单易用,适用于简单的限流需求。
- 滑动窗口算法:细粒度控制,适用于需要更精确限流的场景。
令牌桶算法(Token Bucket)
原理:预先分配一定数量的令牌,每次请求消耗一个令牌,当令牌用尽时,拒绝请求。通过一个固定的令牌桶来控制请求的速率。令牌以恒定的速率生成并放入桶中,请求到来时需要消耗一个令牌。如果桶中没有令牌,则拒绝请求。
优点:平滑处理突发流量,避免短时间内的请求激增。灵活性高,可以调整令牌生成速率和桶的容量。
缺点:实现相对复杂,需要管理令牌的生成和消费。
实现:
- 初始化一个令牌桶,设置桶的容量和令牌生成速率。
- 每隔固定时间生成一个令牌,放入桶中。
- 每次请求到来时,检查桶中是否有令牌,如果有则消耗一个令牌,否则拒绝请求。
1 | public class TokenBucketLimiter { |
漏桶算法(Leaky Bucket)
原理:请求进入一个固定容量的桶中,以恒定的速度流出,当桶满时,拒绝新的请求。通过一个固定的漏桶来控制请求的速率。请求进入漏桶后,以恒定的速率流出。如果漏桶已满,则拒绝新的请求。
优点:平滑处理突发流量,避免短时间内的请求激增。实现相对(令牌桶)简单。
缺点:对突发流量的处理能力有限,可能会导致部分请求被拒绝。
实现:
- 初始化一个漏桶,设置桶的容量和流出速率。
- 每次请求到来时,检查桶中是否有空间,如果有则放入桶中,否则拒绝请求。
- 每隔固定时间从桶中移出一个请求。
1 | public class LeakyBucketLimiter { |
计数器算法(Counter)
原理:基于时间窗口的请求数统计,设置最大连接数。在一个固定的时间窗口内统计请求的数量,如果超过了设定的阈值,则拒绝后续的请求。
优点:简单,容易理解。成本低,性能开销小。
缺点:时间窗口边缘的问题:如果在时间窗口的最后几秒钟有大量的请求,而在下一个时间窗口的开始几秒钟也有大量的请求,可能会导致短时间内超过阈值的情况。
实现:
- 初始化一个计数器和一个时间窗口。
- 每次请求到来时,增加计数器的值。
- 如果计数器的值超过设定的阈值,则拒绝请求。
- 当时间窗口结束时,重置计数器。
1 | public class CounterLimiter { |
滑动窗口算法(Sliding Window)
原理:将计数器细分成多个更小的时间窗口。通过将时间窗口划分为多个小的时间段(桶),每个时间段记录请求的数量。当新的请求到来时,根据当前时间所在的桶来统计请求数量,从而实现更细粒度的限流。
优点:
- 细粒度控制,避免了固定时间窗口的边缘问题。
- 更精确地反映最近一段时间内的请求情况。
缺点:
- 实现相对复杂,需要管理多个时间段的计数。
实现:
- 初始化一个数组或环形缓冲区,每个元素代表一个小的时间段。
- 每次请求到来时,找到当前时间所在的小时间段,增加该时间段的计数。
- 如果总请求数量超过设定的阈值,则拒绝请求。
- 定期清除过期的时间段。
1 | public class SlidingWindowLimiter { |
—————————————
分布式事务
分布式事务是指跨越多个数据库或分布式系统的事务。
分布式事务 与 传统事务 的区别
相同点:
- ACID特性:分布式事务和传统事务都遵循ACID(原子性、一致性、隔离性、持久性)特性,保证事务的正确性和完整性。
- 保证数据一致性:无论是分布式事务还是传统事务,都致力于确保事务操作在执行完毕后数据的一致性。
- 提供事务管理:分布式事务和传统事务都提供了事务管理机制,可以控制事务的提交、回滚和隔离级别。
不同:
- 分布式环境:分布式事务通常在多个独立的节点或系统之间进行操作,而传统事务通常在单个数据库或系统中进行操作。
- 事务管理协议:传统事务通常使用本地事务管理机制(如JDBC事务、Spring事务管理),而分布式事务需要使用分布式事务管理协议(如XA协议、TCC协议)来实现跨多个系统的事务一致性。
- 性能开销:由于涉及多个系统的通信和协调,分布式事务通常比传统事务具有更高的性能开销和复杂度。
- 故障处理:在分布式环境下,出现故障或网络问题可能会导致事务的不确定状态,需要额外的机制来保证事务的正确性。
- 可伸缩性:传统事务在面对大规模的并发请求时可能会成为性能瓶颈,而分布式事务可以通过拆分事务、分布式锁等措施来提高可伸缩性。
常见的分布式事务解决方案
为了确保分布式事务的ACID,有以下常见的分布式事务解决方案:
1. 两阶段提交(Two-Phase Commit, 2PC) 【XA 协议、Atomikos、Bitronix】
最传统的分布式事务协议之一。包括准备阶段和提交阶段,其中协调者与参与者进行交互以决定是否提交或回滚事务。
- 准备阶段:协调者询问所有参与者是否准备好提交事务。
- 提交阶段:如果所有参与者都同意,则协调者命令所有参与者提交;如果任何一个参与者不同意,则协调者命令所有参与者回滚。
**2. 三阶段提交(Three-Phase Commit, 3PC) ** 【SAGA、TCC(Try-Confirm-Cancel)、最终一致性】
3PC是在2PC的基础上增加了预表决阶段,以减少阻塞情况的发生。
- 预表决阶段:协调者向参与者发送预表决请求。
- 准备阶段:参与者回复预表决结果。
- 提交阶段:根据参与者回复的结果,协调者发送提交或回滚指令。
**3. 单边提交(One-Sided Commit) ** 【AP系统、DDD架构】
在这种方案中,参与者独立决定是否提交事务,而不需要等待协调者的指示。
这减少了事务处理时间,但增加了协调复杂度。
常用的分布式服务四种接口幂等性方案
幂等性:两次操作的结果一致。
- 业务属性保障幂等:利用主键生成器或者唯一性约束确保数据库的数据唯一;
- 额外的状态字段与业务逻辑控制:根据状态判断工作流程
- 申请预置令牌:
- 本地消息事件表:

Xxl-Job 路由策略?任务执行失败了怎么解决?
Xxl-Job 是一款轻量级分布式的任务调度框架,主要用于解决定时任务的分布式调度问题。它支持多种路由策略,也提供了任务执行失败后的处理机制。
Xxl-Job 的路由策略
Xxl-Job 支持多种任务分配策略,可以根据业务需求选择合适的策略来分配任务到不同的执行器。以下是几种常见的路由策略:
- FIRST:第一个执行器执行。
- ROUND:轮询分发,按照顺序依次分发给不同的执行器。
- HASH:根据指定的参数进行 hash 后取模分发。
- CONSISTENT_HASH:一致性哈希算法分发。
- RANDOM:随机分发。
- BUCKET4:四分桶分发,将执行器分为四个桶,根据任务触发时间分配到不同的桶中执行。
- BUCKET8:八分桶分发,类似于四分桶,但是分成八个桶。
Xxl-Job 任务执行失败的解决方法
当 Xxl-Job 的任务执行失败时,可以采取以下措施来解决问题:
- 查看日志
首先查看任务执行的日志,了解具体的错误原因。Xxl-Job 提供了任务执行日志功能,可以在界面上查看历史执行记录及其输出日志。
- 调整任务执行超时时间
如果是因为任务执行时间过长而导致超时失败,可以适当调整任务的执行超时时间。
- 重试机制
Xxl-Job 支持配置任务的重试次数。如果任务执行失败,可以配置重试机制来自动重新执行任务。 - 失败回调
配置失败回调机制,当任务执行失败时,可以触发回调函数进行额外的处理逻辑,比如记录失败信息、通知相关人员等。 - 监控与报警
设置监控报警机制,当任务执行失败时及时收到报警通知,以便及时介入处理。 - 执行器故障排查
如果任务执行失败是由于执行器本身的问题,比如执行器所在的服务器资源不足、程序异常等,需要排查执行器的问题。 - 调整任务执行策略
如果是由于任务执行策略不合理导致的任务失败,可以考虑调整任务的触发策略、执行器的分配策略等。 - 代码调试
如果是任务逻辑本身的问题,可以通过调试代码来找到并修复问题所在。
总之,解决 Xxl-Job 任务执行失败的方法主要是通过排查日志、调整配置、优化任务逻辑等方式来解决。具体的方法需要根据实际情况灵活选择。
如果有大数据量的任务同时都需要执行,怎么解决?
处理大数据量的任务同时执行时,面临的挑战主要集中在资源消耗、数据处理速度、并发控制等方面。以下是一些常见的解决方案和技术手段:
分批处理(Batch Processing)
将大数据量分割成小批量数据,然后逐批处理。这种方法可以降低单次处理的数据量,从而减少内存占用和提高处理效率。异步处理(Asynchronous Processing)
使用消息队列(如 RabbitMQ、Kafka 等)来异步处理数据。这样可以将大量数据放入队列中,然后由多个消费者并发处理,提高处理速度。多线程或多进程(Multithreading/Multiprocessing)
利用多线程或多进程技术来并发处理数据。这种方式可以充分利用多核 CPU 的能力,提高处理速度。分布式处理(Distributed Processing)
采用分布式计算框架(如 Hadoop MapReduce、Apache Spark、Flink 等)来分散数据处理任务。这些框架可以将数据切片并行处理,并自动处理数据分发、容错等问题。水平扩展(Horizontal Scaling)
通过增加更多的服务器来分散负载。水平扩展意味着增加更多的实例来处理更多的请求,而不是在单一节点上增加更多的资源。缓存机制(Caching)
使用缓存来减轻数据库的压力。对于频繁读取的数据,可以将其缓存起来,减少对数据库的访问频率。限流(Rate Limiting)
为了避免瞬间大量请求导致系统崩溃,可以设置限流机制来控制请求速率。优先级队列(Priority Queue)
使用优先级队列来处理不同重要级别的任务。这样可以确保重要任务优先得到处理。动态调度(Dynamic Scheduling)
根据实时负载动态调整资源分配,确保资源的有效利用。
实施建议
- 评估需求:首先明确任务的具体需求,包括数据量大小、处理时间限制、可用资源等。
- 性能测试:在实施任何方案之前,进行性能测试以确定最佳方案。
- 逐步实施:从小规模开始实施,逐步扩大规模,确保方案的可行性和稳定性。
- 持续优化:随着业务的发展,不断调整和优化方案,确保系统的高效运行。
通过上述方法和技术手段,可以有效地应对大数据量任务的同时执行带来的挑战。
—————————————
架构设计
例:讲一下分布式 ID 发号器的原理
设计目标
- 全局唯一性:生成的 ID 必须在分布式系统中全局唯一。
- 高性能:生成 ID 的操作应该是高效的,不会成为系统瓶颈。
- 可扩展性:随着系统的扩展,ID 发号器也应能够轻松扩展。
- 容错性:即使部分节点失效,系统也应该能够继续正常工作。
- 无中心依赖:减少对单一中心服务的依赖,以提高系统的可用性。
实现原理:Snowflake 算法
Snowflake 算法生成的 ID 是一个 64 位的整数,格式如下:
| 0(1 bit) | 时间戳(41 bit) | 工作机器 ID(10 bit) | 序列号(12 bit) |
|---|---|---|---|
| 0 | 123456789012345678901234567890123456789012345678901234567890 | 00000000000 | 000000000000 |
- 标记位:1 位,占位符。
- 时间戳:41 位的时间戳,可以使用大约 69 年。
- 工作机器 ID:5 位,可以标识不同的机器。
- 序列号:12 位,可以支持同一毫秒内生成的多个 ID。
优点: 生成的 ID 是有序的、高性能、适合高并发场景、实现简单。
缺点: 需要时间同步、如果机器 ID 分配不当,可能会导致冲突。
例:讲一下扫码登陆的原理
在验证码登录场景中,服务器生成 token 并与 PC 端通信的流程通常是通过以下步骤完成的:
1. PC 端请求二维码
- PC 端向服务器请求生成一个二维码(通常是一个唯一的
sessionId或uuid)。 - 服务器生成一个唯一的
sessionId,并将这个sessionId绑定到当前 PC 端的会话。 - 服务器将这个
sessionId编码成二维码图片,发送给 PC 端展示。
2. 手机扫描二维码
- 用户通过手机扫描 PC 端的二维码。
- 手机端读取二维码中的
sessionId并向服务器发送一个请求,表示要确认登录。此请求通常包含用户的登录凭证(例如验证码、短信验证码等)和从二维码中提取的sessionId。
3. 服务器验证并生成 Token
- 服务器接收到手机端的请求后,首先验证手机端提供的登录凭证是否合法。
- 如果验证通过,服务器为该用户生成一个唯一的登录 Token(例如 JWT 或 Session Token),表示用户已成功登录。
- 服务器会将生成的 Token 和手机端扫描二维码时传入的
sessionId进行绑定。
4. 通知 PC 端
- PC 端在二维码展示期间,会不断向服务器发送请求进行轮询(或使用 WebSocket 建立长连接),以查询该
sessionId的状态是否已被确认登录。 - 一旦服务器确认手机端登录成功,服务器会在轮询或 WebSocket 通信中通知 PC 端该
sessionId已绑定 Token。 - 服务器将生成的 Token 发送给 PC 端,PC 端收到 Token 后可以将其存储在 Cookie 或 LocalStorage 中,并以此作为用户身份进行后续操作。
5. PC 端登录成功
- PC 端收到服务器发送的 Token 后,即可认为用户已登录成功。
- 随后 PC 端可以使用这个 Token 访问服务器的受保护资源,例如个人主页或其他服务。
关键流程总结:
- 二维码生成:PC 端获取一个唯一的
sessionId,并展示对应二维码。 - 手机扫描确认:手机端扫描二维码后,将
sessionId和登录凭证提交给服务器。 - 服务器生成 Token:服务器验证通过后,生成用户的登录 Token 并将其与
sessionId绑定。 - PC 端获取 Token:PC 端通过轮询或 WebSocket 等方式,接收服务器发来的 Token,从而完成登录。
通信方式:
- 轮询(Polling):PC 端通过短时间间隔向服务器轮询请求,检查
sessionId的登录状态。 - WebSocket:PC 端和服务器通过 WebSocket 建立长连接,服务器在 Token 生成后通过 WebSocket 将 Token 直接推送给 PC 端。
通过这种方式,服务器知道要将 Token 发送给哪个 PC 端,因为 sessionId(二维码)在 PC 端和服务器之间建立了唯一的关联。
例:购物商城应对大流量、大并发的三类策略
分流
主要是将流量分散到不同的系统和服务上,以减轻单个服务的压力。常见的方法有水平扩展、业务分区、分片和动静分离。
- 水平扩展:通过增加服务器数量来提高访问量和读写能力,如商品读库和商品写库。
- 业务分区:根据业务领域划分成不同的子系统,如商品库和交易库。
- 分片:根据不同业务类型进行分片,如秒杀系统从交易系统中分离;非核心业务分离。
- 动静分离:将动态页面降级为静态页面,整体降级到其他页面,以及部分页面内容降级。
降级
当系统压力过大时,采取一些措施降低服务质量,以保障关键功能的正常运行。
- 页面降级:对页面进行降级处理,如整体降级到其他页面,或者只保留部分内容。
- 业务功能降级:放弃一些非关键业务,如购物车库存状态。
- 应用系统降级:对下游系统进行降级处理,如一次拆分暂停。
- 数据降级:远程服务降级到本地缓存,如运费。
限流
限制请求的数量,以保护系统资源和稳定性。
- Nginx前端限流:京东研发的业务路由,规则包括账户、IP、系统调用逻辑等。
- 应用系统限流:客户端限流和服务端限流。
- 数据库限流:红线区,力保数据库。
例:如何设计一个秒杀功能?
1. 系统架构设计
前端:
页面静态化
- 使用静态页面来减少对服务器的压力,仅在秒杀开始时发送请求。
秒杀按钮控制
使用 JavaScript 控制秒杀按钮的状态,确保只有在秒杀开始时才能点击。
增加防刷机制,如限制短时间内请求频率、验证码等。
后端:处理秒杀逻辑,包括库存扣减、订单生成等。
- 读多写少场景
- 缓存:使用 Redis 等缓存技术存储商品信息和库存,减少对数据库的直接访问。
- 异步处理:使用消息队列(如 RabbitMQ、Kafka)处理秒杀请求,异步生成订单。
- 库存处理
- 预扣库存:秒杀开始前提前扣减库存,避免高并发时库存不足。
- 回滚机制:用户在规定时间内未支付订单,则释放库存。
- 限流
- 令牌桶:使用令牌桶算法限制请求速率。
- 漏桶:使用漏桶算法平滑请求。
负载均衡:使用负载均衡器(如 Nginx、HAProxy)分散请求压力。
微服务架构:将秒杀功能拆分为独立的服务,便于扩展和维护。
2. 数据存储设计
数据库设计
读写分离
- 主从复制:数据库采用主从复制,减轻单一数据库的压力。
事务处理
乐观锁:使用乐观锁机制防止库存超卖,如使用版本号或 CAS(Compare and Swap)操作。
悲观锁:在极端情况下使用悲观锁,但需注意性能影响。
缓存设计
缓存穿透
使用布隆过滤器预先过滤不存在的商品 ID。
缓存空值,减少对数据库的无效请求。
缓存击穿
预热缓存:秒杀开始前将所有商品信息加载到缓存中。
使用分布式锁或 TTL(Time To Live)策略防止缓存击穿。
分布式锁
- 使用 Redis 的 SETNX 或 Redlock 算法实现分布式锁,防止并发操作导致的数据不一致。
3. 安全性(防作弊)
- 限制 IP 地址的访问频率。
- 检测异常请求模式。
- 使用 CAPTCHA 或 reCAPTCHA 验证码。
4. 测试
- 性能测试:使用 JMeter 或 LoadRunner 进行压力测试。
- 功能测试:确保系统在各种边界条件下表现正常。
- 兼容性测试:测试不同浏览器和设备上的表现。
5. 监控与日志
- 性能监控:使用 Prometheus、Grafana 等工具实时监控系统性能。
- 错误日志:记录系统运行时的错误信息,便于问题排查。
6. 秒杀接口示例(Java Spring Boot)
1 |
|
例:如何设计一个订单超时取消功能?
- 定时任务(存在延后取消问题)
- 使用MQ的延时任务
*例:统计某家店铺销量 top 50 的商品?
1. 数据收集与存储
首先,通过一个可靠的数据收集和存储系统来记录每次销售的商品信息。这些消息包括但不限于:
1 | 商品ID、销售数量、销售时间、其他相关属性(如价格、类别等) |
2. 数据汇总
对于销售数据,你需要定期或者实时地汇总销售情况。这可以通过以下几种方式实现:
批处理(Batch Processing):使用批处理框架(如 Apache Hadoop、Apache Spark)来定期(如每天)汇总销售数据,并计算出每个商品的总销量。然后将结果存储在一个易于查询的地方,如另一个数据库表或文件系统。
实时处理(Real-time Processing):使用流处理框架(如 Apache Kafka + Apache Flink 或 Apache Spark Streaming)来实时处理销售数据。这种方法可以更快地得到最新的销售排名信息。
3. 排序与展示
SQL 查询
1 | SELECT product_id, SUM(quantity) AS total_quantity |
API 接口
1 | GET /shops/{shopId}/top-products?limit=50 |
返回的 JSON 格式数据示例如下:
1 | [ |
4. 缓存策略
为了加快响应速度,使用缓存技术(如 Redis)来存储最近的查询结果。
当有新的销售数据到来时,可以更新缓存中的数据,而不是每次都重新计算。
5. 前端展示
前端应用可以使用现代 JavaScript 框架(如 React、Vue.js 或 Angular)来展示销售排名。可以使用图表库(如 ECharts、Chart.js)来可视化展示数据。
6. 安全与权限管理
使用认证和授权机制,确保只有授权的商家才能访问自己店铺的销售数据。
7. 性能优化
- 索引优化:确保在
sales销售表上有适当的索引来加速查询。 - 分页处理:如果数据量非常大,可以考虑使用分页来减少单次请求的数据量。
*例:如何设计一个点赞功能?
1. 前端交互逻辑
点赞/取消点赞操作:当用户点击点赞按钮时,前端向后端发送一个请求,包含点赞用户的 ID 和被点赞的朋友圈动态的 ID。
2. 后端设计
数据库设计
- 朋友圈动态表:记录每条动态的信息,包含动态的 ID、作者、内容、图片等。
- 点赞表:记录点赞的关系,可以使用关联表的方式来存储点赞数据。表中至少包含点赞用户的 ID 和被点赞的朋友圈动态的 ID。
1 | -- 动态表 |
API 接口
1 |
|
前后端实时通信
可以在前端实现实时点赞数的更新。当有新的点赞或取消点赞事件发生时,后端可以推送更新到前端,前端接收到更新后立即刷新页面。
设置 WebSocket 服务器
1 |
|
1 | public class WebSocketHandler extends TextWebSocketHandler { |
处理点赞事件:每当有新的点赞或取消点赞事件发生时,后端需要将这些事件广播给所有连接的客户端。
1 | public void handleLikeEvent(LikeEvent event) { |
3. 数据统计
- 点赞统计:可以定期汇总点赞数据,生成报告或图表,帮助分析用户行为。
- 热门动态推荐:根据点赞数排序,推荐热门动态给用户。
4. 安全性
- 认证与授权:确保只有登录用户才能进行点赞操作,并且只能点赞自己的朋友发布的动态。
- 防刷票:采取措施防止恶意刷票,如限制点赞频率、验证用户身份等。
5. 性能优化
- 缓存:使用缓存(如 Redis)来存储热点数据,减少数据库访问频率。
- 异步处理:点赞操作可以异步处理,提高用户体验。
*例:如何防止用户重复提交?
出现场景:
- 前端按钮
- 卡顿刷新
- 恶意操作
会带来的问题:
- 数据重复错乱
- 增加服务器压力
解决方案:
1. 按钮置灰:点击一次后按钮置灰。
实现方式:
- 在页面中添加监听按钮的点击事件。
- 当点击事件触发时,在执行请求之前,先禁用该按钮。
- 请求完成后(无论成功还是失败),定时重启按钮。
2. 唯一索引:在数据库层面建议一个数据的唯一id。
实现方式:
- 在数据库表中设置一个字段作为唯一标识符,例如订单号、事务ID等。
- 当插入新记录时,检查这个字段是否已经存在。
- 如果冲突,则返回错误给前端告知无法重复提交。
3. 自定义注解 / 拦截器:通过 userId + URL + 类名+ 方法名 是否重复提交
实现方式:
开发一个注解,放在触发器的方法上,用于检查特定的方法上的重复提交。
或:开发一个自定义的拦截器或过滤器,用于检查每次请求。(记得将自定义拦截器注册到WebMVC组件中哦)
给注解设置一个key,如
userId + URL + 类名 + 方法名。使用Redis存储这些防重复提交锁,并设置过期时间。
在接收到请求时,检查这些信息是否已存在于存储中,如果存在则认为是重复请求,可以拒绝处理。
拦截器的代码实现:
1 |
|
1 |
|
*例:设计一个简单的JWT令牌身份检验功能
配置文件
1 | hzx: |
JWT配置文件类
1 |
|
JWT工具类
1 |
|
自定义拦截器
管理员端
1 |
|
用户端
1 |
|
注册拦截器
1 |
|
—————————————
容器化技术和CI/CD
Docker 的基本概念和工作原理
Docker 是一种开源的容器化平台,允许开发者和运维人员以一致的方式部署应用程序。通过将应用程序及其所有依赖打包到一个单独的容器中,Docker 提供了一种便捷的方式来执行和移动应用程序。这种容器在任何符合所需条件的环境中都能保证其运行一致。
工作原理上,Docker 利用 Linux 容器(LXC)的技术,并通过镜像(Image)、容器(Container)、仓库(Repository)等主要概念来实现应用的生命周期管理。具体来说,开发者首先创建一个 Docker 镜像,镜像是一个只读模板,包含应用程序及其运行所需的所有文件。然后,基于这个镜像,Docker 可以启动一个或多个容器,容器是镜像的运行实例。
Docker Compose 的主要用途是什么?
Docker Compose 是用于定义和运行多容器 Docker 应用程序的工具。Compose 使用 YAML 文件定义服务、网络和卷,通过一条简单的命令 docker-compose up 就可以启动并运行整个配置的应用环境。
举个例子,如果你有一个 web 应用,需要用到 MySQL 数据库,传统上你可能需要分别配置和运行这两个服务。而在 Docker Compose 中,你只需要创建一个 docker-compose.yml 文件,定义好 web 服务和 db 服务的配置,然后运行 docker-compose up 即可。
Docker 镜像的构建过程
- 编写 Dockerfile:其中包含了一系列的指令,描述了如何构建一个 Docker 镜像。
- 构建镜像:使用
docker build命令,通过读取 Dockerfile 的内容,逐步执行其中的指令,最终生成一个 Docker 镜像。 - 保存镜像:构建完成的镜像会被保存到本地的 Docker 镜像库中,可以使用
docker images命令查看。 - 发布镜像:如果需要共享镜像,可以将其推送到 Docker Hub 或其他镜像仓库,使用
docker push命令完成发布。 - 使用镜像:最终用户可以使用
docker run命令来启动基于该镜像的容器,完成应用的部署和运行。
Dockerfile 的作用
- 描述构建过程:Dockerfile 通过一系列的指令详细描述了构建镜像的步骤,包括基础镜像、环境配置、软件安装等。
- 保证一致性:同一个 Dockerfile 可以在不同环境下生成一致的镜像,确保应用运行环境的稳定和一致。
- 自动化构建:通过 Dockerfile,可以方便地实现镜像的自动化构建,简化了持续集成和持续部署(CI/CD)过程。
- 版本管理:Dockerfile 可以使用版本控制工具进行管理,方便回滚或跟踪更改记录。
使用 Dockerfile 创建自定义镜像
- 编写 Dockerfile:Dockerfile 是一个文本文件,包含了一系列指令,每个指令用来描述如何构建镜像。通常包括基础镜像的选择、复制文件、安装包以及配置环境等操作。
- 构建镜像:使用
docker build命令来构建镜像。
简单示例:
- 创建一个名为
Dockerfile的文件,内容如下:
1 | # 选择基础镜像 |
- 运行构建命令,将 Dockerfile 构建为镜像:
1 | docker build -t my_custom_image:latest . |
如何优化容器启动时间?
- 使用较小的基础镜像:选择精简的基础镜像,例如
alpine,或其他定制过的轻量级基础镜像,例如scratch。 - 减少镜像层数:每一层都会增加容器启动的开销,精简 Dockerfile,合并多个
RUN命令,将有助于减少层数。 - 利用缓存:在构建镜像时尽量利用 Docker 的缓存功能,避免每次都重建镜像。
- 适当配置健康检查:配置适当的健康检查策略,让容器可以尽快转为运行状态,而不是卡在启动过程中。
- 本地化镜像:将常用的容器镜像保存在本地镜像库中,避免每次启动时从远程仓库拉取。
如何实现容器之间的通信?
- 使用同一个网络: 将多个容器连接到同一个 Docker 网络中,这样容器之间可以通过容器名称进行互相通信。
- 端口映射: 将容器的端口映射到宿主机的端口,通过宿主机的 IP 和映射的端口进行通信。
- Docker Compose: 使用 Docker Compose 来编排多个服务,可以为每个服务定义网络,并对网络进行配置。
- 共享网络命名空间: 通过创建共享网络命名空间的方式,使多个容器共享网络设置。
如何实现资源限制?
- 为了限制容器使用的 CPU 数量,可以使用
--cpu-shares或--cpus参数。--cpu-shares:使用相对权重方式分配 CPU 资源。--cpus:直接指定容器可使用的 CPU 核数。
- 为了限制容器使用的内存量,可以使用
-m或--memory参数。--memory:指定容器最大内存限制。
举个简单的例子,如果我们希望某个容器最多使用一个CPU核心和 512MB 内存,可以使用以下命令:
1 | docker run --cpus=1 --memory=512m [container_name] |
如何使用 Jenkins 与 Docker 集成?
- 安装必要的插件:在 Jenkins 中,安装 Docker plugin 和 Pipeline plugin 等必要插件。
- 配置 Jenkins:配置环境,确保 Jenkins 可以访问 Docker 命令。
- 创建 Jenkins Pipeline:在 Jenkins 中创建一个 Pipeline 项目,并在 Pipeline Script 中编写构建、测试和部署的脚本,通常使用 Jenkinsfile。
- 运行与监控:配置好所有步骤后,运行 Pipeline 并监控执行过程,确保一切正常工作。
—————————————
消息队列
AMQP协议
AMQP(Advanced Message Queuing Protocol)是一种开放的标准协议,用于消息传递中间件。它提供了一种标准化的方法来实现消息传递系统之间的互操作性。AMQP 协议最初由金融行业提出,目的是为了实现跨组织的消息传递,但现在已被广泛应用于多种场景。
AMQP 的特点
- 开放标准:AMQP 是一个公开的标准协议。
- 跨平台和语言:AMQP 设计为跨平台和跨语言的协议,支持多种编程语言和操作系统。
- 安全性:AMQP 支持安全的消息传递,包括认证、授权和加密。
- 可靠性:AMQP 支持消息确认机制,确保消息的可靠传输。
- 灵活性:AMQP 允许不同的消息传递模式,包括点对点(P2P)和发布/订阅(Pub/Sub)。
AMQP 的基本概念
AMQP 协议定义了几个基本的概念,这些概念构成了消息传递的基础:
- 连接(Connection):客户端与消息传递中间件之间的网络连接。
- 通道(Channel):在连接之上建立的虚拟连接。每个通道都是一个独立的会话,可以在一个连接中同时使用多个通道。
- 交换机(Exchange):用于接收来自生产者的消息,并根据绑定规则将消息路由到一个或多个队列。
- 队列(Queue):用于暂存消息,直到消费者准备好接收它们。
- 绑定(Binding):用于定义交换机和队列之间的关系,以及消息如何从交换机路由到队列。
AMQP 的消息格式
AMQP 消息通常包含以下几个部分:
- 头部(Header):包含消息的元数据,如优先级、TTL 等。
- 属性(Properties):包含消息的属性,如消息的唯一标识符、内容类型、内容编码等。
- 体(Body):包含消息的实际内容。
AMQP 的消息传递流程
以下是 AMQP 消息传递的基本流程:
- 建立连接:客户端与消息传递中间件建立 TCP/IP 连接。
- 打开通道:客户端在连接上打开一个或多个通道。
- 声明交换机和队列:客户端声明交换机和队列,并定义它们之间的绑定关系。
- 发送消息:生产者通过交换机发送消息。
- 接收消息:消费者从队列中接收消息。
- 关闭通道和连接:完成消息传递后,关闭通道和连接。
AMQP 的消息传递模型
点对点(P2P)模型:
- 在这种模型中,消息发送到队列,消费者从队列中拉取消息。一旦消息被一个消费者消费,它就会从队列中移除。
- 这种模型适用于消息必须被处理一次且只处理一次的情况。
发布/订阅(Pub/Sub)模型:
- 在这种模型中,消息发送到一个主题,所有订阅该主题的消费者都会接收到消息。
- 这种模型适用于消息需要被多个消费者接收的情况。
##推模式 vs 拉模式
推消息(Push)模式
消息队列主动将消息发送给消费者。
优点:
- 实时性强:消息可以立即传递给消费者,减少延迟。
- 减少轮询:消费者无需频繁地检查是否有新消息到达,从而减少了网络负载和资源消耗。
缺点:
- 连接管理复杂:需要保持长连接,并且需要处理连接断开的情况。
- 处理失败:如果消费者未能及时处理消息,可能导致消息积压或丢失。
- 资源消耗:持续保持连接可能会占用较多的资源,尤其是在高并发环境下。
拉消息(Pull)模式
消费者主动从消息队列中获取消息。
优点:
- 控制灵活性:消费者可以根据自己的处理能力和需求来决定何时拉取消息。
- 连接简单:通常只需要短连接,降低了服务器的压力。
- 容易重试:如果处理过程中出现问题,可以更容易地重新尝试获取消息。
缺点:
- 增加网络负载:频繁的轮询会导致额外的网络流量。
- 延迟增加:由于需要消费者主动请求,所以消息传递可能不如推模式实时。
Kafka是拉模式,这使得 Kafka 很适合处理大量数据流的应用场景。
推拉结合(Push-Pull)模式
推拉结合使用,可以结合两者的优点,提高消息传递的效率和可靠性。
例如,消息队列可以先推送消息给消费者,然后消费者再拉取这些消息以确认处理状态。
RabbitMQ名词解释
Exchange(交换器):
- 定义:交换器是RabbitMQ中的消息路由中心。它接收来自生产者的消息,并根据一定的规则将消息发送到一个或多个队列中。
- 类型:主要有四种类型:Direct(直接)、Fanout(广播)、Topic(主题)和System(系统)。
- Direct:根据路由键(routing key)匹配队列。
- Fanout:无路由键概念,将消息发送给所有绑定到该交换器的队列。
- Topic:根据通配符模式匹配路由键。
- System:较少使用,根据消息头属性进行路由。
Queue(队列):
- 定义:队列是消息的实际存储位置,是消息的最终目的地。
- 特性:可以设置持久化、独占、自动删除等属性。
Routing Key(路由键):
- 定义:生产者发送消息时使用的键,用于将消息路由到特定的队列。
- 用途:在Direct和Topic类型的交换器中,根据路由键来确定消息的去向。
Binding(绑定):
- 定义:队列与交换器之间的关联关系,决定了消息如何从交换器到达队列。
- 用途:通过绑定关系,交换器可以将消息发送到一个或多个队列。
Message(消息):
- 定义:由生产者创建并发送给交换器的信息单元。
- 组成:通常包括消息体(body)和消息属性(properties),如消息的优先级、TTL等。
Virtual Host(虚拟主机):
- 定义:类似于隔离的RabbitMQ实例,可以实现不同的应用使用不同的虚拟主机。
- 用途:提供命名空间和安全隔离机制。
Connection(连接):
- 定义:客户端与RabbitMQ服务器建立的TCP连接。
- 用途:用于发送命令、接收响应等。
Channel(通道):
- 定义:建立在连接之上的轻量级逻辑连接,可以复用TCP连接。
延迟队列:
延迟队列:进入队列的消息会被延迟消费的队列。
应用场景:超时订单、限时优惠、定时发布
延迟队列 = 死信交换机 + TTL(生存时间)
死信队列
死信队列:当一个队列中的消息满足下列情况之一时,可以成为死信:
消费者使用
basic.reject或basic.nack声明消费失败,并且消息的 requeue 参数设置为 false消息过期了,超时无人消费
要投递的队列消息堆积满了,最早的消息可能成为死信
死信交换机
死信交换机:配置了dead-letter-exchange属性的队列所指定的交换机。
1
2
3
4
5
6
7
public Queue ttlQueue(){
return QueueBuilder.durable("simple.queue") // 指定队列名称, 并持久化
.tt1(10000) // 设置队列的超时时间,10秒
.deadLetterExchange("dl.direct") // 指定死信交换机
.build();
}
Kafka名词解释
- Topic(主题):
- 定义:消息的分类容器,相当于RabbitMQ中的Exchange和Queue的组合体。
- 特性:每个主题可以有多个分区,用于支持并行处理。
- Partition(分区):
- 定义:主题下的子集,用于提高并行处理能力。
- 特性:每个分区都是有序且不可变的消息序列,可以跨多个Broker分布。
- Broker(代理):
- 定义:Kafka集群中的一个节点,负责存储和转发消息。
- 用途:处理客户端请求,如消息的发布和订阅。
- Producer(生产者):
- 定义:向Kafka主题发送消息的应用程序。
- 特性:可以指定消息的分区和键(Key)。
- Consumer(消费者):
- 定义:从Kafka主题中读取消息的应用程序。
- 特性:通常以组的形式存在,同一组内的消费者可以实现负载均衡。
- Consumer Group(消费者组):
- 定义:一组消费者,通常用于实现负载均衡。
- 特性:组内的消费者可以共享消息,一个分区在同一时刻只能被组内的一个消费者消费。
- Offset(偏移量):
- 定义:记录消费者在主题中的消费进度。
- 用途:用于恢复消费状态,确保消息不会被重复消费。
- Leader(领导者):
- 定义:负责处理客户端读写请求的Broker。
- 用途:确保数据的一致性和高可用性。
- Replica(副本):
- 定义:分区的备份,用于提高系统的可靠性和可用性。
- 用途:当Leader失效时,可以切换到其他Replica继续提供服务。
—————————————
消息队列的底层设计(RabbitMQ、Kafka)
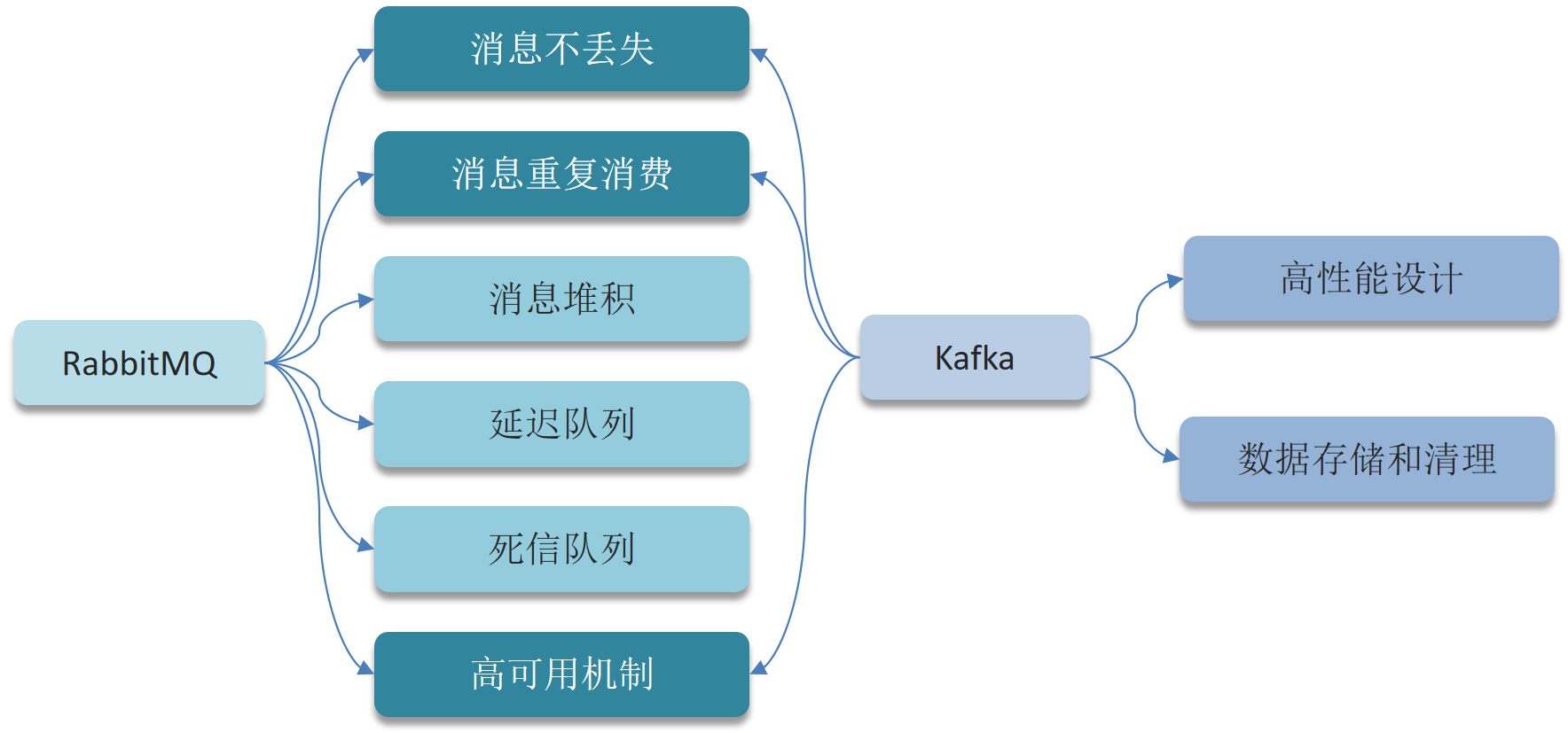
高可用设计
RabbitMQ:
在生产环境下,使用集群来保证高可用性
普通集群
- 会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息
- 当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
- 队列所在节点宕机,队列中的消息就会丢失
镜像集群(本质是主从模式)
- 交换机、队列、队列中的消息会在各个镜像节点之间同步备份。
- 创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
- 一个队列的主节点可能是另一个队列的镜像节点
- 所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主节点
仲裁队列(优化镜像集群)
- 与镜像队列一样,都是主从模式,支持主从数据同步
- 使用非常简单,没有复杂的配置
- 主从同步基于Raft协议,强一致性
- 代码实现:
1
2
3
4
5
6
7
public Queue quorumQueue() {
return QueueBuilder
.durable("quorum.queue") // 持久化
.quorum() // 仲裁队列
.build();
}
Kafka:
集群模式
- Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成
- 如果集群中某一台机器宕机,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一
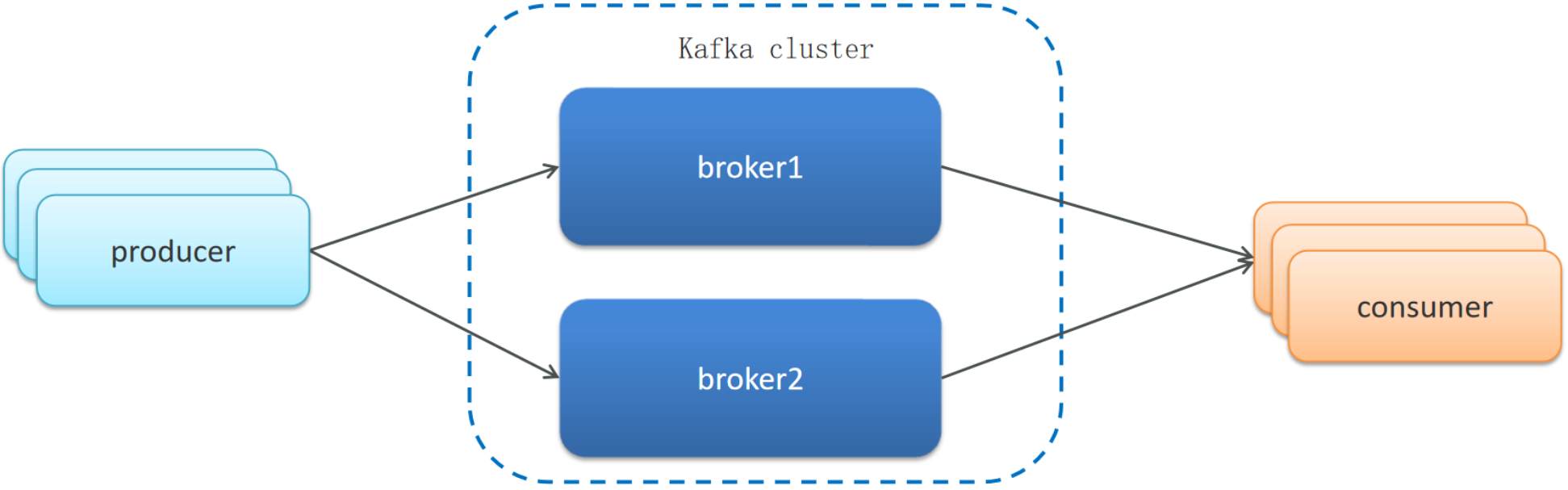
分区备份机制
- 一个topic有多个分区,每个分区有多个副本,其中有一个leader,其余的是follower,副本存储在不同的broker中
- 所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader
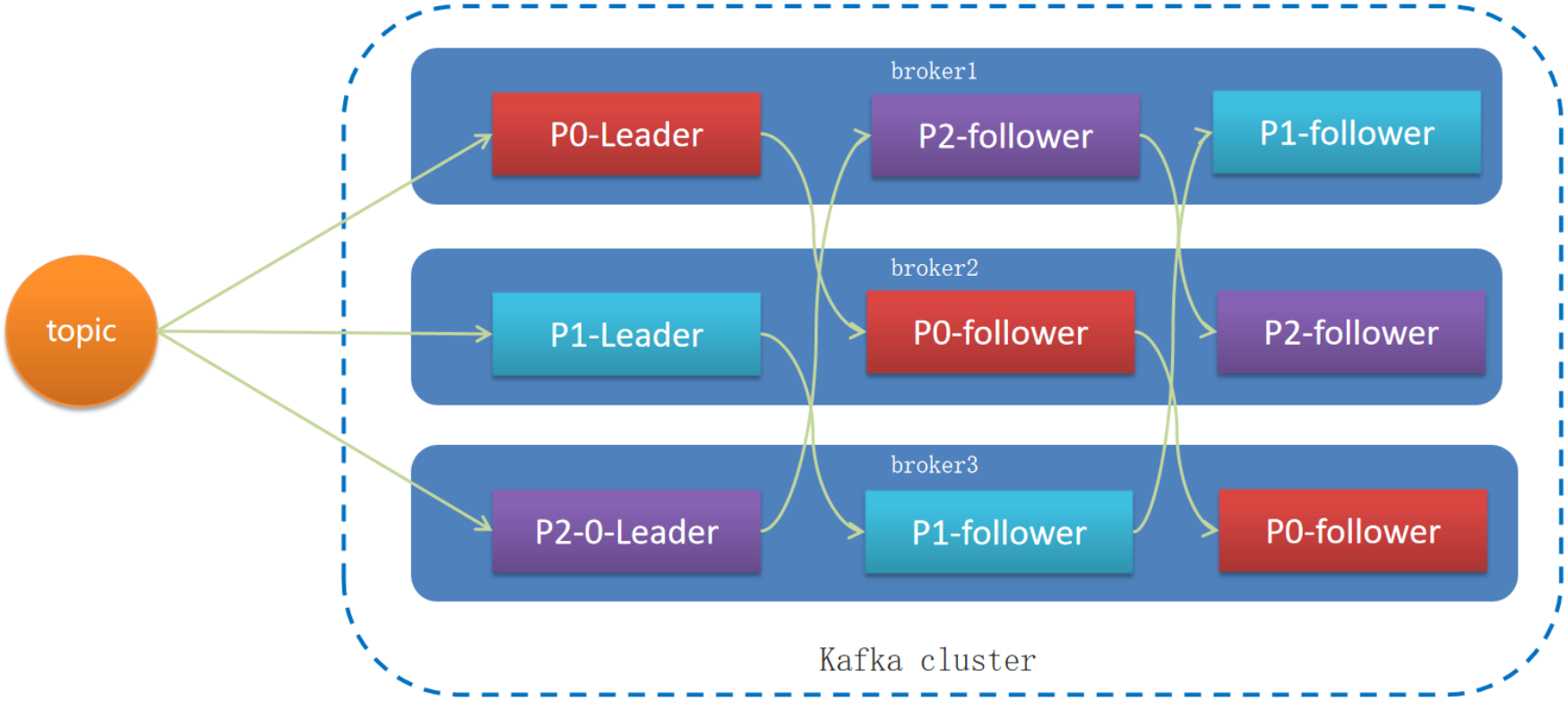
分区副本复制机制
- ISR(in-sync replica)分区是Leader分区同步复制保存的一个队列,普通分区是Leader分区异步复制保存的一个队列
- 如果leader失效后,需要选出新的leader,选举的原则如下:
- 第一:选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的
- 第二:如果ISR列表中的follower都不行了,就只能从其他follower中选取
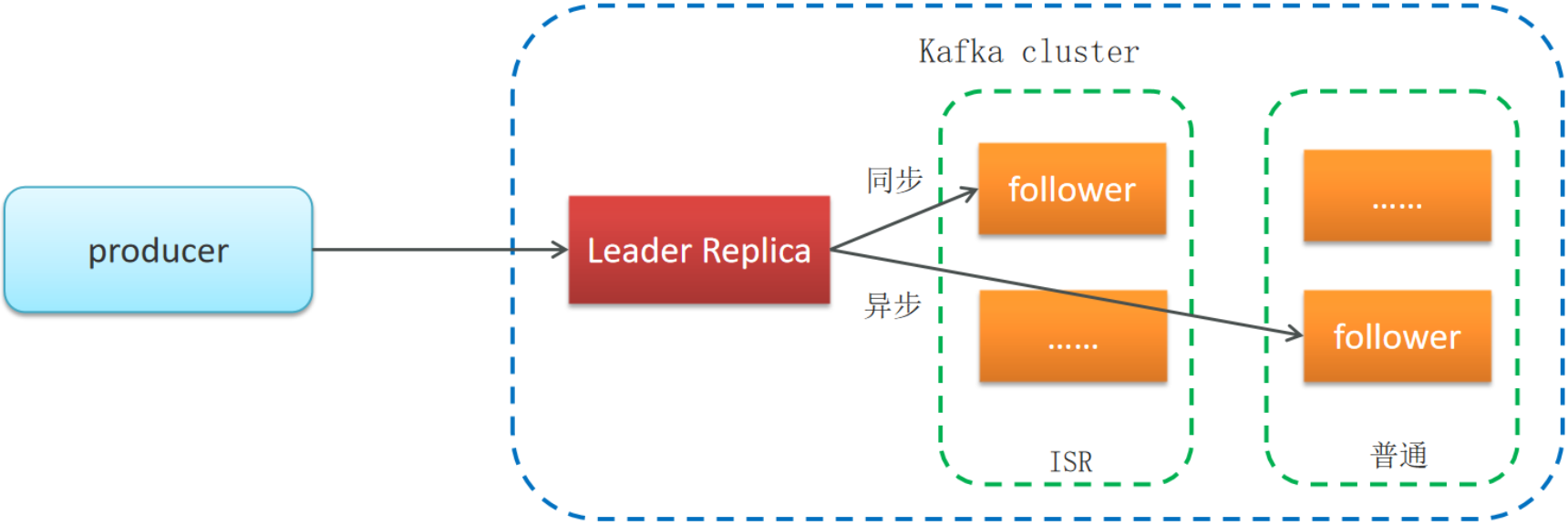
保证消息不丢失
RabbitMQ
消息持久化:RabbitMQ的消息默认是存储在内存,开启持久化功能将消息缓存在磁盘,可以确保消息不丢失,但会受IO性能影响。
- 交换机持久化

- 队列持久化

- 消息持久化,SpringAMQP中的的消息默认是持久的,可以通过MessageProperties中的DeliveryMode来指定的:

消费确认机制:消费者处理消息后可以向RabbitMQ发送ack回执,RabbitMQ收到ack回执后才会删除该消息。
SpringAMQP则允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
失败重试机制:在消费者出现异常时利用本地重试,设置重试次数,当次数达到了以后,如果消息依然失败,将消息投递到异常交换机,交由人工处理。
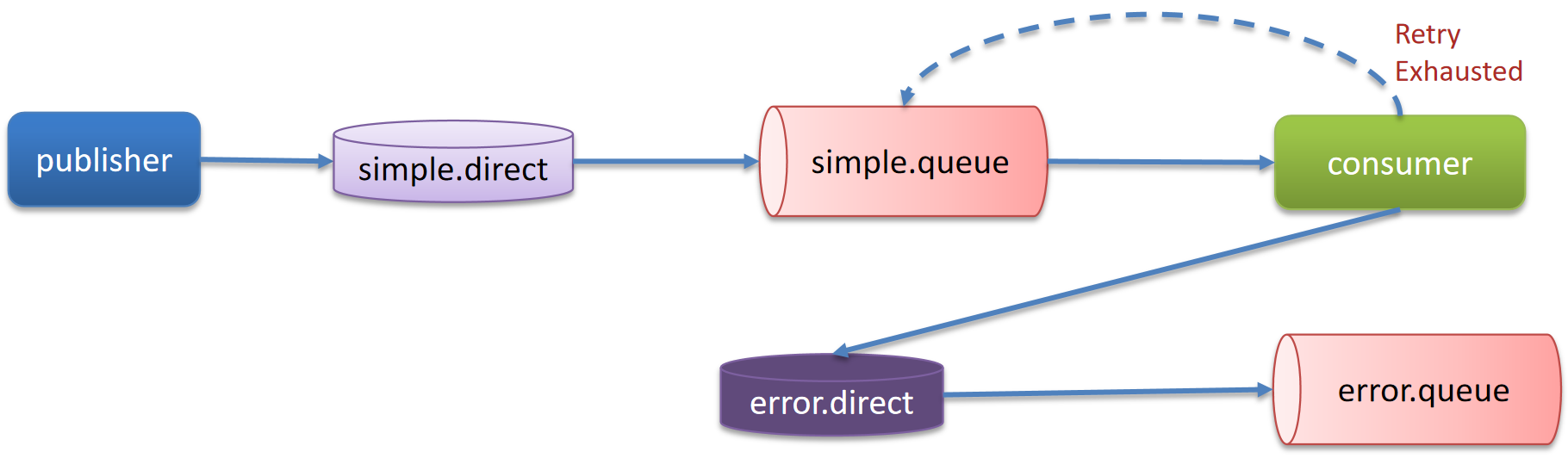
Kafka
从三个方面考虑消息丢失:
生产者发送消息到Brocker丢失:
- 设置异步发送,发送失败使用回调进行记录或重发

- 失败重试,参数配置,可以设置重试次数

消息在Brocker中存储丢失:
- 发送确认acks,选择all,让所有的副本都参与保存数据后确认
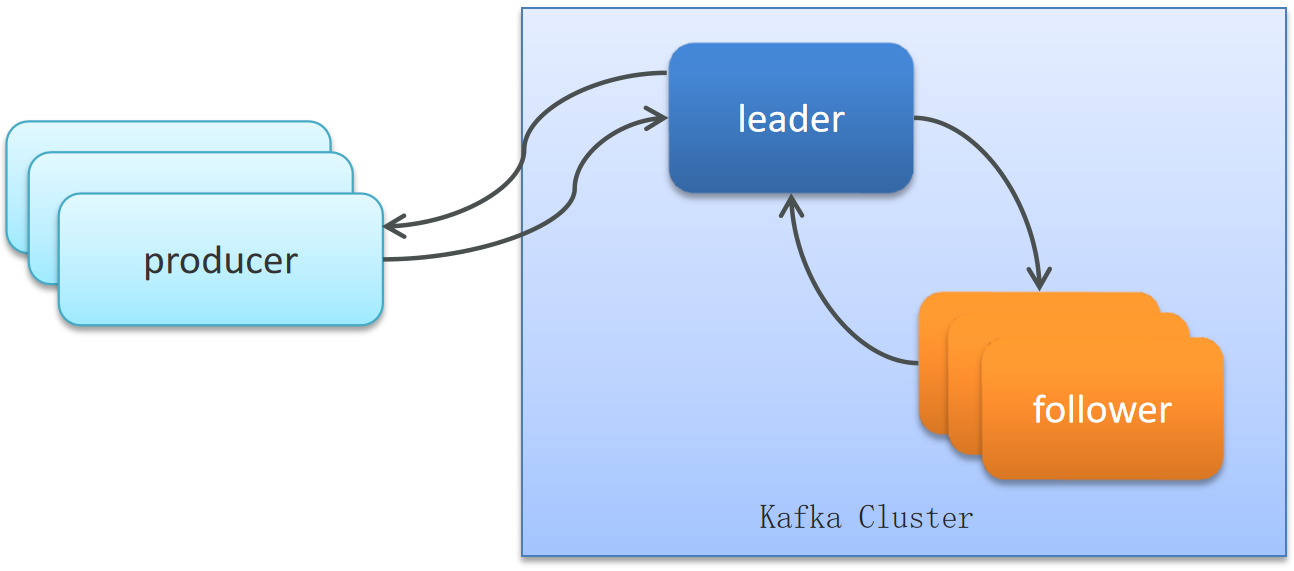
确认机制 说明 acks=0 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 acks=1(默认值) 只要集群主节点收到消息,生产者就会收到一个来自服务器的成功响应 acks=all 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 消费者从Brocker接收消息丢失(重平衡):
- 禁用自动提交偏移量,改为手动提交偏移量
- 提交方式,最好是异步(优先)+同步提交
避免重复消费
这依赖于外部设计,MQ和Kafka不做防范
RabbitMQ:
- 每条消息设置一个唯一的标识id:eg.在处理支付业务时,可以先拿着业务的唯一标识到数据库查询一下,如果这个数据不存在,说明没有处理过,这个时候就可以正常处理这个消息了。如果已经存在这个数据了,就说明消息重复消费了,我们就不需要再消费了。
- 幂等方案:redis分布式锁、数据库锁(悲观锁、乐观锁)
Kafka:
禁用自动提交偏移量,改为手动提交偏移量
提交方式,异步提交 + 同步提交
幂等方案:redis分布式锁、数据库锁(悲观锁、乐观锁)
解决消息堆积问题
增加更多消费者,提高消费速度
在消费者内开启线程池加快消息处理速度
扩大队列容积,提高堆积上限,采用惰性队列
- 在声明队列的时候可以设置属性
x-queue-mode为lazy,即为惰性队列 - 惰性队列基于磁盘存储,消息上限高
- 惰性队列性能比较稳定,但基于磁盘存储,受限于磁盘IO,时效性会降低
- RabbitMQ代码实现:

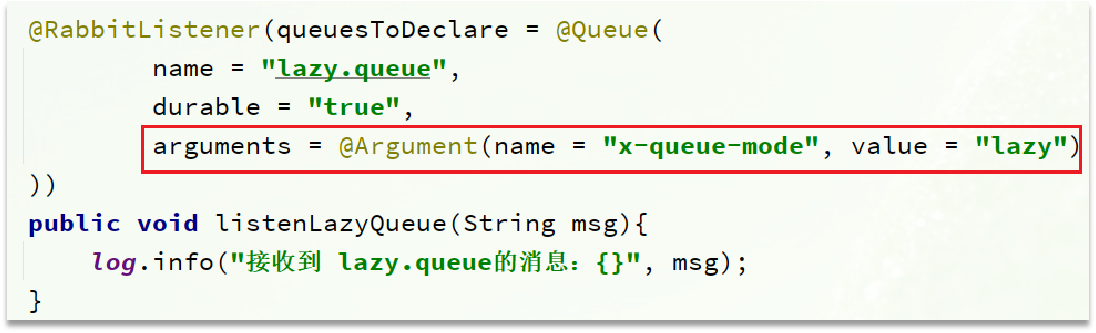
- 在声明队列的时候可以设置属性
保证消费的有序性
RabbitMQ:
- 单个消费者
最简单也是最直接的方法是使用单个消费者来消费队列中的消息。这样可以保证消息按照入队顺序被消费,因为不会有其他消费者干扰这一过程。
1 | // 创建一个队列 |
- 公平调度(Fair Dispatch)
即使在使用单个消费者的情况下,也可以通过设置 basicQos 来限制消费者在同一时间处理的消息数量,从而避免因处理速度差异而导致的顺序错乱。
1 | // 设置预取计数为1 |
Kafka:
消息消费无序的原因:
一个topic的数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序。
topic分区中消息只能由消费者组中的唯一消费者处理,想要顺序的处理Topic的所有消息,那就为消息者只提供一个分区或将相同的业务设置相同的key。
解决方案:
发送消息时指定同一个topic的分区号
发送消息时按照相同的业务设置相同的key(分区默认通过key的hashcode值来选择分区,hash值一致,分区也一致)
代码实现:

RabbitMQ:死信消息
- 消息没有匹配的队列:如果消息发送到一个没有队列绑定的交换机,或者没有匹配的绑定键,那么消息将被丢弃或发送到死信队列。
- 消息被拒绝:如果消费者拒绝了消息,并且设置了
requeue=false,那么消息将被发送到死信队列。 - 消息过期:如果队列设置了过期时间(
x-message-ttl),消息在过期后将被发送到死信队列。
Kafka:消息的存储和清理
Kafka文件存储机制:
topic的数据存储在分区上,分区如果文件过大会分段(segment)存储。每个分段都在磁盘上以索引
xxxx.index和**日志文件xxxx.log**的形式存储,减少单个文件内容的大小,查找数据方便,方便kafka进行日志清理数据清理机制
- 根据消息的保留时间:当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时( 7天)
- 根据topic存储的数据大小:当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。(默认关闭)
Kafka:消息索引的设计
Kafka 的索引设计旨在优化消息查找的速度,同时保持磁盘空间的有效利用。
索引文件结构:Kafka 的索引文件与数据文件紧密相关。每个分区都有若干个段(segment),每个段对应一个 xxxx.log 文件和一个 xxxx.index 文件。以下是索引文件的一些关键特点:
- 索引文件与数据文件关联:每个数据文件都有对应的索引文件,索引文件记录了数据文件中消息的偏移量位置。
- 固定间隔索引:索引文件中记录的不是每一个消息的位置,而是每隔一定数量的消息记录一个索引项。这样可以显著减少索引文件的大小,同时仍然保持较快的查找速度。
索引文件格式:Kafka 的索引文件格式是高效的,主要包括以下几个方面:
- 压缩索引:索引文件通常比数据文件小得多,这有助于节省存储空间。
- 稀疏索引:索引文件记录的是每隔一定数量的消息的位置信息,而不是每个消息的位置信息。这使得索引文件更加紧凑。
- 二进制格式:索引文件是以二进制格式存储的,便于快速读取和解析。
索引更新机制:Kafka 的索引文件在写入新消息时会自动更新,以保持索引的最新状态:
- 动态更新:每当新消息被追加到数据文件时,索引文件也会相应更新,以反映最新的消息位置。
- 预分配空间:Kafka 会预先分配索引文件的空间,以避免频繁的文件扩展操作。
性能优势:Kafka 的索引设计带来了以下性能优势:
- 快速定位:通过索引文件,Kafka 可以迅速定位到消息的位置,从而加快消息的检索速度。
- 高效的存储:索引文件占用的空间相对较小,有助于节省存储资源。
- 可扩展性:索引设计使得 Kafka 能够在高并发环境下保持良好的性能表现。
Kafka:高性能设计
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
顺序读写:磁盘顺序读写,提升读写效率
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
零拷贝:减少上下文切换及数据拷贝
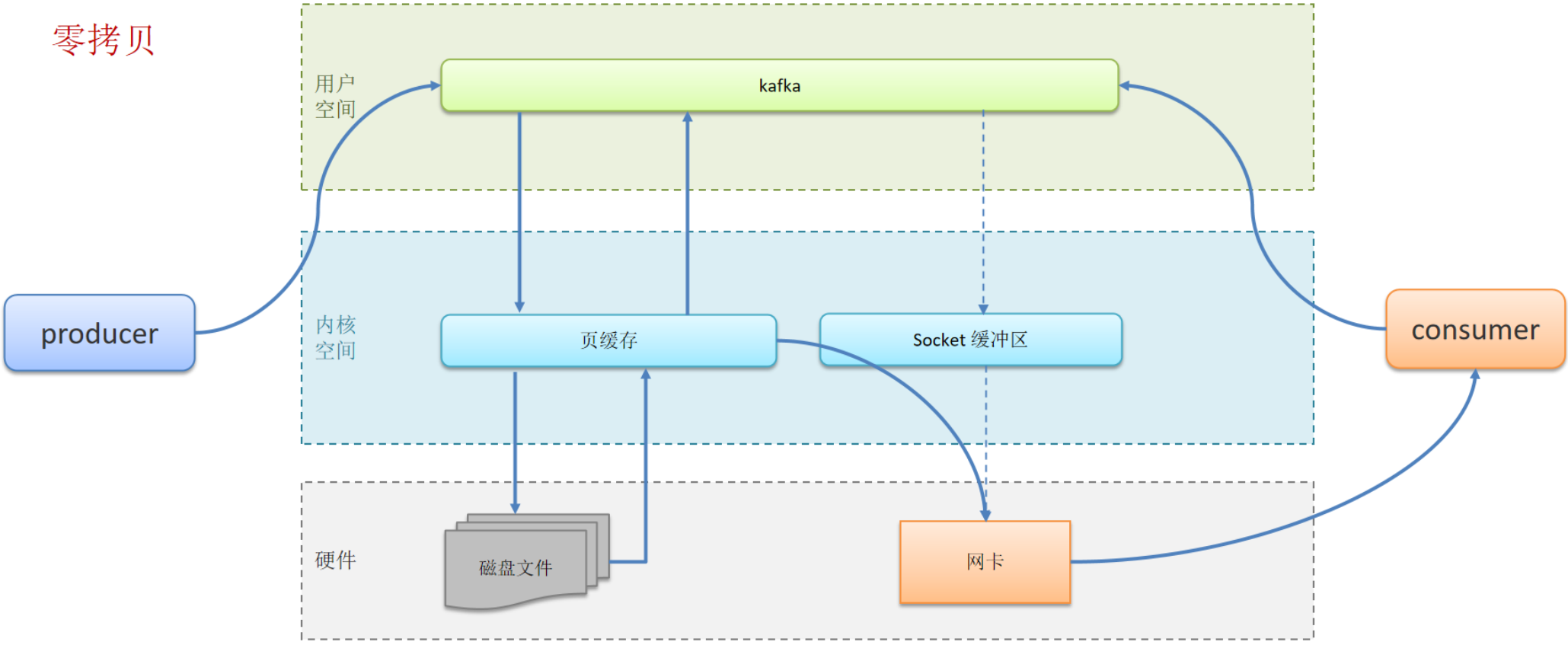
消息压缩:减少磁盘IO和网络IO
分批发送:将消息打包批量发送,减少网络开销
Kafka:处理请求的全流程?
Kafka 处理请求的全流程是一个复杂的多步骤过程,涉及到网络通信、请求解析、元数据管理、消息存储等多个方面。下面详细介绍 Kafka 处理请求的具体流程:
1. 网络层接收请求
当客户端(如生产者或消费者)向 Kafka 发送请求时,请求首先到达 Kafka Broker 的网络层。
- Netty Server:Kafka 使用 Netty 框架来处理网络请求。Netty 是一个高性能、异步事件驱动的网络应用框架,它负责接收客户端的请求并将请求分发给相应的处理器。
- ChannelHandler:Netty 的 ChannelHandler 负责处理每个连接上的读写操作。当请求到达时,Netty 会调用 ChannelHandler 的
read方法来处理请求。
2. 请求解析与分发
请求到达后,Kafka 会对请求进行解析,并根据请求类型将其分发到相应的处理器。
- RequestHeader 解析:Kafka 会首先解析请求头(RequestHeader),从中提取请求的 API 类型和版本号。
- API 请求分发:根据请求头中的信息,Kafka 会将请求分发到相应的 API 层处理器,如
ProduceRequestHandler、FetchRequestHandler等。
3. 元数据校验
在处理请求之前,Kafka 会对请求中涉及的元数据进行校验。
- Topic 存在性检查:Kafka 会检查请求中的 Topic 是否存在。
- 权限校验:Kafka 会对请求进行权限校验,确保客户端有权执行所请求的操作。
4. 数据处理
一旦请求通过了元数据校验,Kafka 会根据请求类型进行相应的数据处理。
对于生产者请求(ProduceRequest)
- 消息写入:生产者请求包含要写入的消息。Kafka 会将消息写入到对应的分区中。
- 日志追加:消息被追加到分区的日志文件中。Kafka 使用追加操作来高效地写入数据。
- 同步到副本:Leader Broker 会将消息同步到副本 Broker,确保数据的一致性和持久性。
- 提交偏移量:一旦消息被成功写入并同步到副本,Leader Broker 会提交偏移量,并返回成功响应给生产者。
对于消费者请求(FetchRequest)
- 消息读取:消费者请求包含要读取的消息的偏移量。Kafka 会根据偏移量从分区中读取消息。
- 消息检索:Kafka 使用索引文件快速定位消息,并将消息读取到内存中。
- 返回消息:将检索到的消息返回给消费者。
5. 响应构建与发送
处理完请求后,Kafka 会构建响应,并通过网络层将响应发送回客户端。
- ResponseHeader 构建:构建响应头,包含响应的状态码等信息。
- 响应序列化:将响应数据序列化为字节数组。
- 响应发送:通过 Netty 的 ChannelHandler 将响应数据发送回客户端。
6. 异常处理
在整个请求处理过程中,Kafka 会捕获并处理可能出现的各种异常情况。
- 重试机制:对于可重试的错误(如网络中断),Kafka 会尝试重新处理请求。
- 错误记录:对于无法处理的错误,Kafka 会记录错误信息,并返回相应的错误码给客户端。
Kafka:Zookeeper 的作用
在 Kafka 的早期版本中,ZooKeeper 是一个不可或缺的组件,它在 Kafka 集群中起到了协调服务的作用。然而,从 Kafka 0.10 版本开始,Kafka 引入了内置的选举机制,减少了对 ZooKeeper 的依赖。尽管如此,ZooKeeper 仍然在 Kafka 中扮演着重要角色,特别是在老版本的 Kafka 中。
ZooKeeper 在 Kafka 中的主要作用
- 元数据管理:
- Broker 注册:在 Kafka 中,Broker 会向 ZooKeeper 注册自己,并维持一个心跳连接。ZooKeeper 用来存储 Broker 的信息,包括其 IP 地址和端口号。
- Topic 元数据:ZooKeeper 存储了所有 Topic 的元数据信息,包括分区(Partition)的数量、Leader Broker 的信息以及副本(Replica)的位置。
- 协调服务:
- Leader 选举:在 Kafka 的早期版本中,当一个分区的 Leader Broker 失效时,ZooKeeper 负责协调新的 Leader 选举过程。从 Kafka 0.10 版本开始,这一过程由 Kafka 自身的选举机制处理。
- Consumer Group 协调:ZooKeeper 负责协调 Consumer Group 的成员关系,包括分配分区给消费者以及处理消费者失效等情况。
- 故障恢复:
- Broker 失效检测:ZooKeeper 监控 Broker 的心跳,如果某个 Broker 长时间没有发送心跳,则认为该 Broker 已经失效,并触发相应的故障恢复机制。
- 分区重新分配:在 Broker 失效或新增 Broker 时,ZooKeeper 可以协助重新分配分区,确保集群的负载均衡。
Kafka 0.10+ 版本的变化
从 Kafka 0.10 版本开始,引入了一些改进来减少对 ZooKeeper 的依赖:
- 内置选举机制:Kafka 引入了内置的选举机制来处理 Leader 选举,减少了对 ZooKeeper 的依赖。
- 简化元数据存储:尽管 Kafka 依然使用 ZooKeeper 来存储一些元数据,但许多元数据已经被移到了 Kafka 自身的存储中。
当前版本(2024 年左右)的趋势
在当前版本中,Kafka 对 ZooKeeper 的依赖已经大大减少,但仍有一些场景下需要 ZooKeeper 的支持:
- Consumer Group 状态管理:虽然 Kafka 可以不依赖 ZooKeeper 来运行,但在 Consumer Group 状态管理方面,ZooKeeper 仍然提供了一种可靠的协调机制。
- 遗留系统兼容性:对于已经在生产环境中运行的老版本 Kafka 集群,ZooKeeper 仍然是必不可少的组件。
Kafka:为什么要摆脱 Zookeeper?
Kafka并没有完全抛弃ZooKeeper,而是在逐渐减少对 ZooKeeper 的依赖。
性能和延迟
- 减少延迟:ZooKeeper 作为集中式协调服务,每次需要进行元数据操作时都需要与 ZooKeeper 交互,这增加了系统的延迟。减少对 ZooKeeper 的依赖可以降低延迟,提高系统的整体性能。
- 提高吞吐量:通过减少对 ZooKeeper 的依赖,Kafka 可以更有效地处理大量的元数据操作,从而提高系统的吞吐量。
可靠性和可用性
- 单点故障:虽然 ZooKeeper 本身是一个分布式的协调服务,但如果 ZooKeeper 集群出现问题,整个 Kafka 集群可能会受到影响。减少对 ZooKeeper 的依赖可以降低单点故障的风险。
- 高可用性:通过内置的选举机制和其他协调功能,Kafka 可以实现更高的可用性,即使没有 ZooKeeper 的支持也能正常运行。
扩展性和管理
- 简化集群管理:减少对 ZooKeeper 的依赖意味着减少了集群管理的复杂性。管理员不需要同时管理 Kafka 和 ZooKeeper 两个独立的服务,降低了运维负担。
- 更好的水平扩展:Kafka 通过内置机制实现水平扩展,可以更好地适应大规模部署的需求,而不需要依赖外部服务来协调扩展。
内置功能增强
- 内置选举机制:Kafka 0.10 版本引入了内置的选举机制,可以更快速地进行 Leader 选举,而不需要通过 ZooKeeper 来协调。
- 元数据存储:Kafka 将更多元数据存储在本地的日志文件中,减少了对外部协调服务的依赖。
社区和生态发展
- 社区推动:Kafka 社区一直在努力改进 Kafka 的核心功能,减少对外部组件的依赖是其中的一个重要方向。
- 生态系统兼容性:随着 Kubernetes 和容器化技术的发展,简化部署和管理流程变得越来越重要。减少对 ZooKeeper 的依赖使得 Kafka 更容易与其他生态系统集成。
实际应用场景
在实际应用中,虽然 Kafka 逐渐减少了对 ZooKeeper 的依赖,但在某些场景下,ZooKeeper 仍然具有重要作用。例如,在 Consumer Group 的协调方面,ZooKeeper 仍然提供了一种可靠的协调机制。此外,在一些遗留系统中,ZooKeeper 依然是必要的组件。
—————————————
集合


Collection 家族
List 接口
- ArrayList:基于动态数组,查询速度快,插入、删除慢。
- LinkedList:基于双向链表,插入、删除快,查询速度慢。
- Vector:线程安全的动态数组,类似于 ArrayList,但开销较大。
Set 接口
- HashSet:基于哈希表,元素无序,不允许重复。
- LinkedHashSet:基于链表和哈希表,维护插入顺序,不允许重复。
- TreeSet:基于红黑树,元素有序,不允许重复。
Queue 接口
- PriorityQueue:基于优先级堆,元素按照自然顺序或指定比较器排序。
- LinkedList:可以作为队列使用,支持 FIFO(先进先出)操作。
Map 接口
- HashMap:基于哈希表,键值对无序,不允许键重复。
- LinkedHashMap:基于链表和哈希表,维护插入顺序,不允许键重复。
- TreeMap:基于红黑树,键值对有序,不允许键重复。
- Hashtable:线程安全的哈希表,不允许键或值为 null。
- ConcurrentHashMap:线程安全的哈希表,适合高并发环境,不允许键或值为 null。
ArrayList
ArrayList 和 LinkedList
底层数据结构
ArrayList 底层是动态数组,支持下标查询,寻址公式是:
baseAddress+i*dataTypeSize,计算下标的内存地址效率较高LinkedList 底层是双向链表
操作数据效率
- ArrayList支持下标查询, LinkedList不支持下标查询
- 查询: ArrayList下标查询的时间复杂度是O(1),两者顺序查询的时间复杂度都是O(n)
- 写操作:
- ArrayList尾部操作,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
- LinkedList头尾操作,时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
内存空间占用
ArrayList底层是数组,内存连续,节省内存
LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
线程不安全
ArrayList和LinkedList都不是线程安全的
如果需要保证线程安全,有两种方案:
在方法内使用局部变量
使用
Collections.synchronizedList1
2List syncArrayList = Collections.synchronizedList(new ArrayList();
List syncLinkedList = Collections.synchronizedList(new LinkedList());
扩容原理
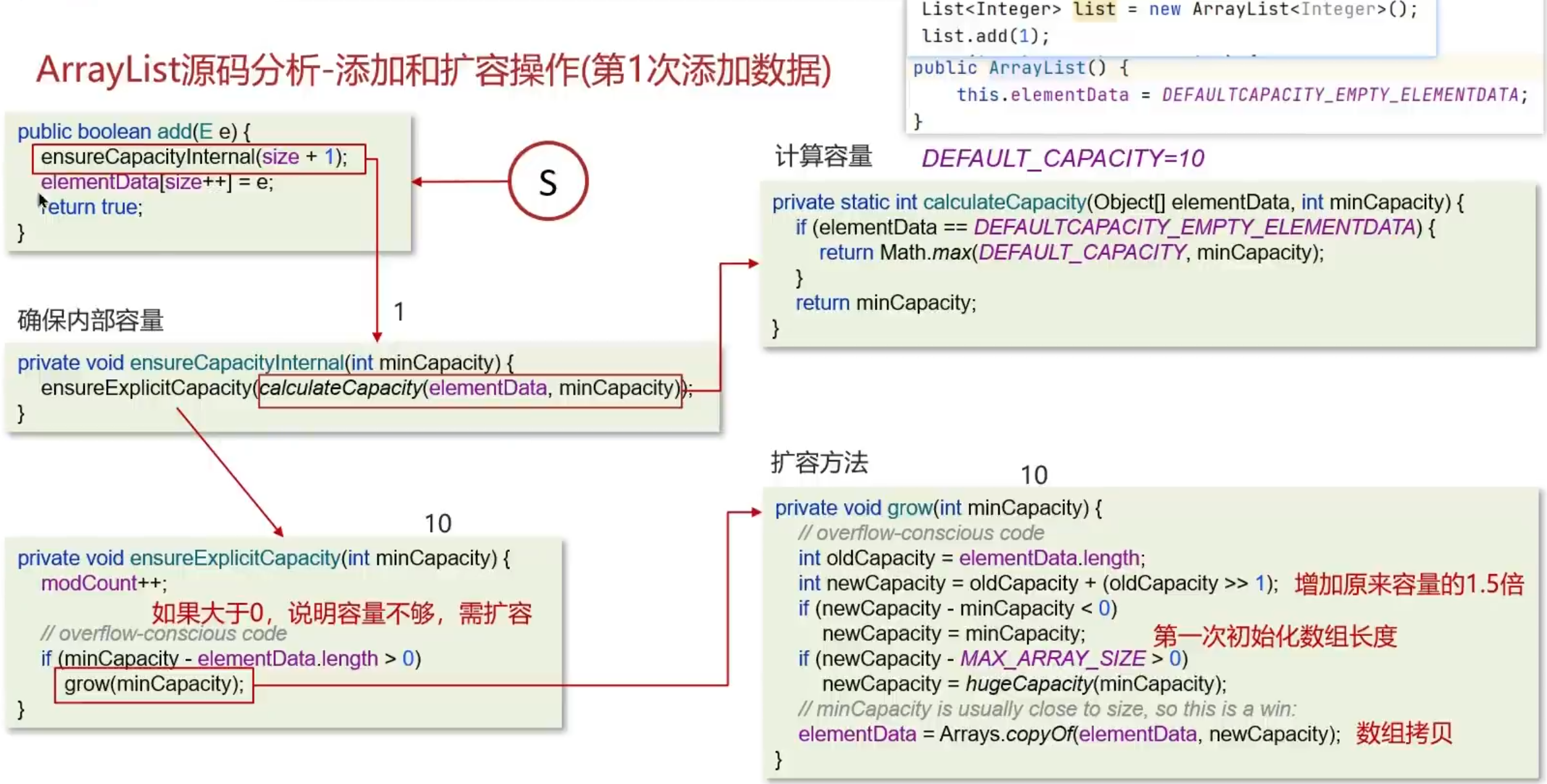

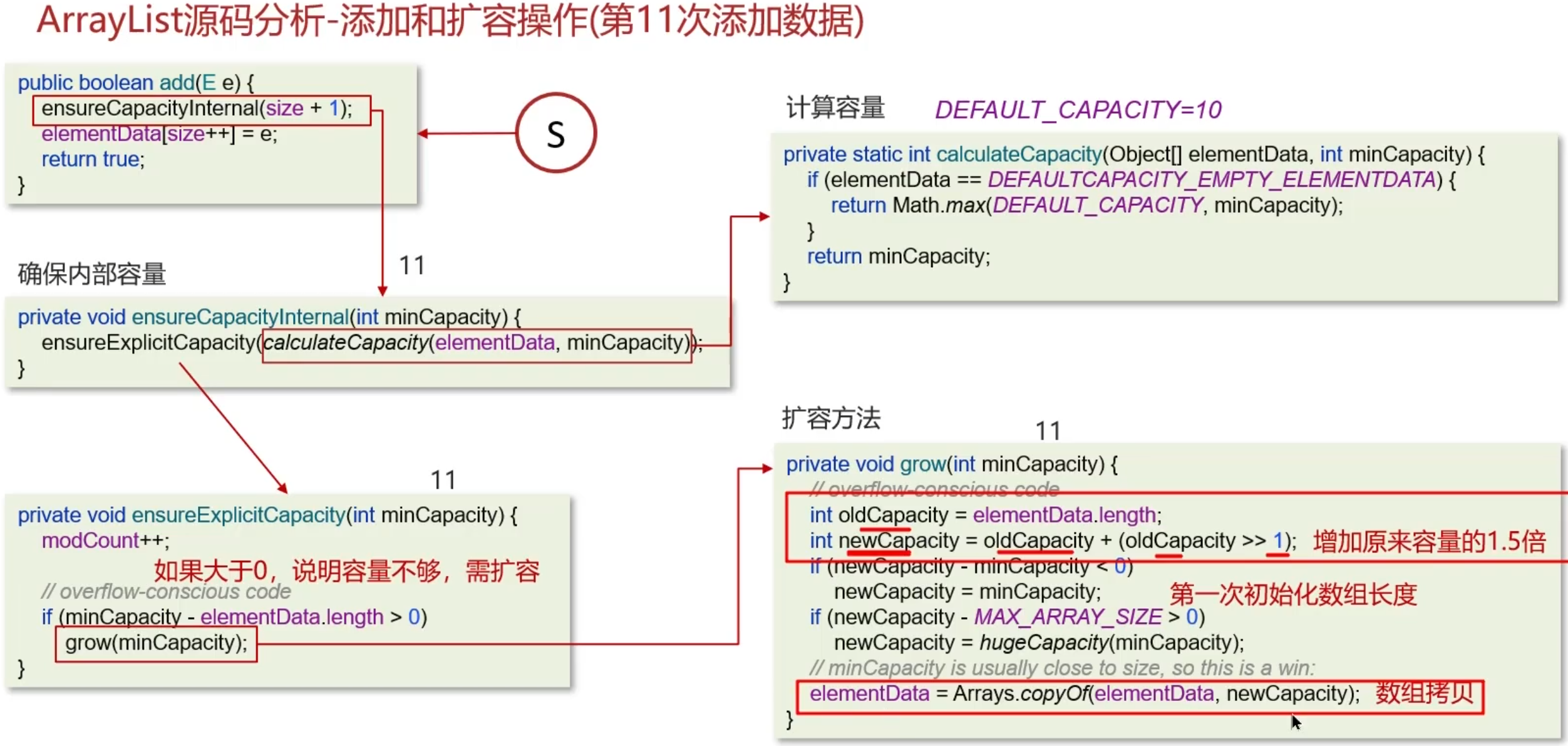
底层实现原理
ArrayList底层是用动态的数组实现的
ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
ArrayList在添加数据的时候
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
- 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上
- 返回添加成功布尔值。
数组和列表之间的转换
1 | //数组转列表 |
HashMap
实现原理
HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树
当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
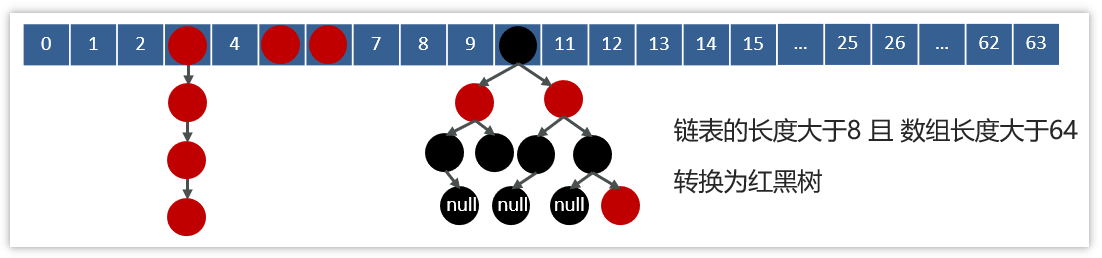
面试官追问:HashMap的jdk1.7和jdk1.8有什么区别
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
添加元素
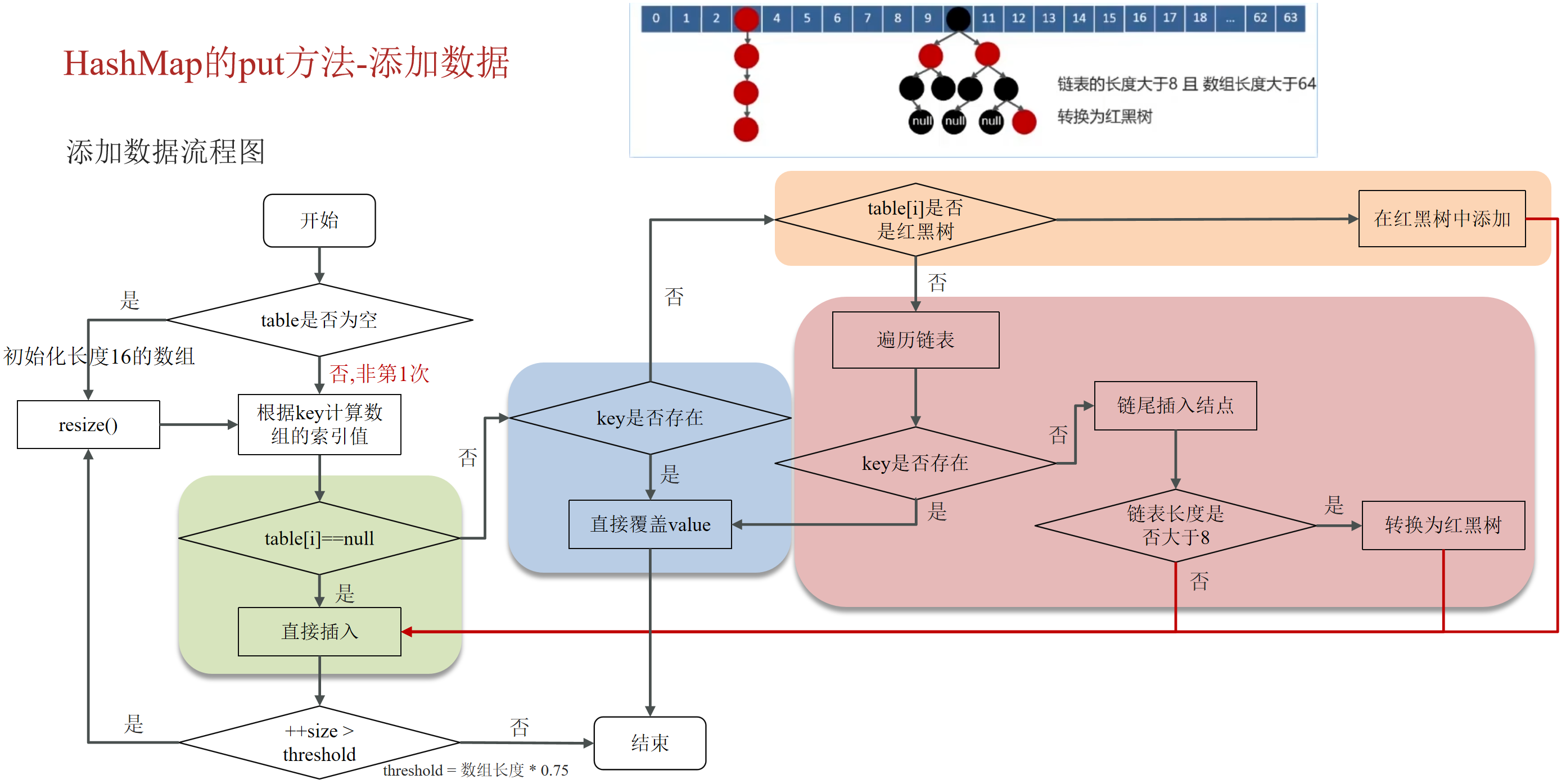
- 判断键值对数组table是否为空或为null,否则执行resize(进行扩容 (初始化)
- 根据键值key计算hash值得到数组索引
- 判断table[i] == null,直接新建节点添加
- 如果table[i] != null,进行判断
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
- 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
- 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,遍历过程中若发现key已经存在直接覆盖value
- 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
扩容原理
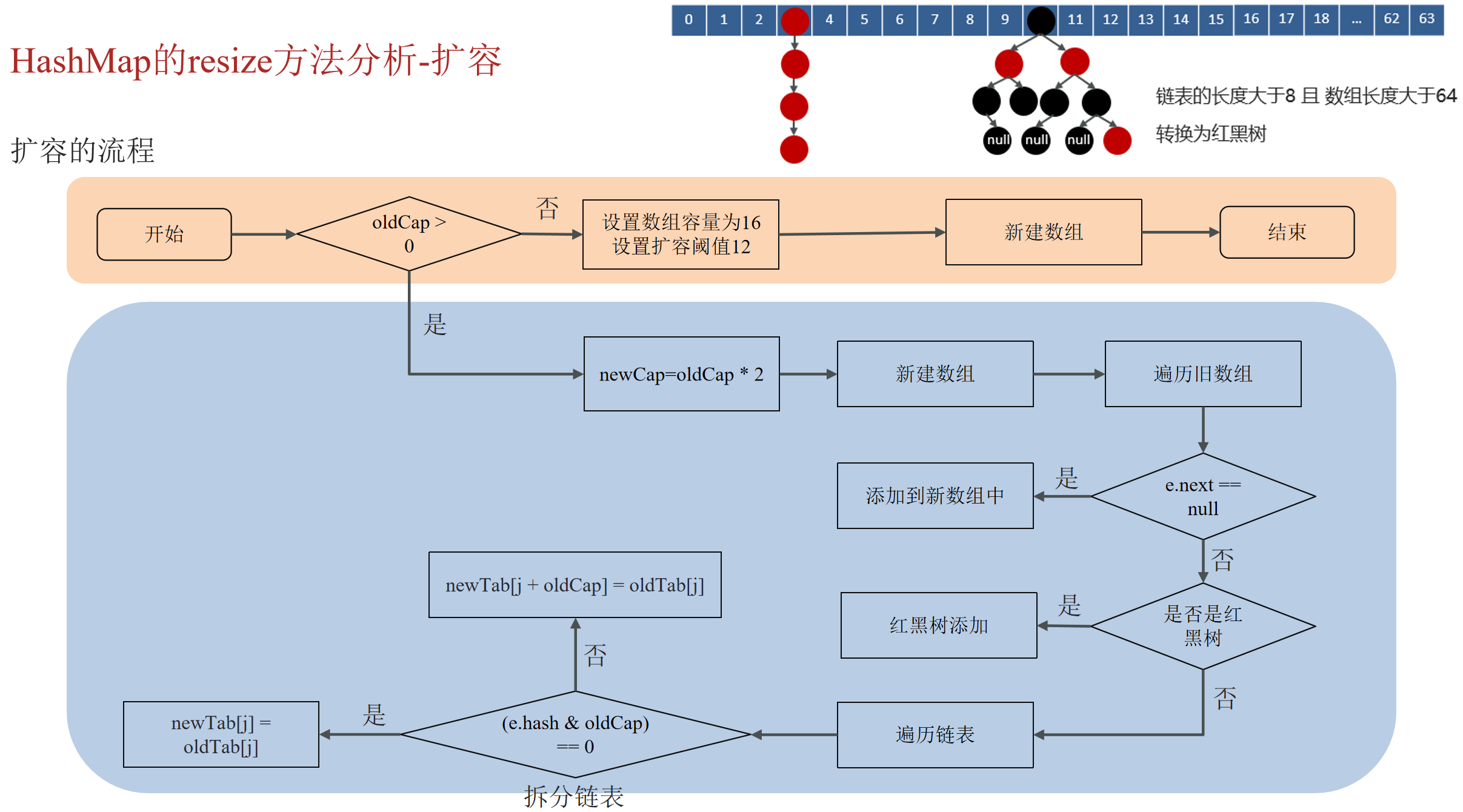
- 在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值 (数组长度*0.75)
- 每次扩容的时候,都是扩容之前容量的2倍
- 扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
- 没有hash冲突的节点,则直接使用e.hash &(newCap-1)计算新数组的索引位置
- 如果是红黑树,走红黑树的添加
- 如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
寻址算法
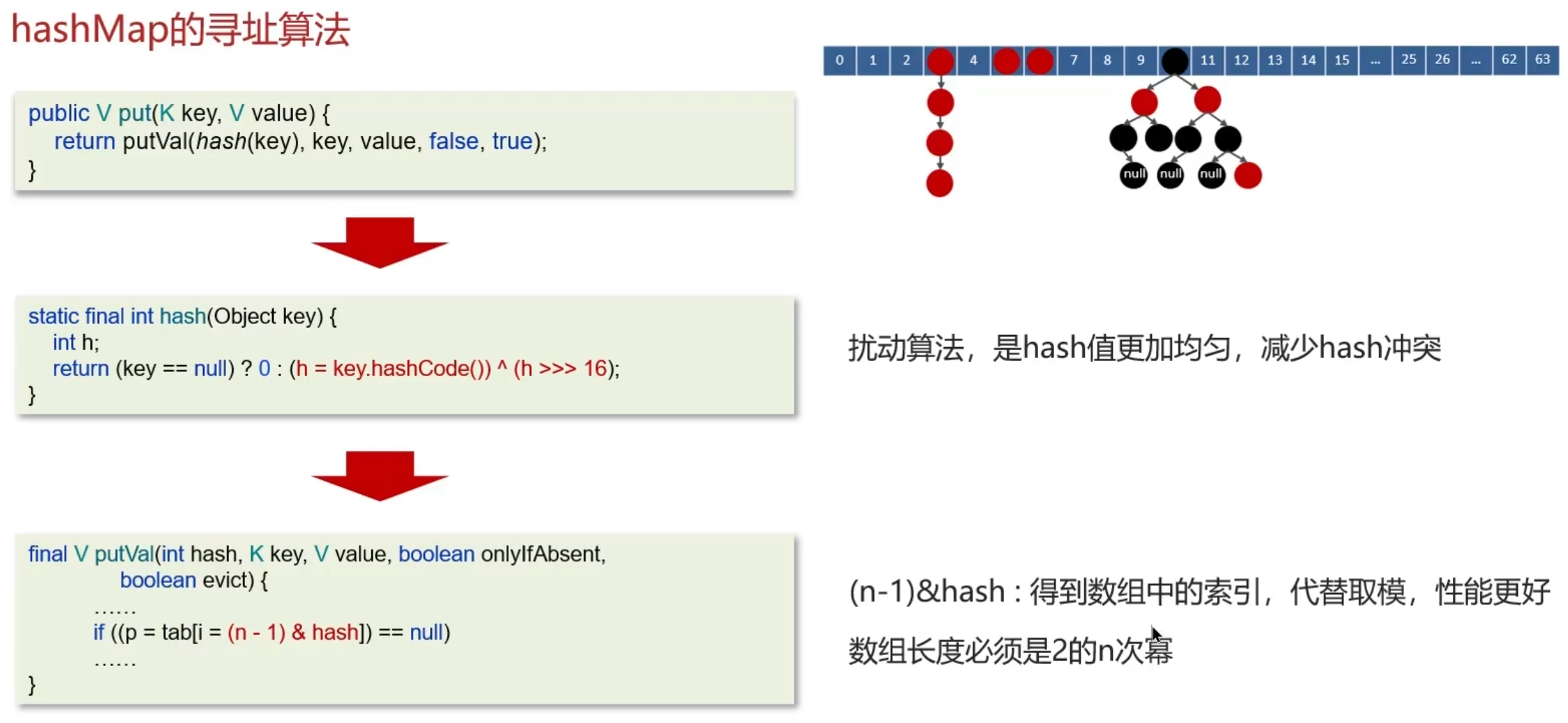
- 计算对象的 hashCode()
- 调用 hash() 方法进行二次哈希, hashcode值右移16位再异或运算,让哈希分布更为均匀
- 最后 (capacity – 1) & hash 得到索引
hashCode() 和 equals() 的重要性
HashMap 的键必须实现 hashCode() 和 equals() 方法。hashCode() 用于计算哈希值,以决定键的存储位置,而 equals() 用于比较两个键是否相同。在 put 操作时,如果两个键的 hashCode() 相同,但 equals() 返回 false,则这两个键会被视为不同的键,存储在同一个桶的不同位置。在 get 操作时,可能会找不到键。
为什么HashMap的长度一定是2的次幂?
- 计算索引时效率更高:位运算的效率高于取模运算(
hash % n),提高了哈希计算的速度。 - 扩容时重新计算索引效率更高: 扩容时只需通过简单的位运算判断是否需要迁移,这减少了重新计算哈希值的开销,提升了 rehash 的效率。(hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap)
Java 1.7的多线程死循环问题(简略版)
原因: Java1.7的HashMap中在数组进行扩容的时候,因为链表是头插法,在进行数据迁移的过程中,有可能导致死循环
比如说,现在有两个线程
线程一:读取到当前的hashmap数据,数据中一个链表,在准备扩容时,线程二介入
线程二:也读取hashmap,直接进行扩容。因为是头插法,链表的顺序会进行颠倒过来。比如原来的顺序是AB,扩容后的顺序是BA,线程二执行结束。
线程一:继续执行的时候就会出现死循环的问题。
线程一先将A移入新的链表,再将B插入到链头,由于另外一个线程的原因,B的next指向了A,所以B->A->B,形成循环。
解决办法:Java 1.8 调整了扩容算法,不再将元素加入链表头(而是保持与扩容前一样的顺序),采用尾插法避免了jdk7中死循环的问题。
Hash家族对比
HashMap 和 HashSet 的区别
- HashSet实现了Set接口,仅存储对象;HashMap实现了 Map接口,存储的是键值对。
- HashSet底层其实是用HashMap实现存储的,HashSet封装了一系列HashMap的方法。依靠HashMap来存储元素值,利用hashMap的key键进行存储,而value值默认为Object对象。所以HashSet也不允许出现重复值,判断标准和HashMap判断标准相同,两个元素的hashCode相等并且通过equals()方法返回true。首先根据hashCode方法计算出对象存放的地址位置,然后使用equals方法比较两个对象是否真的相同

HashMap 和 HashTabe 的区别
在实际开中不建议使用HashTable,在多线程环境下可以使用ConcurrentHashMap类
| 区别 | HashTable | HashMap |
|---|---|---|
| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
| 是否可以为null | Key和value都不能为null | 可以为null |
| hash算法 | key的hashCode() | 二次hash |
| 扩容方式 | 当前容量翻倍 + 1 | 当前容量翻倍 |
| 线程安全 | 同步(synchronized)的,线程安全 | 线程不安全 |
ConcurrentHashMap
底层数据结构
JDK1.7采用分段的数组+链表实现
JDK1.8 采用与HashMap 一样的结构,数组+链表/红黑二叉树
线程安全的原因(1.7 和 1.8 之间的区别)
- 1.7——分段锁:JDK1.7采用Segment分段锁,通过将数据分割成多个段,底层使用的是ReentrantLock。当需要修改某个段内的数据时,只需要锁定该段即可,而不需要锁定整个哈希表。
- 1.8——CAS + synchronized:JDK1.8改用
volatile去同步每个桶上的数据。在put操作时,如果桶上的元素数量小于等于 1,那么就直接用CAS 操作来替换旧元素或者增加新元素;如果桶上的元素数量大于 1,则转为使用synchronized锁来保证线程安全。采用synchronized锁定链表或红黑二叉树的头节点,相对Segment分段锁粒度更细,性能更好。 - 非阻塞迭代算法:允许读写并发,
ConcurrentHashMap的迭代器在读取数据时不会持有锁,因此不会影响其他线程的写操作。 - 懒惰扩容:扩容时
ConcurrentHashMap并不会一次性锁定整个表,而是只锁定需要迁移的部分桶,从而减少了锁的竞争。 - 链表转红黑树:Java 8 中的
ConcurrentHashMap还引入了链表树化的机制。当链表长度达到一定阈值时,链表会被转换为红黑树,从而提高查找效率。这种转换是局部的,只针对那些过长的链表。
插入
- 加锁,但锁的范围仅精确到 bucket 的头节点,而非整个数据结构。
- 这种细粒度的锁机制确保了高并发环境下插入操作的高效执行。
扩容
- 加锁,但仅锁定涉及迁移的头节点。
- 支持多线程并行进行扩容操作,通过CAS操作竞争获取迁移任务,每个线程负责一部分槽位的数据转移。
- 获得任务的线程将原数组中对应链表或红黑树的数据迁移到新数组,进一步提升了扩容时的并发处理能力。
查找
- 非阻塞,不加锁,直接访问,保证了快速响应。
- 在扩容期间也不中断查找,若槽未迁移,则直接从旧数组读取;若已迁移完成,通过扩容线程设置的转发节点指引,从新数组中定位数据,确保了查找操作的连续性和高效性。
—————————————
并发

并发概念
并发、并行的区别
- 并发:两个及两个以上的作业在同一 时间段 内执行。
- 并行:两个及两个以上的作业在同一 时刻 执行。
最关键的点是:是否是 同时 执行。
同步、异步的区别
- 同步:发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
- 异步:调用在发出之后,不用等待返回结果,该调用直接返回。
进程、线程、协程
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。
系统运行一个程序即是一个进程从创建,运行到消亡的过程。
线程与进程相似,但线程是一个比进程更小的执行单位。
一个进程在其执行的过程中可以产生多个线程。
多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈。
协程(Coroutine)是一种轻量级的线程,它允许在执行中暂停并在之后恢复执行,而无需阻塞线程。
与线程相比,协程是用户态调度,效率更高,因为它不涉及操作系统内核调度。
协程的特点:
- 轻量级:与传统线程不同,协程在用户态切换,不依赖内核态的上下文切换,避免了线程创建、销毁和切换的高昂成本。
- 非抢占式调度:协程的切换由程序员控制,可以通过显式的
yield或await来暂停和恢复执行,避免了线程中断问题。 - 异步化编程:协程可以让异步代码写得像同步代码一样,使代码结构更加简洁清晰。
Java 一开始没有原生支持协程,但在 Java 19 中通过 Project Loom 引入了虚拟线程(Virtual Threads),最终在 Java 21 中确认。它提供了类似协程的功能。虚拟线程可以被认为是 Java 对协程的一种实现,虽然实现原理与传统协程略有不同,但它实现了高效并发。
示例代码:
1)创建虚拟线程
1 | public class VirtualThreadDemo { |
2)虚拟线程执行并发任务
1 | public class VirtualThreadExecutorDemo { |
3) 与同步 I/O 的结合
1 | public class VirtualThreadWithIO { |
进程、线程的区别
- 线程是进程划分成的更小的运行单位。
- 各进程是独立的,而各线程则不一定,
- 同一进程中的线程极有可能会相互影响。
- 线程执行开销小,但不利于资源的管理和保护;而进程正相反。
协程、线程的区别
调度方式:
- 线程:由操作系统调度,切换线程时会涉及上下文切换和内核态的开销。
- 协程:由程序调度,在用户态切换,没有上下文切换的开销,性能更高。
阻塞与非阻塞:
- 线程:通常采用阻塞模型(例如,I/O 操作会阻塞当前线程)。
- 协程:是非阻塞的,I/O 等操作会挂起协程,而不是整个线程,因此不会阻塞其他协程的执行。
资源占用:
- 线程:每个线程需要分配栈空间,且栈大小固定,导致线程资源消耗较大。
- 协程:协程的栈空间可以动态增长,内存开销远小于线程。
协程的应用场景
- 高并发服务:协程特别适合处理大量并发请求的服务,例如 Web 服务、微服务架构等。
- 异步 I/O 操作:协程能够有效处理异步 I/O 操作而不阻塞主线程,提高 I/O 密集型应用的性能。
- 游戏开发:协程常用于游戏开发中的脚本和动画控制,因为协程提供了暂停和恢复执行的能力,能够实现复杂的游戏逻辑。
乐观锁、悲观锁
乐观锁:总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(版本号机制或 CAS 算法)。
悲观锁:悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
像 Java 中 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现。
如何实现乐观锁
- 版本号机制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
- CAS 算法
CAS:Compare And Swap(比较与交换) ,用于实现乐观锁,保证在无锁情况下保证线程操作共享数据的原子性,被广泛应用于各大框架中。CAS 的思想是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。
CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
- 存在的问题:ABA 问题、循环时间长开销大
- 底层:依赖于一个 Unsafe 类来直接调用操作系统底层的 CAS 指令
公平锁、非公平锁
- 公平锁 : 锁被释放之后,先申请的线程先得到锁。性能较差一些,因为公平锁为了保证时间上的绝对顺序,上下文切换更频繁。
- 非公平锁:锁被释放之后,后申请的线程可能会先获取到锁,是随机或者按照其他优先级排序的。性能更好,但可能会导致某些线程永远无法获取到锁。
共享锁、 独占锁
- 共享锁:一把锁可以被多个线程同时获得。
- 独占锁:一把锁只能被一个线程获得。
Java内存模型
什么是 Java 的 happens-before 规则?
happens-before 规则定义了多线程程序中操作的可见性和顺序性。它通过指定一系列操作之间的顺序关系,确保线程间的操作是有序的,避免由于重排序或线程间数据不可见导致的并发问题。
happens-before 规则的主要内容:
1)程序次序规则:在一个线程中,代码的执行顺序是按照程序中的书写顺序执行的,即一个线程内,前面的操作 happens-before 后面的操作。
2)监视器锁规则:一个锁的解锁(unlock)操作 happens-before 后续对这个锁的加锁(lock)操作。也就是说,在释放锁之前的所有修改在加锁后对其他线程可见。
3)volatile 变量规则:对一个 volatile 变量的写操作 happens-before 后续对这个 volatile 变量的读操作。它保证 volatile 变量的可见性,确保一个线程修改 volatile 变量后,其他线程能立即看到最新值。
4) 线程启动规则:线程 A 执行 Thread.start() 操作后,线程 B 中的所有操作 happens-before 线程 A 的 Thread.start() 调用。
5)线程终止规则:线程 A 执行 Thread.join() 操作后,线程 B 中的所有操作 happens-before 线程 A 从 Thread.join() 返回。
6)线程中断规则:对线程的 interrupt() 调用 happens-before 线程检测到中断事件(通过 Thread.interrupted() 或 Thread.isInterrupted())。
7)对象的构造规则:对象的构造完成(即构造函数执行完毕) happens-before 该对象的 finalize() 方法调用。
什么是 Java 中的指令重排?
指令重排是 Java 编译器和处理器为了优化性能,在保证单线程程序语义不变的情况下,对指令执行顺序进行调整的过程。在多线程环境下,指令重排可能导致线程之间的操作出现不同步或不可见的现象,因此 Java 提供了内存模型(JMM)和相关机制(如 volatile 和 synchronized)来限制这种行为,确保并发操作的正确性。
主要原因:
- 编译器优化:编译器会在不影响单线程程序语义的情况下重排序代码,以提升执行效率。
- 处理器优化:现代处理器会进行指令流水线优化,允许多条指令并行执行或重排序。
重排序的影响:
- 单线程情况下不会影响程序执行结果。
- 多线程情况下,指令重排可能导致线程之间的数据不一致问题,影响并发的正确性。
指令重排的三种类型
- 编译器重排:编译器在生成字节码时,根据优化策略调整代码的顺序,前提是不会改变程序的单线程语义。
- CPU 重排:处理器执行指令时,可能会对指令顺序进行调整,以充分利用 CPU 资源,例如指令流水线和多核并行执行。
- 内存系统重排:不同线程访问共享内存时,内存系统可能会对内存操作顺序进行调整。
volatile 的作用
- 保证线程间的可见性:用 volatile 修饰共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见。
- 禁止进行指令重排序:用 volatile 修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果。
如何理解Java中的原子性、可见性、有序性?
原子性(Atomicity)
原子性指的是一个操作或一系列操作要么全部执行成功,要么全部不执行,期间不会被其他线程干扰。
- 原子类与锁:Java 提供了
java.util.concurrent.atomic包中的原子类,如AtomicInteger,AtomicLong,来保证基本类型的操作具有原子性。此外,synchronized关键字和Lock接口也可以用来确保操作的原子性。 - CAS(Compare-And-Swap):Java 的原子类底层依赖于 CAS 操作来实现原子性。CAS 是一种硬件级的指令,它比较内存位置的当前值与给定的旧值,如果相等则将内存位置更新为新值,这一过程是原子的。CAS 可以避免传统锁机制带来的上下文切换开销。
可见性(Visibility)
可见性指的是当一个线程修改了某个共享变量的值,其他线程能够立即看到这个修改。
- volatile:
volatile关键字是 Java 中用来保证可见性的轻量级同步机制。当一个变量被声明为volatile时,所有对该变量的读写操作都会直接从主内存中进行,从而确保变量对所有线程的可见性。 - synchronized:
synchronized关键字不仅可以保证代码块的原子性,还可以保证进入和退出synchronized块的线程能够看到块内变量的最新值。每次线程退出synchronized块时,都会将修改后的变量值刷新到主内存中,进入该块的线程则会从主内存中读取最新的值。 - Java Memory Model(JMM):JMM 规定了共享变量在不同线程间的可见性和有序性规则。它定义了内存屏障的插入规则,确保在多线程环境下的代码执行顺序和内存可见性。
有序性(Ordering)
有序性指的是程序执行的顺序和代码的先后顺序一致。但在多线程环境下,为了优化性能,编译器和处理器可能会对指令进行重排序。
- 指令重排序:为了提高性能,处理器和编译器可能会对指令进行重排序。尽管重排序不会影响单线程中的执行结果,但在多线程环境下可能会导致严重的问题。例如,经典的双重检查锁定(DCL)模式在没有正确同步的情况下,由于指令重排序可能导致对象尚未完全初始化就被另一个线程访问。
- happens-before 原则:JMM 定义了
happens-before规则,用于约束操作之间的有序性。如果一个操作Ahappens-before 操作B,那么A的结果对于B是可见的,且A的执行顺序在B之前。这为开发者提供了在多线程环境中控制操作顺序的手段。 - 内存屏障:
volatile变量的读写操作会在指令流中插入内存屏障,阻止特定的指令重排序。对于volatile变量的写操作,会在写操作前插入一个 StoreStore 屏障,防止写操作与之前的写操作重排序;在读操作之后插入一个 LoadLoad 屏障,防止读操作与之后的读操作重排序。
并发安全
使用多线程可能带来的问题
并发编程的目的就是为了能提高程序的执行效率进而提高程序的运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
线程安全和不安全
线程安全和不安全是在多线程环境下对于同一份数据的访问是否能够保证其正确性和一致性的描述。
- 线程安全:在多线程环境下,对于同一份数据,不管有多少个线程同时访问,都能保证这份数据的正确性和一致性。
- 面试鸭:线程安全是指多个线程访问某一共享资源时,能够保证一致性和正确性,即无论线程如何交替执行,程序都能够产生预期的结果,且不会出现数据竞争或内存冲突。在 Java 中,线程安全的实现通常依赖于同步机制和线程隔离技术。
- 线程不安全:在多线程环境下,对于同一份数据,多个线程同时访问时可能会导致数据混乱、错误或者丢失。
常用的线程安全措施
- 同步锁:通过
synchronized关键字或ReentrantLock实现对共享资源的同步控制。 - 原子操作类:Java 提供的
AtomicInteger、AtomicReference等类确保多线程环境下的原子性操作。 - 线程安全容器:如
ConcurrentHashMap、CopyOnWriteArrayList等,避免手动加锁。 - 局部变量:线程内独立的局部变量天然是线程安全的,因为每个线程都有自己的栈空间(线程隔离)。
- ThreadLocal:类似于局部变量,属于线程本地资源,通过线程隔离保证了线程安全。
- CAS(Compare and Swap)操作:CAS 操作是硬件级别的原子操作,它包含三个操作数:内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置的值更新为新值。否则,操作失败,处理器不做任何事情。在 Java 中,CAS 操作通过
Unsafe类的compareAndSwapInt方法来实现。Unsafe类提供了对底层内存的直接访问和修改能力,这是一个非公开的类,通常通过反射来获取它的实例。
怎么保证多线程的执行安全?
导致并发程序出现问题的根本原因和解决办法:
原子性synchronized、lock:一个线程在CPU中操作不可暂停,也不可中断,要不执行完成,要不不执行
内存可见性volatile、synchronized、lock:让一个线程对共享变量的修改对另一个线程可见
有序性volatile:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的
如何判断方法内局部变量是否线程安全?
两条原则:
- 如果局部变量没有逃离方法的作用范围,它是线程安全的。
- 如果局部变量引用了对象,并逃离方法的作用范围,它是线程不安全的。
示例代码:
1 | public static void main(String[] args) { |
如何使线程内局部变量线程安全?
- 直接用线程安全的类
- 确保局部变量线程安全
ABA 问题
ABA 问题是指在多线程环境下,某个变量的值在一段时间内经历了从 A 到 B 再到 A 的变化,这种变化可能被线程误认为值没有变化,从而导致错误的判断和操作。ABA 问题常发生在使用 CAS(Compare-And-Swap) 操作的无锁并发编程中。
解决 ABA 问题的方法
1)引入版本号:
最常见的解决 ABA 问题的方法是使用版本号。在每次更新一个变量时,不仅更新变量的值,还更新一个版本号。CAS 操作在比较时,除了比较值是否一致,还比较版本号是否匹配。这样,即使值回到了初始值,版本号的变化也能检测到修改。
Java 中的 AtomicStampedReference 提供了版本号机制来避免 ABA 问题。
**2)使用 AtomicMarkableReference**:
这是另一种类似的机制,它允许在引用上标记一个布尔值,帮助区分是否发生了特定变化。虽然不直接使用版本号,但标记位可以用来追踪状态的变化。
并发锁
锁的种类及使用场景
- 独占锁(Exclusive Lock):如
synchronized和ReentrantLock,同一时间只允许一个线程持有锁,适合写操作较多的场景。 - 读写锁(ReadWriteLock):允许多个线程并发读,但写时需要独占锁,适合读多写少的场景。
- 乐观锁和悲观锁:悲观锁假设会有并发冲突,每次操作都加锁;而乐观锁假设不会有冲突,通过版本号或 CAS 实现冲突检测。
如何优化 Java 中的锁的使用?
主要有以下两种常见的优化方法:
1)减小锁的粒度(使用的时间):
- 尽量缩小加锁的范围,减少锁的持有时间。即在必要的最小代码块内使用锁,避免对整个方法或过多代码块加锁。
- 使用更细粒度的锁,比如将一个大对象锁拆分为多个小对象锁,以提高并行度(参考
HashTable和ConcurrentHashMap的区别)。 - 对于读多写少的场景,可以使用读写锁(
ReentrantReadWriteLock)代替独占锁。
2)减少锁的使用:
- 通过无锁编程、CAS(Compare-And-Swap)操作和原子类(如
AtomicInteger、AtomicReference)来避免使用锁,从而减少锁带来的性能损耗。 - 通过减少共享资源的使用,避免线程对同一个资源的竞争。例如,使用局部变量或线程本地变量(
ThreadLocal)来减少多个线程对同一资源的访问。
读写锁
读写锁允许多个线程同时读取共享资源,而在写操作时确保只有一个线程能够进行写操作(读读操作不互斥,读写互斥、写写互斥)。
读写锁适合读多写少的场景,因为它提高了系统的并发性和性能。
Java 中的 ReadWriteLock 是通过 ReentrantReadWriteLock 实现的,它提供了以下两种锁模式:
- 读锁(共享锁):允许多个线程同时获取读锁,只要没有任何线程持有写锁。适合读操作频繁而写操作较少的场景。
- 写锁(独占锁):写锁是独占的,当有线程持有写锁时,其他线程既不能获取写锁,也不能获取读锁。写锁用于保证写操作的独占性,防止数据不一致。
读写锁的原理
- 共享与独占:读锁是共享锁,多个线程可以同时获取;而写锁是独占锁,在持有写锁期间,其他线程不能获取写锁或读锁。
- 锁降级:
ReentrantReadWriteLock支持锁降级,即持有写锁的线程可以直接获取读锁,从而在写操作完成后不必完全释放锁,但不支持锁升级(即不能从读锁升级为写锁)。 - 公平锁与非公平锁:
ReentrantReadWriteLock提供了公平和非公平模式。在公平模式下,线程将按照请求的顺序获取锁;而在非公平模式下,线程可能会插队,提高吞吐量。 - 读写锁也是基于 AQS 实现的,再具体点的实现就是将 state 分为了两部分,高16bit用于标识读状态、低16bit标识写状态。
synchronized 的锁升级
| 锁形式 | 使用情况 | 性能 | 描述 |
|---|---|---|---|
| 重量级锁 | 多线程竞争锁 | 性能比较低 | 底层使用的Monitor实现,涉及到了用户态和[内核态](#Kernel Mode)的切换、进程的上下文切换,成本较高。 |
| 轻量级锁 | 不同线程交替持有锁 | 相对重量级锁性能提升很多 | 线程加锁的时间是错开的(也就是没有竞争),可以使用轻量级锁来优化。轻量级修改了对象头的锁标志。通过CAS操作保证原子性。 |
| 偏向锁 | 锁只被一个线程持有 | 性能最好 | 线程第一次获得锁时进行一次CAS操作,之后该线程再获取锁,只需要判断自己是否持有锁 |
- 无锁状态(Unlocked):在对象首次被访问时,默认是没有加锁的。此时,多个线程可以并行地访问对象的方法而无需阻塞。
- 偏向锁(Biased Locking):当第一个线程访问该对象的
synchronized方法或代码块时,JVM会将对象头中的Mark Word标记为偏向锁的状态,并记录下当前线程的信息。 - 锁撤销(Revocation):如果持有偏向锁的线程长时间未访问该对象,或者有其他线程试图获取锁,那么JVM会撤销偏向锁,并将对象的状态恢复到无锁状态。此时,任何线程都可以再次竞争锁。
- 轻量级锁(Lightweight Locking):当第二个线程尝试访问该对象的
synchronized方法时,JVM会尝试使用轻量级锁。轻量级锁是由每个线程在其本地栈中维护的一个名为Lock Record的数据结构来实现的。当线程请求锁时,它会在本地栈中创建一个Lock Record,并尝试使用CAS操作将对象头中的Mark Word更新为指向这个Lock Record的指针。如果CAS操作成功,那么该线程获得了锁;否则,如果对象已经被其他线程锁定,那么当前线程就会进入下一个阶段。 - 重量级锁(Heavyweight Locking):如果轻量级锁的CAS操作失败,或者轻量级锁尝试了多次仍然无法获得锁,那么JVM会将轻量级锁升级为重量级锁。重量级锁是通过操作系统提供的互斥锁来实现的,这意味着线程在获取锁之前必须挂起,而在释放锁之后才能恢复执行。这会导致更高的性能开销,因此只有在确实需要的时候才会升级为重量级锁。
synchronized 的实现原理
synchronized 实现原理依赖于 JVM 的 Monitor(监视器锁) 和 对象头(Object Header)。
在HotSpot虚拟机中,对象在内存中存储的布局可分为3块区域:对象头(Header)、实例数据(Instance Data)、对齐填充。
当 synchronized 修饰在方法或代码块上时,会对特定的对象或类加锁,从而确保同一时刻只有一个线程能执行加锁的代码块。
- synchronized 修饰方法:方法的常量池会增加一个
ACC_SYNCHRONIZED标志,当某个线程访问这个方法检查是否有ACC_SYNCHRONIZED标志,若有则需要获得监视器锁才可执行方法,此时就保证了方法的同步。 - synchronized 修饰代码块:会在代码块的前后插入
monitorenter和monitorexit字节码指令。可以把monitorenter理解为加锁,monitorexit理解为解锁。
Monitor
Monitor实现的锁属于重量级锁,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低。
在JDK 1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。
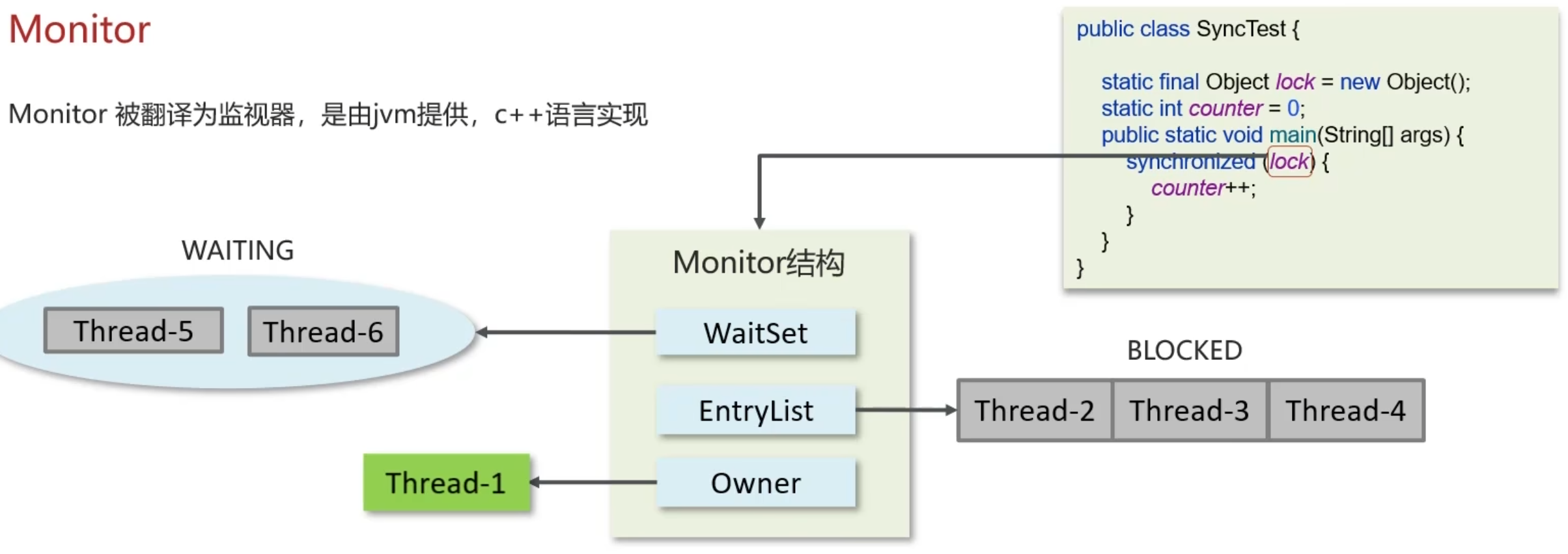
- Owner:存储当前获取锁的线程的,只能有一个线程可以获取
- EntryList:关联没有抢到锁的线程,处于Blocked状态的线程
- WaitSet:关联调用了wait方法的线程,处于Waiting状态的线程
面试:说说AQS吧?
参考回答:
AQS 将一些操作封装起来,比如入队等基本方法,暴露出方法,便于其他相关 JUC 锁的使用。
比如 ReentrantLock、CountDownLatch、Semaphore 等等。
简单来说 AQS 就是起到了一个抽象、封装的作用,将一些排队、入队、加锁、中断等方法提供出来,具体加锁时机、入队时机等都需要实现类自己控制。
然后面试官会引申问你具体 ReentrantLock 的实现原理是怎样的呢?
AQS的工作机制
AQS(Abstract Queued Synchronizer),是Java中的一个抽象类,提供了构建锁和其他同步组件的基础框架,用于同步多线程中的队列,ReentrantLock、Semaphore都是基于AQS实现的。
谈论AQS是公平锁还是非公平锁并不准确,应当说是AQS是一个支持构建公平锁和非公平锁两种模式的同步组件。
工作机制:
在AQS中维护了一个使用了volatile修饰的state属性来表示资源的状态,0表示无锁,1表示有锁,修改state时使用CAS操作保证原子性,确保只能有一个线程修改成功,修改失败的线程将会进入队列中等待。如果队列中的有一个线程修改成功了state为1,则当前线程就相等于获取了资源。

AQS内部维护了一个 FIFO 的等待队列,类似于 Monitor 的 EntryList,用于管理等待获取同步状态的线程。每个节点(Node)代表一个等待的线程,节点之间通过 next 和 prev 指针链接。
1
2
3
4
5
6
7
8
9
10static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread; // 保存等待的线程
Node nextWaiter;
.....
}当一个线程获取同步状态失败时,它会被添加到等待队列中,并自旋等待或被阻塞,直到前面的线程释放同步状态。
独占模式和共享模式
- 独占模式:只有一个线程能获取同步状态,例如 ReentrantLock。
- 共享模式:多个线程可以同时获取同步状态,例如 Semaphore 和 ReadWriteLock。
AQS支持实现多种类型的锁,包括公平锁和非公平锁。
- 新的线程与队列中的线程共同来抢资源,是非公平锁
- 新的线程到队列中等待,只让队列中的head线程获取锁,是公平锁
ReentrantLock
ReentrantLock是基于AQS实现的一个互斥锁,它可以被配置为公平锁或非公平锁,通过构造函数的参数来决定。
ReentrantLock相对于synchronized它具备以下特点:
- 可中断
- 可设置超时时间
- 可设置公平锁
- 支持多个条件变量
- 与synchronized一样,都支持重入
ReentrantLock 的结构
ReentrantLock主要利用CAS+AQS队列来实现。它支持公平锁和非公平锁,两者的实现类似,构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁。公平锁体现在按照先后顺序获取锁,非公平体现在不在排队的线程也可以抢锁
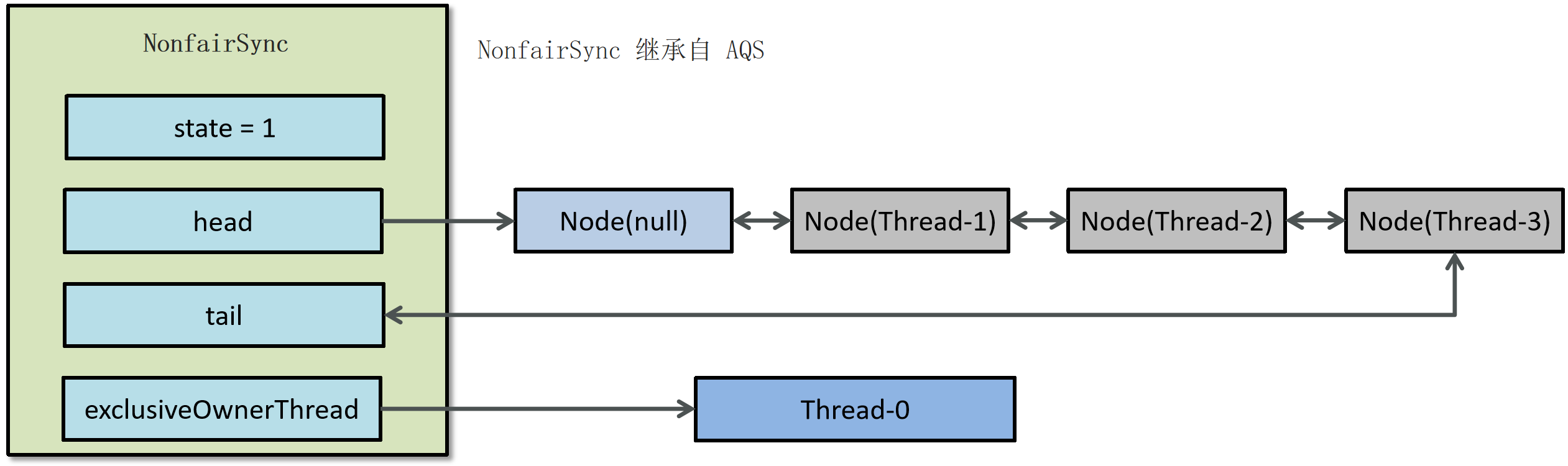
ReentrantLock 的工作原理
- 线程来抢锁后使用CAS操作修改
state状态,修改状态成功为1,则让exclusiveOwnerThread属性指向当前线程,获取锁成功 - 假如修改状态失败,则会进入双向队列中等待,
head指向双向队列头部,tail指向双向队列尾部 - 当
exclusiveOwnerThread为null的时候,则会唤醒在双向队列中等待的线程

synchronized 与 AQS 的区别
| 区别 | AQS | synchronized |
|---|---|---|
| 实现语言 | Java 语言实现 | C++ 语言实现 |
| 类型 | 悲观锁,手动开启和关闭 | 悲观锁,自动释放锁 |
| 性能 | 锁竞争激烈的情况下,提供了多种解决方案 | 锁竞争激烈都是重量级锁,性能差 |
synchronized 与 Lock 有什么区别 ?
| 特点 | synchronized | Lock |
|---|---|---|
| 语法层面 | 关键字,源码在 JVM 中,用 C++ 实现 使用时,退出同步代码块锁会自动释放 |
接口,源码由 JDK 提供,用 Java 语言实现 使用时,需要手动调用 unlock 方法释放锁 |
| 功能层面 | 悲观锁,具备互斥、同步、锁重入功能 | 悲观锁,具备互斥、同步、锁重入功能 提供了更多功能,如获取等待状态、公平锁、可打断、可超时、多条件 Condition变量有适合不同场景的实现,如 ReentrantLock,ReentrantReadWriteLock |
| 性能层面 | 在没有竞争时,做了很多优化,如偏向锁、轻量级锁 | 在竞争激烈时,通常会提供更好的性能 |
synchronized 与 ReentrantLock 有什么区别 ?
| 特性 | synchronized | ReentrantLock |
|---|---|---|
| 类别 | Java关键字 | Java中的一个类 |
| 锁类型 | JVM层面的锁 | Java API层面的锁 |
| 加锁/解锁方式 | 自动加锁与释放锁 | 需要手动加锁与释放锁 |
| 获取当前线程是否上锁 | 不可获取 | 可获取 (isHeldByCurrentThread()) |
| 公平性 | 默认非公平锁 | 公平锁或非公平锁 |
| 中断支持 | 不可中断 | 可中断 (tryLock(), lockInterruptibly()) |
| 锁的对象 | 锁的是对象,锁信息保存在对象头中 | int类型的state标识来标识锁的状态 |
| 锁升级 | 底层有锁升级过程 | 没有锁升级过程 |

-
并发工具类
AtomicInteger 的实现原理
AtomicInteger 的实现基于 CAS(Compare and Swap)操作,这是一种无锁的同步算法。
实现原理:
AtomicInteger的value字段是一个int变量,通过volatile保证了可见性和有序性。AtomicInteger使用Unsafe类来进行 CAS 操作,以确保对value字段的原子性更新。
CountDownLatch
CountDownLatch 可以用来进行线程同步协作,一个线程(或多个)等待所有线程完成倒计时。
- 其中构造参数用来初始化等待计数值
- await() 用来等待计数归零
- countDown() 用来让计数减一
应用场景:
- 批量导入:使用了线程池+CountDownLatch批量把数据库中的数据导入到了ES中,避免OOM
- 数据汇总:调用多个接口来汇总数据,如果所有接口(或部分接口)的没有依赖关系,就可以使用线程池+future来提升性能
- 异步线程(线程池):为了避免下一级方法影响上一级方法(性能考虑),可使用异步线程调用下一个方法(不需要下一级方法返回值),可以提升方法响应时间
1 | // 计数器为 3,表示需要等待 3 个任务完成 |
CountDownLatch 的实现原理
CountDownLatch 的内部维护了一个计数器,计数器的递减操作是通过 AbstractQueuedSynchronizer (AQS) 来实现的。
当调用 countDown() 时,内部的 state 值减少,并在 await() 中通过检查 state 是否为 0 来决定是否唤醒等待线程。
注意:CountDownLatch 无法重用,它适合用于一次性的任务完成同步。如果需要重复使用,需要使用 CyclicBarrier 或其他机制。
CyclicBarrier
- 作用: 让一组线程到达一个共同的同步点,然后一起继续执行。常用于分阶段任务执行。
- 用法: 适用于需要所有线程在某个点都完成后再继续的场景。
1 | CyclicBarrier barrier = new CyclicBarrier(3, () -> { |
CyclicBarrier 的原理
CyclicBarrier 是基于 ReentrantLock 和 Condition 实现的。
CyclicBarrier 内部维护了一个计数器,即达到屏障的线程数量,当线程调用 await 的时候计数器会减一,如果计数器减一不等于 0 的时候,线程会调用 condition.await 进行阻塞等待。
如果计数器减一的值等于 0,说明最后一个线程也到达了屏障,于是如果有 barrierAction 就执行 barrierAction ,然后调用 condition.signalAll 唤醒之前等待的线程,并且重置计数器,然后开启下一代,所以它可以循环使用。

Semaphore 的使用场景
Semaphore 可以用来限制线程的执行数量,达到限流的效果。
当一个线程执行时先通过其方法进行获取许可操作,获取到许可的线程继续执行业务逻辑,当线程执行完成后进行释放许可操作,未获取达到许可的线程进行等待或者直接结束。
Semaphore 两个重要的方法:
acquire(): 请求一个信号量,这时候的信号量个数-1(一旦没有可使用的信号量,也即信号量个数变为负数时,再次请求的时候就会阻塞,直到其他线程释放了信号量)
release():释放一个信号量,此时信号量个数+1
1 | Semaphore semaphore = new Semaphore(5); // 允许最多5个线程同时执行任务 |
ThreadLocal
ThreadLocal 是多线程中对于解决线程安全的一个操作类,本质是一个线程内部存储类,让多个线程只操作自己内部的值,从而实现线程数据隔离。
常见应用场景
- 数据库连接管理:每个线程拥有自己的数据库连接,避免了多个线程共享同一个连接导致的线程安全问题。
- 用户上下文管理:在处理用户请求时,每个线程拥有独立的用户上下文(如用户ID、Session信息),在并发环境中确保正确的用户数据。
ThreadLocal 的实现原理
ThreadLocal 通过为每个线程创建一个独立的变量副本来实现线程本地化存储,这个变量副本就是 ThreadLocalMap,而 ThreadLocalMap 是每个线程内部持有的结构。
ThreadLocalMap 的键是 Thread 对象,值是线程独立的变量副本。当线程访问 ThreadLocal.get() 时,它会根据当前线程在自己的 ThreadLocalMap 中找到对应的变量副本。

以下是一个简化的访问流程:
线程A访问
ThreadLocal.get()时,从自己独立的ThreadLocalMap中找到与该ThreadLocal对象对应的值。线程B访问
ThreadLocal.get()时,也从自己独立的ThreadLocalMap中获取的是与其自身相关的值,互不干扰。
ThreadLocal 三个主要方法:
- set(value) 设置值
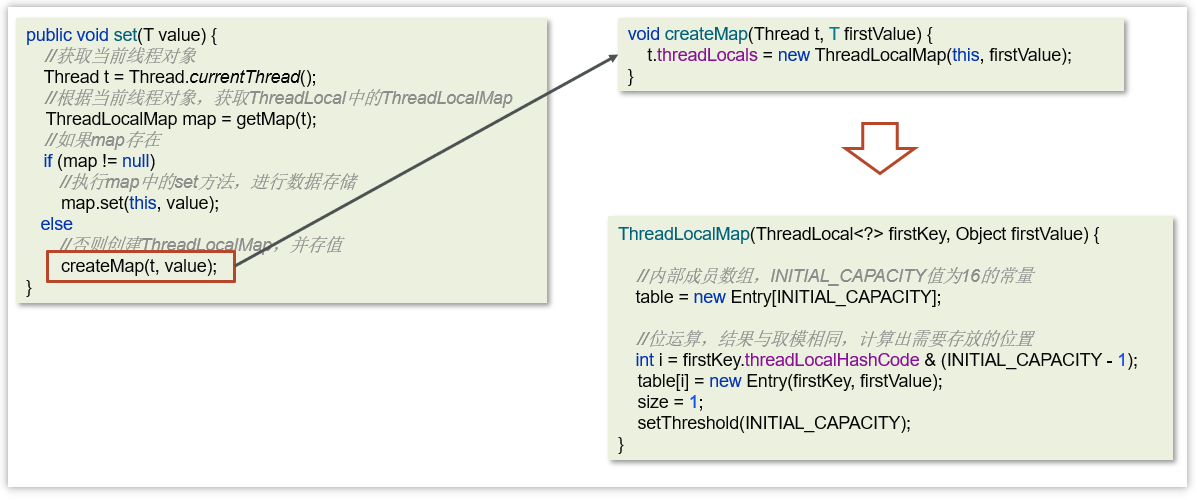
- get() 获取值 / remove() 清除值

ThreadLocal 的内存泄露问题
Java对象中的四种引用类型:强引用、软引用、弱引用、虚引用
强引用:最为普通的引用方式,表示一个对象处于有用且必须的状态,如果一个对象具有强引用,则GC并不会回收它。即便堆中内存不足了,宁可出现OOM,也不会对其进行回收。
弱引用:表示一个对象处于可能有用且非必须的状态。在GC线程扫描内存区域时,一旦发现弱引用,就会回收到弱引用相关联的对象。对于弱引用的回收,无关内存区域是否足够,一旦发现则会被回收。
2
WeakReference weakReference = new WeakReference(user);
每一个Thread维护的ThreadLocalMap中的Entry对象继承了WeakReference,其中key为使用弱引用的ThreadLocal实例,value为线程变量的副本。
ThreadLocalMap 中的 key 是弱引用,值为强引用; key 会被GC 释放内存,关联 value 的内存并不会释放。建议主动 remove 释放 key,value
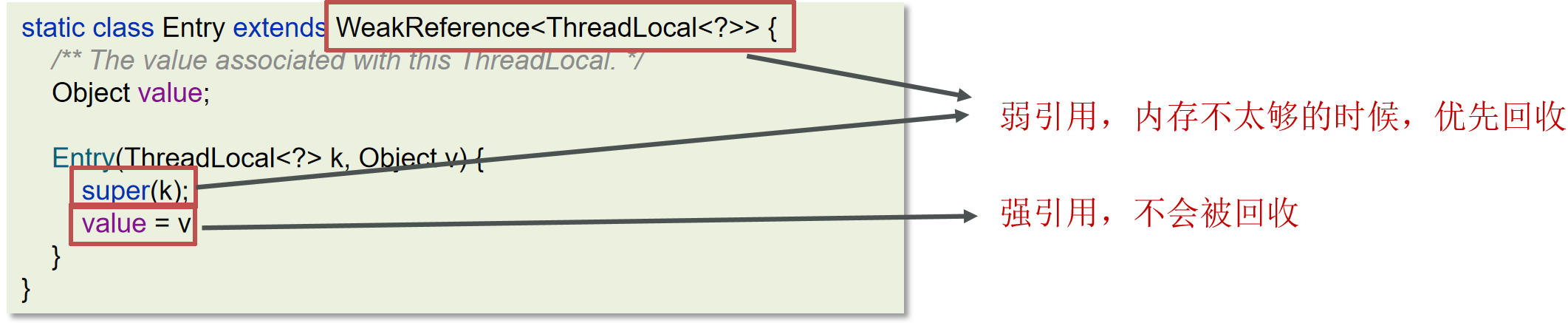
为什么 ThreadLocal 的 key 是弱引用的?
弱引用的原因
- 避免占用过多内存:ThreadLocal 的
ThreadLocalMap会在垃圾回收时自动清理无效的条目,确保不会占用过多内存。 - 防止内存泄漏:如果 ThreadLocal 的 key 是强引用,那么即使 ThreadLocal 变量被回收,
ThreadLocalMap中的条目仍然会保留,导致内存泄漏。使用弱引用可以避免这种情况,因为当 ThreadLocal 变量被回收时,对应的条目也会被垃圾回收器清理。
如何避免 ThradLocal 的内存泄露?
尽管 ThreadLocal 使用弱引用来存储 key,但仍存在内存泄漏的风险。但通过及时移除 ThreadLocal 变量、使用 try-finally 块、自定义 ThreadLocal 类以及在线程池中进行特殊处理,可以有效避免这些问题。这些措施可以确保 ThreadLocal 变量在不再需要时被及时清除,从而避免内存泄漏。
Timer
Timer是一个用于调度任务的工具类。适用于简单的定时任务,如定时更新、定期发送报告等。
Timer 类一般与 TimerTask 搭配使用,TimerTask 是一个需要执行的任务,它是一个实现了 Runnable 接口的抽象类,必须通过继承并实现其 run() 方法。
基本使用:
- 使用
Timer.schedule(TimerTask task, long delay)在指定的延迟之后执行任务。 - 使用
Timer.scheduleAtFixedRate(TimerTask task, long delay, long period)周期性地执行任务。
1 | Timer timer = new Timer(); |
Timer的原理
Timer 可以实现延时任务,也可以实现周期性任务。
实现原理是:用优先队列维持一个小顶堆,即最快需要执行的任务排在优先队列的第一个,根据堆的特性我们知道插入和删除的时间复杂度都是 O(logn)。
然后有个 TimerThread 线程不断地拿排着的第一个任务的执行时间和当前时间做对比。
如果时间到了先看看这个任务是不是周期性执行的任务,如果是则修改当前任务时间为下次执行的时间,如果不是周期性任务则将任务从优先队列中移除。最后执行任务。如果时间还未到则调用 wait() 等待。
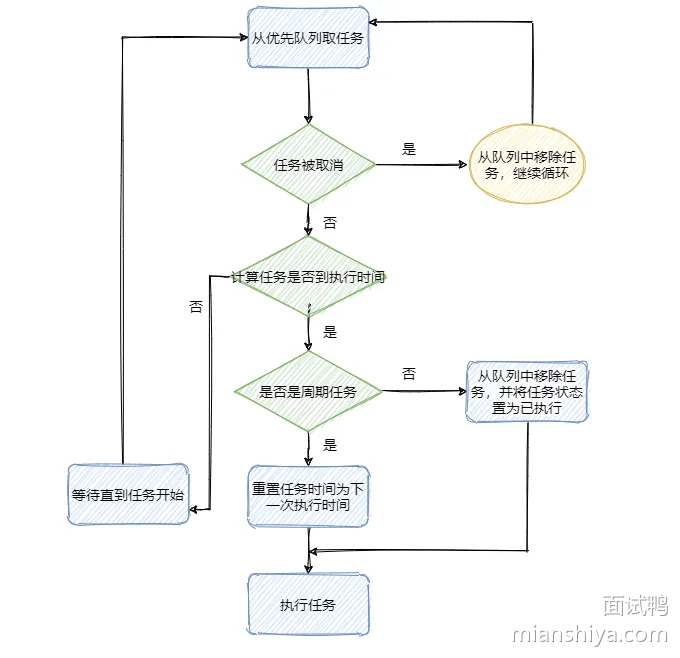
Timer 的弊端和替代方案
优先队列的插入和删除的时间复杂度是O(logn),当数据量大的时候,频繁的入堆出堆性能有待考虑。
并且是单线程执行,那么如果一个任务执行的时间过久则会影响下一个任务的执行时间(当然你任务的run要是异步执行也行)。
并且从它对异常没有做什么处理,所以一个任务出错的时候会导致之后的任务都无法执行。
推荐使用 ScheduledExecutorService 替代 Timer。
ScheduledExecutorService
ScheduledExecutorService 是 Java 5 引入的 Timer 的替代方案,功能更强大。支持多线程并行调度任务,能更好地处理任务调度的复杂场景。
因为使用线程池进行任务调度,所以不会因某个任务的异常终止而导致其他任务停止。并且它提供了更灵活的 API,可以更精细地控制任务的执行周期和策略。
1 | public static void main(String[] args) { |
例:超时关闭不付款的订单
比如说这样一个场景,一个用户下单商品后一直不付款,那么30分钟就需要关闭这个订单,怎么做?
1 | private static final ScheduledExecutorService executor = Executors.newScheduledThreadPool(1); |
BlockingQueue
- 作用: 是一个线程安全的队列,支持阻塞操作,适用于生产者-消费者模式。
- 用法: 生产者线程将元素放入队列,消费者线程从队列中取元素,队列为空时消费者线程阻塞。
1 | BlockingQueue<String> queue = new LinkedBlockingQueue<>(); |
BlockingQueue 的阻塞特性原理
核心机制:
1. 锁(Lock):BlockingQueue 的实现中会使用锁来确保线程安全。当多个线程试图访问队列时,锁可以确保同一时刻只有一个线程能够执行某些操作(如 put 或 take)。
2. 条件变量(Condition):条件变量允许一个或多个线程在一个特定条件得到满足之前等待。在 BlockingQueue 的实现中,条件变量用于等待队列变得非空(对于 take 操作)或非满(对于 put 操作)。
如何实现阻塞:
1. put 操作:当向 BlockingQueue 中添加元素时,如果队列已满,则 put 方法会阻塞当前线程,并调用 Condition 的 await 方法,使得当前线程等待,直到队列空出位置后再添加元素。
2. take 操作:当从 BlockingQueue 中取出元素时,如果队列为空,则 take 方法将阻塞当前线程,调用条件变量的 await 方法,使得当前线程等待,直到队列中有元素为止。
具体代码操作:
1 | public class ArrayBlockingQueue<E> extends AbstractQueue<E> |
线程
如何创建线程?
一般来说,创建线程有很多种方式,例如继承Thread类、实现Runnable接口、实现Callable接口、利用Callable接口和Future接口方式、使用线程池、使用CompletableFuture类等等。
不过,这些方式其实并没有真正创建出线程。准确点来说,这些都属于是在 Java 代码中使用多线程的方法。
严格来说,Java 就只有一种方式可以创建线程,那就是通过new Thread().start()创建。不管是哪种方式,最终还是依赖于new Thread().start()。
| 创建方式 | 优点 | 缺点 |
|---|---|---|
| 继承Thread类 | 编程比较简单,可以直接使用Thread类中的方法 | 不能再继承其他的类扩展性较差 |
| 实现Runnable接口 | 扩展性强,实现该接口的同时还可以继承其他的类 | 编程相对复杂,不能直接使用Thread类中的方法 |
| 实现Callable接口 | 可以获取多线程运行过程中的结果;扩展性强,实现该接口的同时还可以继承其他的类 | 编程相对复杂,不能直接使用Thread类中的方法 |
| 线程池创建 | 易于管理 | 编程复杂,占用更多资源 |
主线程如何知晓创建的子线程是否执行成功?
1)**使用 Thread.join()**:
- 主线程通过调用
join()方法等待子线程执行完毕。子线程正常结束,说明执行成功,若抛出异常则需要捕获处理。
2)**使用 Callable 和 Future**:
- 通过
Callable创建可返回结果的任务,并通过Future.get()获取子线程的执行结果或捕获异常。Future.get()会阻塞直到任务完成,若任务正常完成,返回结果,否则抛出异常。
3)使用回调机制:
- 可以通过自定义回调机制,主线程传入一个回调函数,子线程完成后调用该函数并传递执行结果。这样可以非阻塞地通知主线程任务完成情况。
4)使用 CountDownLatch或其他 JUC 相关类:
- 主线程通过
CountDownLatch来等待子线程完成。当子线程执行完毕后调用countDown(),主线程通过await()等待子线程完成任务。
线程的生命周期和状态

Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态:
| 线程状态 | 具体含义 |
|---|---|
| NEW | 初始状态,线程被创建出来,但没有被调用 start() |
| RUNNABLE | 运行状态,线程被调用了 start()等待运行的状态 |
| BLOCKED | 阻塞状态,需要等待锁释放 |
| WAITING | 等待状态,表示该线程需要等待其他线程做出一些特定动作(通知或中断) |
| TIMED_WAITING | 超时等待状态,造成限时等待状态的原因有三种:Thread.sleep(long)、Object.wait(long)、join(long) |
| TERMINATED | 终止状态,表示该线程已经运行完毕= |
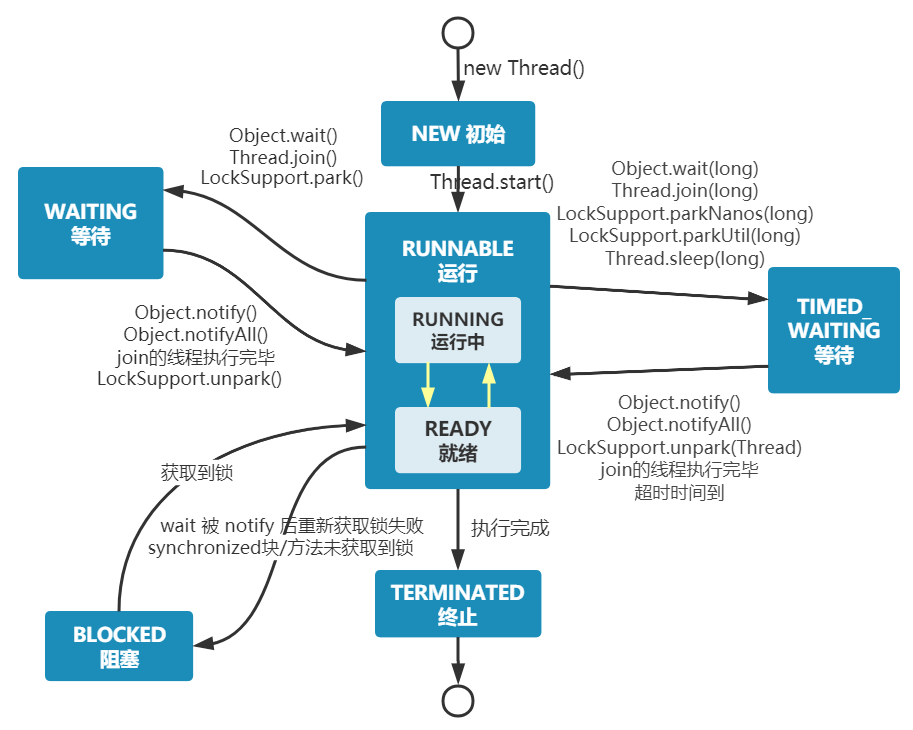
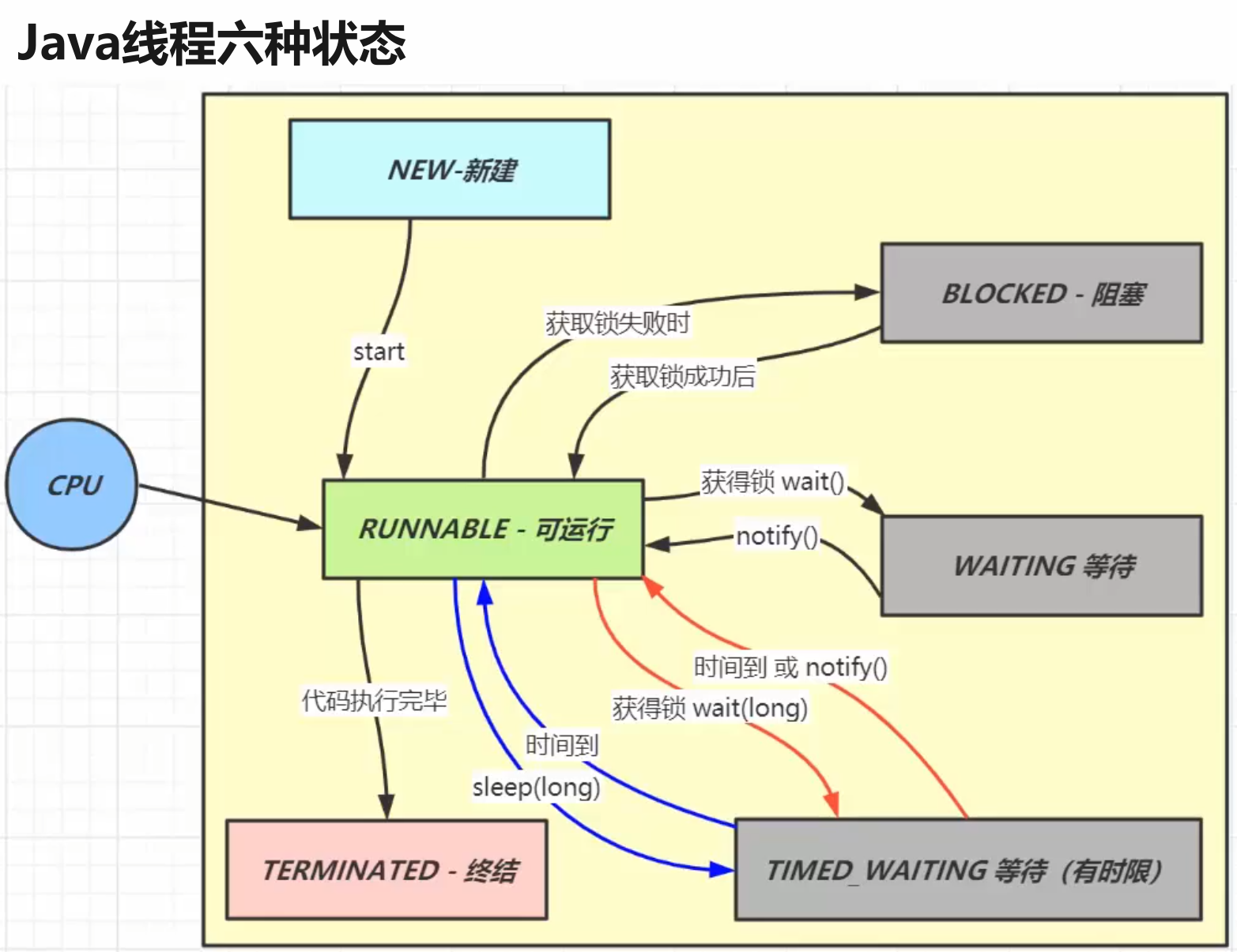
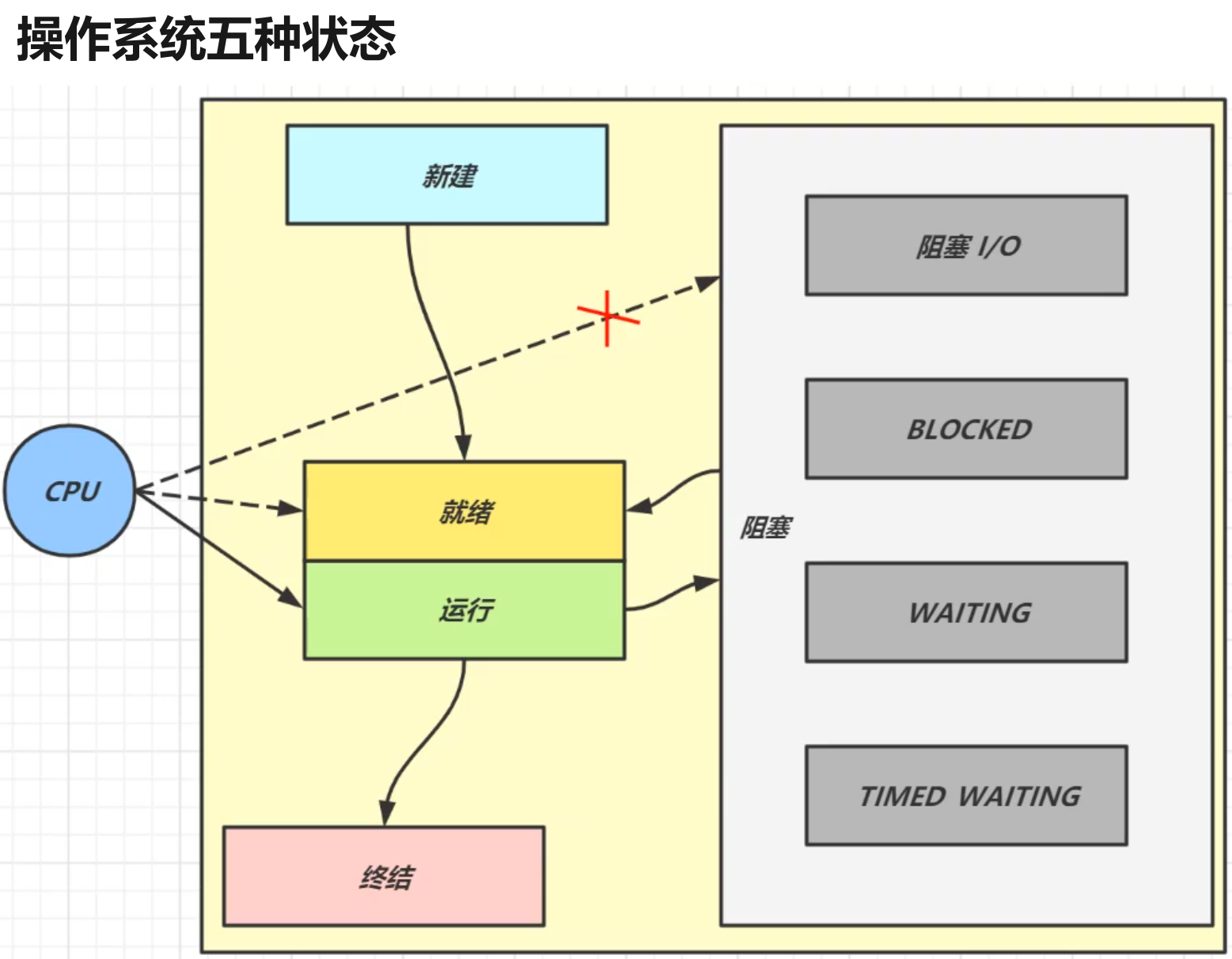
runnable 和 callable 有什么区别?
- Runnable 接口run方法没有返回值
- Callable接口call方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
- Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛
run() 和 start() 有什么区别?
start(): 用来启动线程,通过该线程调用run方法执行run方法中所定义的逻辑代码。只能被调用一次。run(): 封装了要被线程执行的代码,可以被调用多次。
notify() 和 notifyAll() 有什么区别?
notifyAll():唤醒所有阻塞状态的线程notify():顺序唤醒一个阻塞状态的线程
wait() 、 sleep() 和 yield() 有什么区别?
共同点:都是让当前线程暂时放弃 CPU 的使用权,进入阻塞状态
不同点:
- 方法归属不同
sleep(long)是 Thread 的静态方法wait()和wait(long)都是 Object 的成员方法
- 醒来时机不同
- 执行
sleep(long)和wait(long)的线程都会在等待相应毫秒后醒 wait(long)和wait()还可以被 notify 唤醒- 它们都可以被打断唤醒
- 执行
- 锁特性不同(重点)
wait()和wait(long)方法的调用必须先获取wait对象的锁,而sleep()则无此限制wait()和wait(long)方法执行后会释放对象锁,允许其它线程获得该对象锁sleep()如果在同步代码块中执行,并不会释放对象锁
总结:
- **
Thread.yield()**:用于提示当前线程愿意放弃当前的CPU时间片,但不释放锁,也不阻塞当前线程。- **
Thread.sleep()**:使当前线程进入暂停状态,但不释放锁、会阻塞当前线程。- **
Object.wait()**:使当前线程进入等待状态,会释放锁,但会阻塞当前线程,直到被其他线程唤醒。
Thread.sleep(0) 的作用是什么?
看起来 Thread.sleep(0) 很奇怪,让线程睡眠 0 毫秒?那不是等于没睡眠吗?
是的,确实没有睡眠,但是调用了 Thread.sleep(0) 当前的线程会暂时出让 CPU ,这使得 CPU 的资源短暂的空闲出来别的线程有机会得到 CPU 资源。
所以,在一些大循环场景,如果害怕这段逻辑一直占用 CPU 资源,则可以调用 Thread.sleep(0) 让别的线程有机会使用 CPU。
实际上 Thread.yield() 这个命令也可以让当前线程主动放弃 CPU 使用权,使得其他线程有机会使用 CPU。
如何中断/停止正在运行的线程?
调用
interrupt()方法:
使用Thread.interrupt()方法中断线程。线程需要在适当的地方检查中断状态(如通过Thread.currentThread().isInterrupted()或捕获InterruptedException)并做出响应。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
// 可能需要在适当的地方检查中断,尤其是阻塞操作前
// 执行任务...
}
} catch (InterruptedException e) {
// 线程在等待/睡眠/ join等操作时可能被中断
// 清理工作
} finally {
// 清理工作
}
}
// 在其他地方调用以请求中断
myThread.interrupt();使用volatile布尔标记:
创建一个volatile类型的布尔标记,作为线程是否应该继续运行的指示器。线程在运行过程中定期检查这个标记,如果标记变为false,则线程自行结束。1
2
3
4
5
6
7
8
9
10
11
12private volatile boolean running = true;
public void run() {
while (running) {
// 执行任务...
}
// 清理工作
}
public void stopThread() {
running = false;
}利用
Future和ExecutorService:
如果使用ExecutorService来管理线程,可以通过取消相关的Future任务来间接停止线程。1
2
3
4
5
6
7
8ExecutorService executor = Executors.newSingleThreadExecutor();
Future<?> future = executor.submit(() -> {
// 执行任务...
});
// 请求取消任务
future.cancel(true); // true表示应该中断正在执行的任务
executor.shutdownNow(); // 尝试停止所有活动的执行任务
避免使用已废弃的Thread.stop()、Thread.suspend()和Thread.resume()方法,因为这些方法可能会导致数据不一致性、死锁或其他不可预料的问题。正确的线程结束策略应当确保线程能够清理资源、释放锁并以一种安全的方式终止。
线程间的通信方式
在 Java 中,线程之间的通信是指多个线程协同工作,主要实现方式包括:
1)共享变量:
- 线程可以通过访问共享内存变量来交换信息(需要注意同步问题,防止数据竞争和不一致)。
- 共享的也可以是文件,例如写入同一个文件来进行通信。
2)同步机制:
- **
synchronized**:Java 中的同步关键字,用于确保同一时刻只有一个线程可以访问共享资源,利用 Object 类提供的wait()、notify()、notifyAll()实现线程之间的等待/通知机制 - **
ReentrantLock**:配合 Condition 提供了类似于 wait()、notify() 的等待/通知机制 - **
BlockingQueue**:通过阻塞队列实现生产者-消费者模式 - **
CountDownLatch**:可以允许一个或多个线程等待,直到在其他线程中执行的一组操作完成 - **
CyclicBarrier**:可以让一组线程互相等待,直到到达某个公共屏障点 - **
Semaphore**:信号量,可以控制对特定资源的访问线程数 - **
volatile**:Java 中的关键字,确保变量的可见性,防止指令重排 - **
AtomicInteger**,可以用于实现线程安全的计数器或其他共享变量。
补充 Object 中的方法说明:
- **Object 和 synchronized **——wait()、notify()、notifyAll():使线程进入等待状态,释放锁。唤醒单个等待线程。唤醒所有等待线程。
- Lock 和 Condition——await()、signal():使持有ReentranLock锁的线程等待。唤醒持有ReentranLock锁的线程。
- BlockingQueue——put()、take():将元素放入阻塞队列。从队列中获取取元素
如果一个线程在被调用两次 start() 方法会发生什么?
会报错!因为在 Java 中,一个线程只能被启动一次!所以尝试第二次调用 start() 方法时,会抛出 IllegalThreadStateException 异常。
这是因为一旦线程已经开始执行,它的状态不能再回到初始状态。线程的生命周期不允许它从终止状态回到可运行状态。
死锁产生的条件是什么?如何避免死锁?如何诊断死锁?
死锁:一个线程需要同时获取多把锁,这时就容易发生死锁
死锁产生的条件:
- 互斥条件:每个资源只能被一个线程占用。
- 占有和等待:线程在持有至少一个资源的同时,等待获取其他资源。
- 不可抢占:线程所获得的资源在未使用完毕之前不能被其他线程抢占。
- 循环等待:多个线程形成一种头尾相接的循环等待资源关系。
避免死锁的方法:
- 按序申请资源:确保所有线程在获取多个锁时,按照相同的顺序获取锁。
- 尽量减少锁的范围:将锁的粒度尽可能缩小,减少持有锁的时间。可以通过拆分锁或使用更细粒度的锁来实现。
- 使用尝试锁机制:使用
ReentrantLock的tryLock方法,尝试在一段时间内获取锁,如果无法获取,则可以选择放弃或采取其他措施,避免死锁。 - 设置超时等待时间:为锁操作设置超时,防止线程无限期地等待锁。
- 避免嵌套锁:尽量避免在一个锁的代码块中再次尝试获取另一个锁。
死锁诊断:
使用jdk自带的工具:jps和 jstack
- 使用
jps查看运行的线程 - 第二:使用
jstack -l <进程ID>查看线程运行的情况
其他解决工具,可视化工具
- jconsole
用于对jvm的内存,线程,类的监控,是一个基于 jmx 的 GUI 性能监控工具
打开方式:java 安装目录 bin目录下 直接启动 jconsole.exe 就行
- VisualVM:故障处理工具
能够监控线程,内存情况,查看方法的CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈
打开方式:java 安装目录 bin目录下 直接启动 jvisualvm.exe就行
如何创建多线程?
常见有以下五种方式创建使用多线程:
1)实现 Runnable 接口:
- 实现
Runnable接口的run()方法,使用Thread类的构造函数传入Runnable对象,调用start()方法启动线程。 - 例子:
Thread thread = new Thread(new MyRunnable()); thread.start();
2)继承 Thread 类:
- 继承
Thread类并重写run()方法,直接创建Thread子类对象并调用start()方法启动线程。 - 例子:
MyThread thread = new MyThread(); thread.start();
3)**使用 Callable 和 FutureTask**:
- 实现
Callable接口的call()方法,使用FutureTask包装Callable对象,再通过Thread启动。 - 例子:
FutureTask<Integer> task = new FutureTask<>(new MyCallable()); Thread thread = new Thread(task); thread.start();
4)使用线程池(ExecutorService):
- 通过
ExecutorService提交Runnable或Callable任务,不直接创建和管理线程,适合管理大量并发任务。 - 例子:
ExecutorService executor = Executors.newFixedThreadPool(10); executor.submit(new MyRunnable());
5)CompletableFuture(本质也是线程池,默认 forkjoinpool):
- Java 8 引入的功能,非常方便地进行异步任务调用,且通过
thenApply、thenAccept等方法可以轻松处理异步任务之间的依赖关系。 CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {});
CompletableFuture 的使用
Future 和 CompletableFuture 对比
- Future:表示异步计算的结果,可以查询结果是否可用,等待结果完成或取消计算。
- CompletableFuture:表示异步计算的一个阶段,可以与其他阶段组合形成复杂的异步流程。
创建任务
- runAsync:异步执行一个不返回结果的任务。
- supplyAsync:异步执行一个返回结果的任务。
1 | // 创建一个不返回结果的异步任务 |
任务回调
- thenApply:在前一个任务完成后,**返回一个新的
CompletableFuture**。 - thenAccept:在前一个任务完成后,消费结果,不返回新结果。
- thenRun:在前一个任务完成后,执行一个不返回结果的操作。
1 | CompletableFuture<String> future3 = future2.thenApply(result -> { |
组合任务
- thenCombine:合并两个 CompletableFuture 的结果。
- thenCompose:将一个 CompletableFuture 的结果作为另一个 CompletableFuture 的输入。
1 | CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> "Hello"); |
并行处理任务
- allOf:等待所有
CompletableFuture完成。 - anyOf:等待任何一个
CompletableFuture完成。
1 | CompletableFuture<String> future4 = CompletableFuture.supplyAsync(() -> { |
处理异常
- exceptionally:在任务异常时执行一个回调函数。
- handle:无论任务是否异常,都会执行一个回调函数。
1 | CompletableFuture<Object> future6 = CompletableFuture.supplyAsync(() -> { |
线程池
ForkJoinPool
ForkJoinPool 是Java 7引入的一个专门用于并行执行任务的线程池,它采用“分而治之”(divide and conquer)算法来解决大规模的并行问题。
核心机制:
- Fork(分解):任务被递归分解为更小的子任务,直到达到不可再分的程度。
- Join(合并):子任务执行完毕后,将结果合并,形成最终的解决方案。
工作窃取算法:ForkJoinPool使用了一种称为工作窃取的调度算法。空闲的工作线程会从其他繁忙线程的工作队列中“窃取”未完成的任务以保持资源高效利用。
关键类:
ForkJoinPool:表示Fork/Join框架中的线程池。ForkJoinTask:任务的基础抽象类,子类如RecursiveTask和RecursiveAction分别用于有返回值和无返回值的任务。
ForkJoinPool 与普通线程池的区别
有两方面的区别:
- 任务分解与合并:传统的线程池一般处理相对独立的任务,而ForkJoinPool则擅长处理可以分解的任务,最终将结果合并。
- 线程调度策略:普通的线程池通常由中央队列管理任务,而ForkJoinPool中的每个工作线程都维护着自己的双端队列,并通过工作窃取来平衡任务。
ForkJoinPool 与并行流的关系
ForkJoinPool 是并行流的爹!
Java 8中的并行流(Parallel Streams)底层是基于ForkJoinPool实现的。
Java 8中通过parallelStream()方法,可以轻松地利用ForkJoinPool来实现并行操作,从而提高处理效率。
线程池的原理、任务提交流程
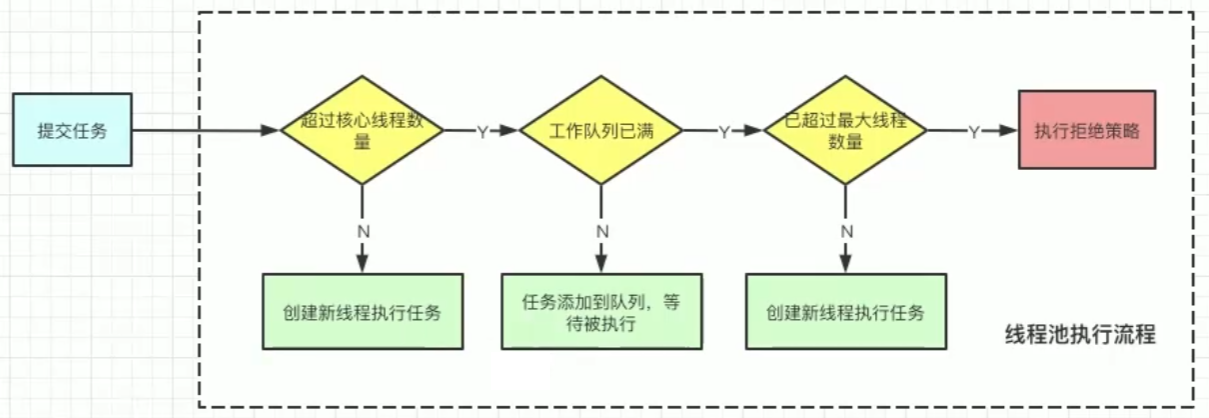
- 默认情况下线程不会预创建,任务提交之后才会创建线程。(不过设置 prestartAllCoreThreads 可以预创建核心线程)
- 如果工作线程少于
corePoolSize,则创建新线程来处理请求 - 如果工作线程等于或多于
corePoolSize,则将任务加入队列 - 如果无法将请求加入队列,则创建新的线程来处理请求
- 如果创建新线程使当前运行的线程超出
maximumPoolSize,则任务将被拒绝
线程池的 7 个核心参数
用 ThreadPoolExecutor 类创建线程:
1 | public class MyThreadPoolDemo3 { |

任务拒绝策略
| 任务拒绝策略 | 说明 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 丢弃任务并抛出RejectedExecutionException异常(默认) |
| ThreadPoolExecutor.DiscardPolicy | 丢弃任务,但是不抛出异常(不推荐) |
| ThreadPoolExecutor.DiscardoldestPolicy | 丢弃队列最前面的任务,然后重新尝试执行任务 |
| ThreadPoolExecutor.CallerRunsPolicy | 由调用线程处理该任务 |
自定义任务拒绝策略
可以实现 RejectedExecutionHandler 接口来定义自定义的拒绝策略。例如,记录日志或将任务重新排队。
1 | public class CustomRejectedExecutionHandler implements RejectedExecutionHandler { |
线程池可选用的阻塞队列
workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
比较常见workQueue 的有4个,用的最多是ArrayBlockingQueue和LinkedBlockingQueue
1.ArrayBlockingQueue:数组结构的有界阻塞队列。
2.LinkedBlockingQueue:链表结构的阻塞队列,大小无限。
3.DelayedWorkQueue :带优先级的无界阻塞队列。可以将执行时间最靠前的任务出队。
4.SynchronousQueue:不存储任务,直接将任务提交给线程。
ArrayBlockingQueue 和 LinkedBlockingQueue区别
| ArrayBlockingQueue | LinkedBlockingQueue | |
|---|---|---|
| 长度 | 有界 | 默认无界,支持有界 |
| 底层数据结构 | 数组 | 链表 |
| 创建方式 | 提前初始化 Node 数组,Node 需要是提前创建好的 | 懒性队列,添加数据的时候创建节点,入队会生成新 Node |
| 加锁方式 | 只有一把锁,读和写公用,性能较差 | 头尾两把锁,一把读、一把写,性能较好 |
线程池的 5 种状态
线程池的生命周期通常包括以下几个状态:
RUNNING:接受新的任务并且处理队列中的任务。SHUTDOWN:不再接受新任务,但是会继续处理队列中的任务。(调用shutdown()方法)STOP:不再接受新任务并且不处理队列中的任务,中断正在执行的任务。(调用shutdownNow()方法)TIDYING:所有的任务都已完成,正在执行终止前的清理工作。TERMINATED:线程池已完成清理工作,处于结束状态。
1. 线程池状态说明:
RUNNING:默认状态,可以正常接收任务并执行,处理工作队列的任务。SHUTDOWN:不再接受新任务,但会继续处理等待队列中的任务。STOP:既不接受新任务也不处理等待队列中的任务,中断正在执行的任务。TIDYING:所有任务结束,工作线程数为0,是一种过渡状态。TERMINATED:线程池终止状态,表示terminated()钩子函数调用完毕。
2. 状态之间的转换:
RUNNING -> SHUTDOWN:调用shutdown()方法导致线程池变为SHUTDOWN状态。(RUNNING 或 SHUTDOWN) -> STOP:调用shutdownNow()方法导致线程池变为STOP状态。SHUTDOWN -> TIDYING:当等待队列为空且工作线程数为0时,线程池从SHUTDOWN转为TIDYING状态。STOP -> TIDYING:同上,等待队列为空时,线程池从STOP转为TIDYING状态。TIDYING -> TERMINATED:调用terminated()钩子函数后,线程池从TIDYING转为TERMINATED状态。
Java中的 4 种默认线程池
使用ExecutorService可以创建许多类型的线程池:
FixedThreadPool:固定线程数量的线程池,可控制线程最大并发数,超出的线程会在队列中等待,允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
SingleThreadExecutor:单线程化的线程池,保证所有任务按照指定顺序执行,允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
CachedThreadPool:可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程,允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM
**
ScheduledThreadPool**:可以执行延迟任务的线程池,支持定时及周期性任务执行
**
WorkStealingPool**:基于任务窃取算法的线程池。线程池中的每个线程维护一个双端队列(deque),线程可以从自己的队列中取任务执行。如果线程的任务队列为空,它可以从其他线程的队列中”窃取”任务来执行,达到负载均衡的效果。适合大量小任务并行执行,特别是递归算法或大任务分解成小任务的场景。
如何确定线程池的线程数?
一般而言:
核心线程数 = CPU核心数
最大线程数 = CPU核心数 * 2
① CPU密集型任务:
- 高并发、任务执行时间短 –>( CPU核数 + 1 ),减少线程上下文的切换
② 资源密集型任务:
IO密集型的任务 –> (CPU核数 * 2)
计算密集型任务 –> ( CPU核数 + 1 )
③ 并发高、业务执行时间长:
- 关键不在于线程池而在于整体架构的设计,而是要通过缓存、服务器进行优化,通过压测来确定最优的线程池参数。
线程池调整原则
- 动态调整线程池大小时,需要确保新的配置不会导致系统资源耗尽。比如,过大的线程池可能会占用过多的 CPU 和内存,反而影响性能。
- 当系统负载发生变化时,可以使用动态调整来优化线程池的资源使用率,例如在系统负载增加时,临时提高核心线程数以应对突发流量,当系统负载下降时,可以减少核心线程数以节省资源。
- 当任务队列长度过长时,可以临时增加核心线程数,以加快任务的处理速度。
线程池监控与调整
- 在实际生产环境中,可以通过监控线程池的状态(如当前活跃线程数、队列长度等)来决定是否动态调整线程池大小。
- 可以使用 JMX(Java Management Extensions)来监控
ThreadPoolExecutor,结合指标来自动调整线程池大小以优化性能。
底层原理:线程池的execute()运行原理
1 | public void execute(Runnable command) { |
底层原理:线程池的动态调整是如何保证线程安全的?
**1. 使用 volatile 修饰 核心线程数 和 最大线程数 **
核心线程数corePoolSize 和最大线程数 maximumPoolSize 都是用 volatile 修饰的,保证了当这些字段被修改时,其他线程能够看到最新的值,而且不会发生指令重排序,确保了多线程环境下的可见性和有序性。
1 | protected volatile int corePoolSize; |
2. 使用原子类记录关键信息
使用了 ctl 字段来保存线程池的一些关键状态信息,包括当前活跃线程数、线程池的状态等。这个字段是一个 long 类型,通过位操作来保存不同的状态信息。在修改线程池状态时,ThreadPoolExecutor 使用了 CAS(Compare and Swap)操作来保证原子性。
1 | private volatile long ctl; |
例如,在创建新线程时,addWorker 方法会使用 compareAndSetWorkerCount 来更新线程池的当前线程数,这个操作是原子的。
1 | protected boolean compareAndSetWorkerCount(int expect, int update) { |
线程池状态ctl
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
workerCountOf 方法
workerCountOf 方法是从 ctl 字段中提取当前活动线程的数量。ctl 字段是一个 volatile long 类型的变量,包含了线程池的一些状态信息,包括当前活动线程的数量。
ctl 的高几位表示线程池的状态信息,而低几位表示当前活动线程的数量。具体来说,ctl 的低 3 位(0-2)表示当前活动线程的数量。
interruptIdleWorkers 方法
interruptIdleWorkers 方法用来中断那些处于空闲状态的线程。该方法遍历所有工作线程,并中断那些处于空闲状态的线程。如果当前活动线程数仍然大于新的最大线程数,则会再次检查并中断空闲线程。
3. 使用锁
使用锁来保护共享资源的访问。
例如,在 interruptIdleWorkers 方法中,当需要中断空闲线程时,会获取 mainLock 来保护对 workers 集合的操作。
1 | private void interruptIdleWorkers(boolean onlyOne) { |
4. 使用并发集合
使用了 ConcurrentHashMap 来管理 Worker 对象,这些对象代表了正在工作的线程。
1 | private final ConcurrentHashMap<Integer, Worker> workers = new ConcurrentHashMap<>(); |
底层原理:核心线程数的动态修改原理
1 | public void setCorePoolSize(int corePoolSize) { |
底层原理:最大线程数的动态修改原理
1 | public void setMaximumPoolSize(int maximumPoolSize) { |
如何避免线程池的线程被无限占用?
结合 awaitTermination:
无论是 shutdown() 还是 shutdownNow(),可以配合 awaitTermination() 方法等待线程池完全终止。awaitTermination() 会阻塞调用线程,直到线程池终止或超时。
比如以下的使用方式:
1 | threadPool.shutdown(); |
这种组合方式常用于确保线程池能够在合理时间内关闭,避免无限等待或资源泄漏。
多次调用 shutdown()、shutdownNow() 会怎样?
再次调用不会有额外效果,只会在第一次调用时有效果。
而且,即使线程池进入 SHUTDOWN 状态,相关资源不会立即释放。必须等待所有线程完成任务,线程池进入 TERMINATED 状态后,资源才会释放。
Java 线程池内部任务出异常后,如何知道是哪个线程出了异常?
在Java中,线程池内部的任务如果抛出未捕获的异常,默认情况下这些异常会被记录到日志中,并且任务会被中断,但不会影响线程池本身继续执行其他任务。
如果你只需要处理个别任务的异常,那么包装任务或者使用Future.get()可能是更好的选择。
1. 使用Future和get()方法
任务到线程池后获取一个Future对象,调用Future.get()方法等待任务完成,并且如果任务执行过程中抛出异常,这个异常会被封装成ExecutionException重新抛出。
1 | ExecutorService executor = Executors.newFixedThreadPool(10); |
如果你想对所有任务的异常进行统一处理,可以考虑使用自定义ThreadFactory或重写afterExecute方法。
2. 自定义ThreadFactory
可以通过自定义ThreadFactory来创建线程,并设置异常处理器。
1 | ExecutorService executor = Executors.newFixedThreadPool(10, new ThreadFactory() { |
3. 使用ThreadPoolExecutor的afterExecute方法
可以重写ThreadPoolExecutor.afterExecute()方法来捕获任务执行后的异常。
1 | ThreadPoolExecutor executor = new ThreadPoolExecutor( |
—————————————
Java虚拟机
工具
查看字节码的软件
jclasslib插件
javap
- ```shell
jar –xvf xxxx.jar1
2
3
- ```shell
javap -v xxxx.class > xxxx.txt
- ```shell
Arthas
- ```shell
java -jar arthas-boot.jar1
2
3
- ```shell
jad --source-only com.demo.package.Main.clss
- ```shell
常用的Java内存调试工具
1 | jmap、jstack、jconsole、jhat |
基本概念
Java程序执行过程
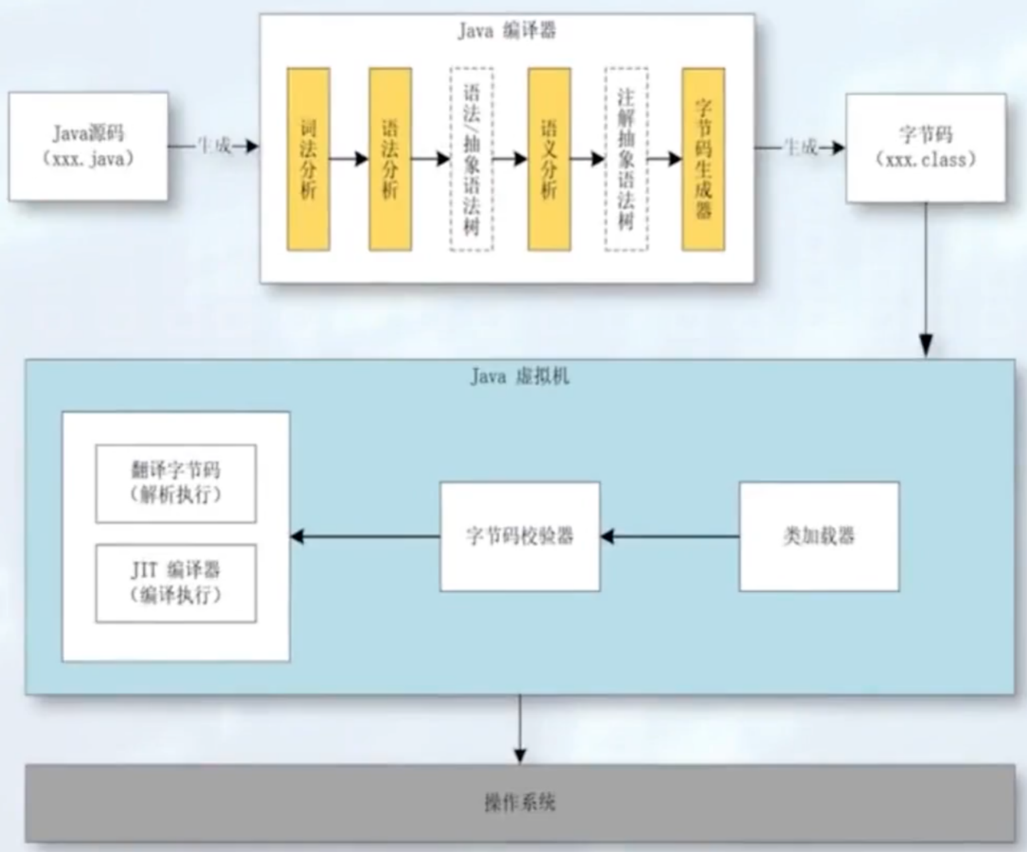
JVM的运行流程
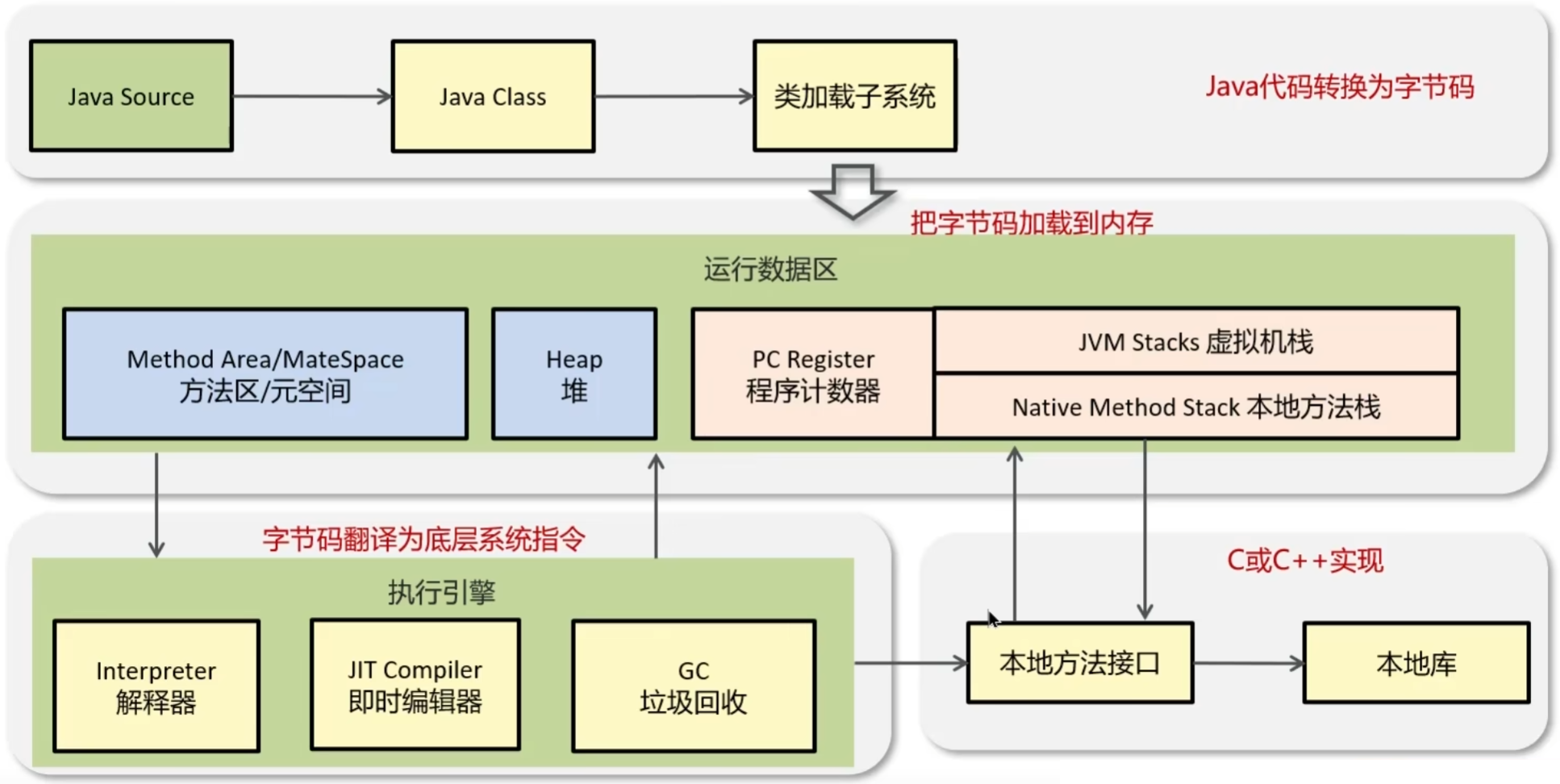
JVM的组成
- 类加载子系统(Class Loader):核心组件类加载器,负责将字节码文件中的内容加载到内存中。
- 运行时数据区(Runtime Data Area):JVM管理的内存,创建出来的对象、类的信息等等内容都会放在这块区域中。
- 执行引擎(Execution Engine):包含了即时编译器、解释器、垃圾回收器,执行引擎使用解释器将字节码指令解释成机器码,使用即时编译器优化性能,使用垃圾回收器回收不再使用的对象。
- 本地接口(Native Interface):调用本地使用C/C++编译好的方法,本地方法在Java中声明时,都会带上native关键字。
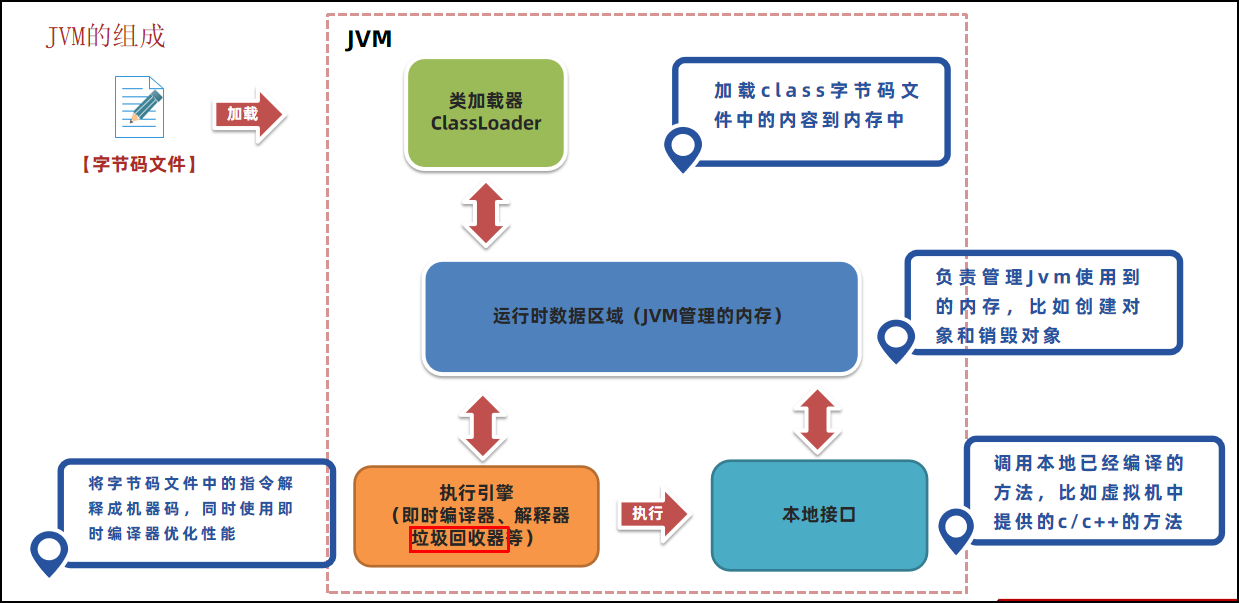
JVM的内存结构
JVM 分为堆区和栈区,还有方法区,初始化的对象放在堆里面,引用放在栈里面, class 类信息常量池(static 常量和 static 变量)等放在方法区
堆(Heap):虚拟机中最大的一块内存区域,几乎所有的对象实例都在这里分配内存,初始化的对象、成员变量 (非 static 变量),所有的对象实例和数组都要在堆上分配。
- 年轻代(Young Generation)
- Eden区
- Survivor区(From和To)
- 老年代(Old Generation)
- 字符串常量池
- 年轻代(Young Generation)
方法区(Method Area) / 元空间(Meta Space):主要是存储类信息,常量池(static 常量和 static 变量),编译后的代码(字节码)等数据。方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法如构造器,接口代码也在此定义。简单说,所有定义的方法的信息都保存在该区域,此区属于共享区间。静态变量+常量+类信息+运行时常量池存在方法区中,实例变量存在堆内存中
- 运行时常量池(Runtime Constant Pool): 方法区内的一部分,存放了编译期生成的各种字面量和符号引用。
程序计数器(Program Counter Register):每个线程都有一个程序计数器。是一块较小的内存空间,记录当前线程执行的行号,本质是一个指针,指向方法区中的方法字节码(下一个将要执行的指令代码),由执行引擎读取下一条指令。
虚拟机栈(VM Stack):由栈帧组成,调用一个方法就会压入一帧,栈帧上面存储局部变量表,操作数栈,方法出口等方法从调用直至执行完成的过程中的所有数据,局部变量表存放的是 8 大基础类型加上一个应用类型,所以还是一个指向地址的指针。栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命周期是跟随线程的生命周期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。
本地方法栈(Native Method Stack):与虚拟机栈功能类似,为 Native 方法服务。它的具体做法是 Native Method Stack中登记native方法,在Execution Engine 执行时加载native libraries。
JVM的版本变化(JDK 7~8)
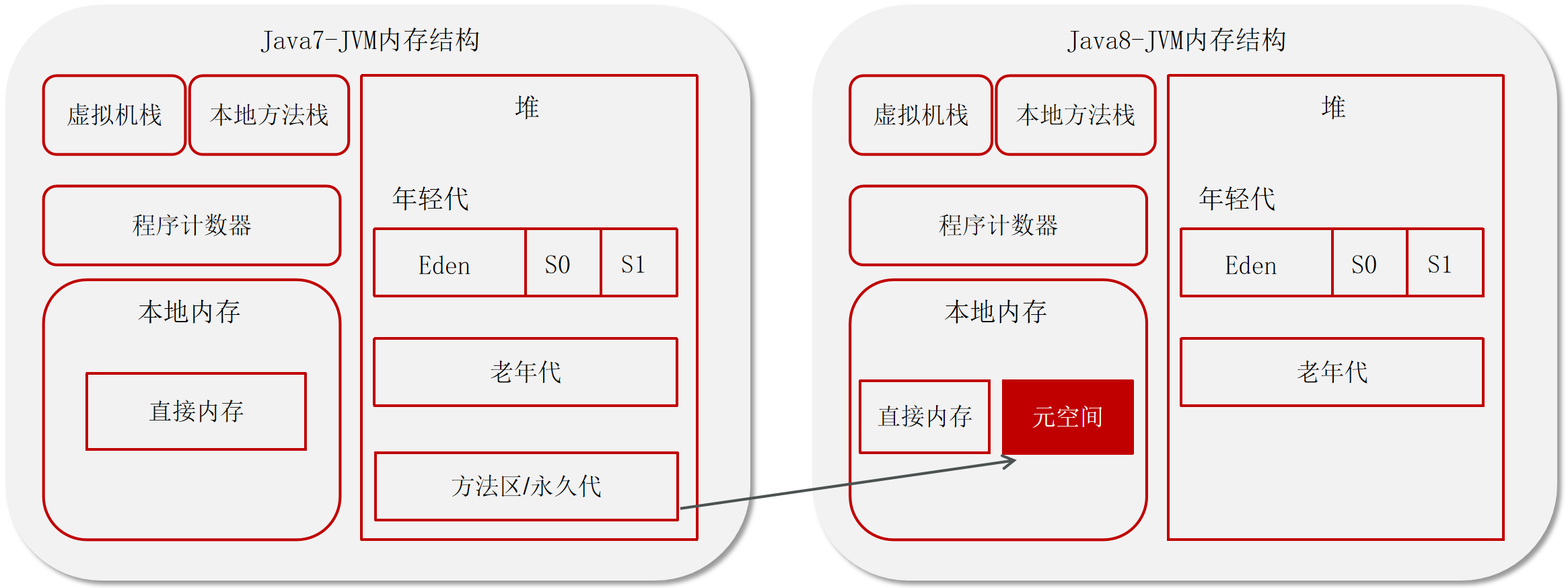
1.7中的永久代(存储的是类信息、静态变量、常量、编译后的代码)在堆中
1.8移除了永久代,把数据存储到了本地内存的元空间中,防止内存溢出
在JDK7中,堆内存通常被分为Nursery内存(young generation)、长时内存(old generation)和永久内存(Permanent Generation for VM Matedata)。
在JDK8中,存放元数据中的永久内存从堆内存中移到了本地内存(native memory)中,因此不再占用堆内存。这一改变有助于避免由于永久内存不足而导致的内存溢出错误。同时,JDK8中方法区的实现也发生了变化,它现在存在于元空间(Metaspace)中,且元空间与堆内存不再连续,而是存在于本地内存中。
Java内存模型(JMM)
Java内存模型(JMM,Java Memory Model)主要关注的是线程之间如何通信,以及如何确保线程之间共享数据的一致性。
JMM 是 JVM 规范的一部分,它定义了多线程对共享变量的访问规则、可见性、有序性和原子性。
JMM 的设计目的是为了保证在多线程环境下程序执行的一致性和可预测性。
JMM 把内存分为两块,一块是私有线程的工作区域(工作内存),一块是所有线程的共享区域(主内存)线程跟线程之间是相互隔离,线程跟线程交互需要通过主内存。
JMM的特性
为了保证下述特性,Java内存模型采用了一些机制,如happens-before原则,它是一组必须遵守的规则,确保了多线程环境下变量更新的可见性。当一个线程的某个操作发生在另一个线程的操作之前时,就意味着前者对后者有发生的影响。
可见性
可见性是指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。Java内存模型是通过在变量修改时记录锁标识(如synchronized关键字)来保证可见性的。当一个变量被声明为volatile时,也会提供一种较弱形式的可见性保证。
原子性
原子性是指一个操作要么全部完成,要么全部不完成,不会中断。Java内存模型中基本数据类型的赋值操作具有原子性。对于复合操作(如i++),如果不特别标记(如使用synchronized),则不具备原子性。
有序性
有序性是指程序执行的顺序按照代码的先后顺序来进行,但由于指令重排序的存在,实际执行可能会与代码顺序有所不同。Java内存模型通过锁和volatile等关键字来强制执行上下文的有序性。
指令重排序
指令重排序是为了优化程序执行效率,编译器和处理器可能会改变语句的执行顺序,只要最终结果与按照原顺序执行的结果相同。虽然大多数情况下这种重排序不会影响单线程程序的正确性,但对于多线程程序来说,就可能会影响程序的正确性。
JMM的内存溢出情况
- 栈内存溢出:如果请求栈的深度过大而超出了栈所能承受的范围,就会抛出StackOverflowError错误。这通常发生在有大量递归调用的情况下。
- 堆内存溢出:当堆内存不足以存放更多的对象时,会发生堆内存溢出。错误信息通常显示为:java.lang.OutOfMemoryError: Java heap space。
- 方法区/元空间内存溢出:如果加载的类过多或者常量池中保存的常量过多、动态代理导致反复生成的类型过多,都有可能导致方法区/元空间的内存溢出。
虚拟机栈
含义:每个线程运行时所需要的内存。每个虚拟机栈(Stack)由多个栈帧(Stack Frame)组成,对应着每次方法调用时所占用的内存。每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。
栈帧中主要保存3 类数据:
本地变量(Local Variables):输入参数和输出参数以及方法内的变量
栈操作(Operand Stack):记录出栈、入栈的操作; 栈帧数据(Frame Data):包括类文件、方法等。
栈中的数据都是以栈帧(Stack Frame)的格式存在 遵循“先进后出”/“后进先出”原则
栈内存溢出:栈帧过多(递归调用),或栈帧过大
类加载器
含义:通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。 负责加载class文件,class文件在文件开头有特定的文件标示,并且ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定。
作用:在类加载过程中,获取并加载字节码(.class文件),放到内存中,转换成二进制文件(byte[]),并调用虚拟机底层方法将二进制文件转换成方法区和堆中的数据。
类型:
- 启动类加载器(Bootstrap Class Loader):加载核心jar包(JAVA_HOME/jre/lib目录下的库)
- 扩展类加载器(Extensions Class Loader):加载通用的扩展jar包(JAVA_HOME/jre/lib/ext目录中的类)
- 应用程序类加载器(Application Class Loader):加载项目中的类、maven中的引用的jar包等(加载classPath下的类)
类加载的过程:
- 加载、验证、准备、解析、初始化。然后是使用和卸载
- 通过全限定名来加载生成 class 对象到内存中,然后进行验证这个 class 文件,包括文 件格式校验、元数据验证,字节码校验等。准备是对这个对象分配内存。
- 解析是将符 号引用转化为直接引用(指针引用),初始化就是开始执行构造器的代码
类的生命周期,类装载的执行过程
加载:类加载器根据类的全限定名获取类的二进制数据流,解析二进制数据流为方法区内的Java类模型,最后创建java.lang.Class类的实例
连接:
- 验证:验证内容是否满足《Java虚拟机规范》(文件格式验证、元信息验证、验证程序执行指令的语义、符号引用验证)
- 准备:给静态变量赋初值
- 解析:将常量池中的符号引用替换成指向内存的直接引用。
初始化:执行字节码文件中
clinit方法的字节码指令,包含了静态代码块中的代码,并为静态变量赋值使用:调用静态类成员信息、使用new关键字为其创建对象实例、执行用户的程序代码
卸载(详见垃圾回收):代码执行完毕后,JVM销毁Class对象
双亲委派机制
双亲委派机制:当一个类加载器接收到加载类的任务时,会向上查找是否加载过,如果加载过,就直接返回,如果没有加载,就向下委派子类加载。
作用:
- 避免核心类库被覆写,确保完整性、安全性。
- 避免某一个类被重复加载,确保唯一性。
如何打破双亲委派机制?
自定义类加载器:定义类加载器并且重写
loadclass方法,去除双亲委派机制的代码(Tomcat的应用之间类隔离)。线程上下文类加载器:利用SPI机制和上下文类加载器加载类,比如
JDBC、JNDI、JCE、JAXB和JBI等JDBC案例:
- 启动类加载器加载DriverManager。
- 在初始化DriverManager时,通过SPI机制加载jar包中的myq驱动。
- SPI中利用了线程上下文类加载器(应用程序类加载器)去加载类并创建对象。
OSGi框架的类加载器:OSGi框架实现了一套新的类加载器机制,允许同级之间委托进行类的加载
方法区
运行时数据区域(JDK1.8)
线程不共享:
程序计数器:记录当前要执行的字节码指令的地址。可以控制程序指令的进行实现分支、跳转、异常等逻辑。
虚拟机栈:采用栈的数据结构来管理方法调用中的基本数据,每一个方法的调用使用一个栈帧来保存。
栈帧(StackFrame)的组成:
局部变量表:在运行过程中存放所有的局部变量。数据结构是一个数组,数组中每一个位置称之为槽(slot),long和double类型占用两个槽,其他类型占用一个槽。
操作数栈:在执行指令过程中用来存放临时数据的一块区域。
帧数据:主要包含动态链接、方法出口、异常表的引用。
本地方法栈:与上雷同,用来管理native本地方法的栈帧。
线程共享:
堆:用来存放创建出来的对象。栈的局部变量表存放堆上对象的引用。静态变量也可以存放堆对象的引用,通过静态变量就可以实现对象在线程之间共享。
方法区:存放类的元信息(基本信息)和运行时常量池,在类的加载阶段完成,方法区是线程共享的。JDK7及之前,方法区存放在堆区域的永久代中,JDK8及之后,方法去存放在直接内存的元空间中。
- 类的元信息:保存了所有类的基本信息
- 运行时常量池:保存了字节码文件中的常量池内容
- 字符串常量池:保存了字符串常量
字符串常量池和运行时常量池的关系:
- JDK6及之前:运行时常量池包含字符串常量池,hotspot虚拟机对方法区的实现为永久代。
- JDK7:字符串常量池被从方法区拿到了堆中,运行时常量池剩下的东西还在永久代。
- JDK8及之后:hotspot用元空间取代了永久代,字符串常量池还在堆。
直接内存(非运行时数据区的一部分):为了在NIO的使用中,减少对用户的影响,以及提升写文件和读文件的效率,在JDK8及之后,还可以保存方法区中的数据。
运行时数据区域版本变化(JDK 6~8)
| JDK版本 | 线程共享的 | 线程不共享的 |
|---|---|---|
| JDK6 | 程序计数器、Java虚拟机栈、本地方法栈 |  |
| JDK7 | 程序计数器、Java虚拟机栈、本地方法栈 |  |
| JDK8 | 程序计数器、Java虚拟机栈、本地方法栈 |  |
方法区的垃圾回收
尽管方法区主要用于存储类的元数据,理论上来说这些信息是比较稳定的,但是这并不意味着方法区内不会发生垃圾回收。
实际开发中,类是被应用程序的类加载器创建的,所以开发中方法区的回收一般很少出现,但在如OSGi、JSP的热部署等应用场景中会出现。每个JSP文件对应一个唯一的类加载器,当一个JSP文件被修改了,就直接卸载这个JSP类加载器。重新创建类加载器,重新加载jsp文件。
以下是一些可能导致方法区垃圾回收的情况:
类卸载(Class Unloading)
- 当一个类不再被引用,并且满足某些条件时,JVM 可能会卸载该类,从而释放方法区内存。这种情况通常发生在使用了类加载器的应用程序中,比如 Web 应用服务器,在应用停止或重新部署时,旧的类加载器和其加载的类可以被卸载。
常量池的清理
- 方法区内还存放着类的常量池(Constant Pool),如果常量池中的某个常量不再被任何地方引用,那么这个常量就成为了垃圾。例如,当一个字符串常量没有引用时,它可以被回收。
动态代理类的回收
- 在 Java 中使用动态代理时,会生成一些临时类,如果这些类不再被引用,那么这些类也可以被回收。
编译后的代码缓存
- 在 JDK 8 及以后的版本中,JIT(Just-In-Time)编译器产生的代码缓存也位于方法区(元空间)。如果这些代码缓存不再有用,也可以被清理。
如何触发方法区的垃圾回收?
方法区的垃圾回收通常不是频繁发生的,因为它主要关注的是类的生命周期。然而,当系统面临内存压力,特别是当方法区内存不足时,JVM 会尝试进行类的卸载。
可以通过以下方式触发方法区的垃圾回收:
- **调用 System.gc() 或 Runtime.getRuntime().gc()**:虽然这些方法不保证一定能触发垃圾回收,但在某些情况下,它们可能会导致整个 JVM 进行一次全面的垃圾回收,包括方法区。
- 使用特定的垃圾收集器:某些垃圾收集器(如 G1)可以在进行常规堆垃圾回收的同时,对方法区进行一定的清理。
堆
含义:类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,保存所有引用类型的真实信息,以方便执行器执行。
新生代(Young Generation)
新生代是堆的一部分,主要用于存储新创建的对象。新生代通常被进一步划分为以下几个子区域:
Eden 区
- 定义:Eden 区是新生代的一部分,新创建的对象首先被放置在这里。
- 作用:Eden 区是新对象的初始存储区域,当对象创建时,它们首先被放置在 Eden 区。
- 特性:Eden 区的空间通常较小,因为新创建的对象很快会被垃圾回收。
幸存者区(Survivor Spaces)
- 定义:幸存者区有两个,分别是 Survivor0 和 Survivor1(通常称为 From 和 To),用于存储经过第一次垃圾回收后仍然存活的对象。
- 作用:在经过一次 Minor GC(年轻代垃圾回收)之后,Eden 区中的对象如果仍然存活,会被移动到幸存者区之一。
- 特性:幸存者区的大小通常较小,对象在这里会经历多次 Minor GC,如果仍然存活,则会被移动到老年代。
老年代(Old Generation)
- 定义:老年代是堆的另一部分,用于存储经过多次垃圾回收仍然存活的对象。
- 作用:当对象在幸存者区中存活了一定次数(通过年龄计数器 Age Counter),或者对象太大无法放入幸存者区时,会被移动到老年代。
- 特性:老年代的空间通常较大,因为这里存储的是较为稳定的对象,垃圾回收的频率较低。
永久代(Permanent Generation) [JDK 6 & 7]
- 定义:永久代(PermGen)用于存储类的元数据、常量池等信息。
- 作用:在 JDK 6 和 7 中,永久代是用于存储类的元数据的区域。
- 特性:永久代的垃圾回收主要是针对常量池中的常量。在 JDK 8 中,永久代被移除了,类的元数据被存储在元空间中。
元空间(Metaspace) [JDK 8]
- 定义:元空间用于存储类的元数据。
- 作用:在 JDK 8 中,类的元数据从永久代移动到了元空间,元空间使用本地内存(Native Memory)而非 JVM 堆内存。
- 特性:元空间的大小不受 JVM 堆大小的限制,而是受到系统可用物理内存和系统参数
-XX:MaxMetaspaceSize的限制。
直接内存(Direct Memory) [Off-Heap Memory]
- 定义:直接内存不属于堆的一部分,但它仍然与 JVM 相关。
- 作用:直接内存用于通过
java.nio.ByteBuffer.allocateDirect()分配的内存,主要用于 NIO(Non-blocking I/O)操作。 - 特性:直接内存不在 JVM 堆中,因此不受 JVM 垃圾回收的影响。但是,直接内存的大小仍然需要管理,可以通过
-XX:MaxDirectMemorySize参数来设置。
堆的垃圾回收过程
Minor GC(年轻代垃圾回收)
- 触发条件:当 Eden 区满时,会触发 Minor GC。
- 过程:Minor GC 会清理 Eden 区和两个幸存者区中的垃圾对象。存活的对象会被移动到另一个幸存者区或晋升到老年代。
- 策略:常用的算法有复制算法(Copying),它只需要保留一半的内存即可完成垃圾回收。
Major GC / Full GC(全堆垃圾回收)
- 触发条件:当老年代空间不足时,会触发 Full GC;或者显式调用
System.gc()或Runtime.getRuntime().gc()。 - 过程:Full GC 会清理整个堆,包括年轻代和老年代。
- 策略:通常使用标记-清除(Mark-Sweep)或标记-清除-压缩(Mark-Sweep-Compact)算法,以避免碎片化的问题。
Parallel GC / Concurrent GC
- Parallel GC:并行垃圾回收器,它使用多线程来加速垃圾回收过程。适合 CPU 密集型的应用程序。
- Concurrent GC:并发垃圾回收器,它允许垃圾回收过程与应用程序的执行同时进行,减少应用程序暂停的时间(GC pause time),提高响应速度。适合那些对延迟敏感的应用场景。
堆垃圾回收的优化
为了优化堆的垃圾回收性能,可以调整以下参数:
- 调整堆大小:通过
-Xms和-Xmx设置初始和最大堆大小。 - 选择垃圾收集器:根据应用程序的需求选择合适的垃圾收集器,如 CMS Collector、G1 Collector 或 ZGC、Shenandoah 等。
- 调整年轻代与老年代的比例:通过
-XX:NewRatio参数调整年轻代与老年代的大小比例。 - 控制晋升到老年代的对象:通过
-XX:PretenureSizeThreshold控制对象直接晋升到老年代的大小阈值。 - 设置幸存者区大小:通过
-XX:SurvivorRatio设置 Eden 区与幸存者区的比例。
堆分为三部分:
Young Generation Space 新生代 Young
1
2
3
4
5
6
7
8
9
10
11
12新生区是类的诞生、成长、消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。
新生区又分为两部分: 伊甸区(Eden space)和幸存者区(Survivor pace) ,所有的类都是在伊甸区被new出来的。
幸存区有两个: 0区(Survivor 0 space)和1区(Survivor 1 space)。
当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC),将伊甸园区中的不再被其他对象所引用的对象进行销毁。
然后将伊甸园中的剩余对象移动到幸存 0区。若幸存 0区也满了,再对该区进行垃圾回收,然后移动到 1 区。
那如果1 区也满了呢?再移动到养老区。
若养老区也满了,那么这个时候将产生Major GC(FullGC),进行养老区的内存清理。
若养老区执行了Full GC之后发现依然无法进行对象的保存,就会产生OOM异常“OutOfMemoryError”。
如果出现java.lang.OutOfMemoryError: Java heap space异常,说明Java虚拟机的堆内存不够。
原因有二:
(1)Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整。
(2)代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。 ----内存溢出;内存泄漏Tenure generation space 老年代 Old
1
老年区用于保存从新生区筛选出来的 JAVA 对象,一般池对象都在这个区域活跃。
Permanent Space 永久代 Perm
1
2
3
4
5永久存储区是一个常驻内存区域,用于存放JDK自身所携带的 Class,Interface 的元数据,也就是说它存储的是运行环境必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭 JVM 才会释放此区域所占用的内存。
如果出现java.lang.OutOfMemoryError: PermGen space,说明是Java虚拟机对永久代Perm内存设置不够。
一般出现这种情况,都是程序启动需要加载大量的第三方jar包。
例如:在一个Tomcat下部署了太多的应用。或者大量动态反射生成的类不断被加载,最终导致Perm区被占满。
Jdk1.8及之后在元空间
判断一个对象是否存活有两种方法:
引用计数法
所谓引用计数法就是给每一个对象设置一个引用计数器,每当有一个地方引用这个对象 时,就将计数器加一,引用失效时,计数器就减一。当一个对象的引用计数器为零时,说明此对象没有被引用,也就是“死对象”,将会被垃圾回收。
引用计数法有一个缺陷就是无法解决循环引用问题,也就是说当对象 A 引用对象 B,对象 B 又引用者对象 A,那么此时 A,B 对象的引用计数器都不为零,也就造成无法完成垃圾回收,所以主流的虚拟机都没有采用这种算法。
可达性算法(引用链法)
1 | 该算法的思想是:从一个被称为 GC Roots 的对象开始向下搜索,如果一个对象到 GC Roots 没有任何引用链相连时,则说明此对象不可用。 |
垃圾回收
对象能否被回收,是根据对象是否被引用了来决定的。只有无法通过引用获取到对象时,该对象才能被回收;如果对象被引用了,说明该对象还在使用,不允许被回收。
GC的判断方法
引用计数法:
为每个对象维护一个引用计数器,当对象被引用时加1,取消引用时减1。当对象计数为0时就会触发回收机制。无法解决循环引用的垃圾回收。
引用类型
强引用:如果对象在根对象的引用链上,则不能被回收。
软引用:如果对象被软引用关联,当程序内存不足时会回收。
在JDK1.2版之后提供了SoftReference类来实现软引用,软引用常用于缓存中。
弱引用:和软引用基本一致,区别在于弱引用在垃圾回收时,会被直接回收。
在JDK1.2版之后提供了WeakReference类来实现弱引用,弱引用主要在ThreadLocal中使用。弱引|用对象本身也可以使用引|用队列进行回收。
虚引用:无法获取包含的对象。唯一用途是当对象被回收时,可以接收到对应的通知,知道对象被回收了。
Java中使用PhantomReference实现了虚引用,使用虚引用实现了直接内存中为了及时知道直接内存对象不再使用,从而回收内存。
终结器引用:对象回收时可以自救,不建议使用。(在对象需要被回收时,对象将会被放置在Finalizer类中的引用队列中,并在稍后由一条由FinalizerThread线程从队列中获取对象,然后执行对象的finalize方法(再将自身对象使用强引用关联上))
可达性分析法:
如果从某个到GC Root对象是可达的,对象就不可被回收。
根对象(不可回收):
- 线程Thread对象
- 系统类加载器加载的java.lang.Class对象
- 监视器对象,用来保存同步锁synchronized关键字持有的对象
- 本地方法调用时使用的全局对象
触发GC的时机
- 新生代空间不足:当新生代空间不足时,会触发Minor GC。如果Minor GC之后仍然空间不足,则触发Full GC。
- 老年代空间不足:当老年代空间不足时,会先尝试触发Minor GC,如果之后空间仍不足,则会触发Full GC。
- 元空间不足:元空间存放类的元数据,当元空间不足时也会触发Full GC。
- 显式调用
System.gc():虽然System.gc()方法的调用是一个建议,但很多情况下JVM会响应这个请求并触发Full GC。 - 通过Minor GC后进入老年代的平均大小大于老年代的可用内存:如果发现这个平均值大于老年代的可用内存,则会在Minor GC前先进行一次Full GC。
- 定时触发:某些情况下,GC可能会基于时间间隔或其他策略被触发。
GC算法
垃圾回收算法评价标准:
- 吞吐量:指的是CPU用于执行用户代码的时间与CPU总执行时间的比值,即吞吐量=执行用户代码时间 /(执行用户代码时间+GC时间)。吞吐量数值越高,垃圾回收的效率就越高。
- 最大暂停时间:指的是所有在垃圾回收过程中的STW时间最大值。
- 堆使用效率:不同垃圾回收算法,对堆内存的使用方式是不同的。比如标记清除算法,可以使用完整的堆内存。而复制算法会将堆内存一分为二,每次只能使用一半内存。从堆使用效率上来说,标记清除算法要优于复制算法。
标记-清除算法:先标记,标记完毕之后再清除,效率不高,会产生碎片
- 标记阶段,使用可达性分析算法将所有存活的对象进行标记,从GCRoot开始通过引用链遍历出所有存活对象。
- 清除阶段,从内存中删除没有被标记的非存活对象。
优点:实现简单,只需要在第一阶段给每个对象维护标志位,第二阶段删除对象即可。
缺点:
- 碎片化问题由于内存是连续的,所以在对象被删除之后,内存中会出现很多细小的可用内存单元。如果我们需要的是一个比较大的空间,很有可能这些内存单元的大小过小无法进行分配。
- 分配速度慢。由于内存碎片的存在,需要维护一个空闲链表,极有可能发生每次需要遍历到链表的最后才能获得合适的内存空间。
标记-整理(标记-压缩)算法:标记完毕之后,让所有存活的对象向一端移动
是对
标记-清理算法中容易产生内存碎片问题的一种解决方案。- 标记阶段,将所有存活的对象进行标记。使用可达性分析算法,从GCRoot开始通过引l用链遍历出所有存活对象。
- 整理阶段,将存活对象移动到堆的一端。清理掉存活对象的内存空间。
优点:
- 内存使用效率高。整个堆内存都可以使用,不会像复制算法只能使用半个堆内存。
- 不会发生碎片化。在整理阶段可以将对象往内存的一侧进行移动,剩下的空间都是可以分配对象的有效空间。
缺点:整理阶段的效率不高。整理算法有很多种,比如
Lisp2整理算法需要对整个堆中的对象搜索3次,整体性能不佳。可以通过Two-Finger、表格算法、ImmixGc等高效的整理算法优化此阶段的性能。复制算法:分为 8:1 的 Eden 区和 survivor 区,就是上面谈到的 YGC
- 将堆内存分割成两块From空间To空间,对象分配阶段,创建对象。
- GC阶段开始,将GC Root搬运到To空间。
- 将GCRoot关联的对象,搬运到To空间。
- 清理From空间,并把名称互换。
优点:
- 吞吐量高。复制算法只需要遍历一次存活对象复制到To空间即可,比标记-整理算法少了一次遍历的过程,因而性能较好,但是不如标记-清除算法因为标记清除算法不需要进行对象的移动。
- 不会发生碎片化。复制算法在复制之后就会将对象按顺序放入To空间中,所以对象以外的区域都是可用空间,不存在碎片化内存空间。
缺点:内存使用效率低。每次只能让一半的内存空间来为创建对象使用。
分代垃圾回收(分代GC)
- 将整个内存区域划分为年轻代和老年代。
- 分代回收时,创建出来的对象,首先会被放入Eden伊甸园区。
- 随着对象在Eden区越来越多,Eden区满了就会触发年轻代的GC(Minor GC / Young GC),将不需要回收的对象放到To区,新创建的对象继续放到Eden区。
- 如果MinorGC后对象的年龄达到阈值(最大15,最小为0,默认值和垃圾回收器有关),对象就会被晋升至老年代。
- 当老年代中空间不足,无法放入新的对象时,先尝试Minor GC如果还是不足,就会触发Full GC,Full GC会对整个堆进行垃圾回收。
- 如果Full GC依然无法回收掉老年代的对象,那么当对象继续放入老年代时,就会抛出Out Of Memory异常。
垃圾回收器
垃圾回收器的发展
Serial 收集器:最早期的垃圾收集器,适用于小型应用或测试环境,几十兆的内存大小。
Parallel 收集器:随着硬件进步,内存容量增加,适用于几个G的内存大小。
CMS 收集器:在JDK 1.4版本后期引入,开启了并发垃圾回收的时代,适用于几十个G的内存大小,但由于其并发标记阶段会影响应用程序性能,并且存在碎片化问题。
G1 收集器:设计用于上百GB的内存大小,通过并行和并发的方式进行垃圾回收,减少了Stop-The-World(STW)时间。
ZGC 和 Shenandoah:设计用于更大的内存范围,从几百GB到TB级别的内存,减少了STW时间到毫秒级别。
垃圾回收器介绍
- Serial 收集器:
- 适用于年轻代的串行回收,适合内存较小的应用环境。
- **Parallel Scavenge 收集器 (PS)**:
- 适用于年轻代,并行回收,适用于内存较大的应用环境。
- ParNew 收集器:
- 是 Serial 收集器的一个变种,支持年轻代的并行回收,主要用来配合 CMS 收集器使用。
- Serial Old 收集器:
- 适用于老年代的串行回收,通常作为 CMS 收集器在无法分配新对象时的后备方案。
- Parallel Old 收集器:
- 适用于老年代,并行回收。
- **CMS 收集器 (Concurrent Mark Sweep)**:
- 适用于老年代,采用并发标记和清扫的方式,减少 STW 时间,但由于标记算法的原因,容易产生内存碎片。
- G1 收集器:
- 适用于大内存环境,采用三色标记算法和SATB(Store After Barrier)机制,减少了 STW 时间。
- ZGC 收集器:
- 设计用于非常大的内存范围,采用 Colored Pointers 和 Load Barrier 技术,进一步减少 STW 时间。
- Shenandoah 收集器:
- 也是为了解决 STW 问题,采用 Colored Pointers 和 Write Barrier 技术。
- Epsilon 收集器:
- 这是一个“无操作”的垃圾收集器,仅用于研究目的或特殊场合,不执行任何垃圾回收工作。
关键算法和技术
三色标记算法:一种并发标记算法,用于并发垃圾回收过程中标识对象的状态。
- 白色:表示尚未被访问的对象。这些对象可能是垃圾,也可能不是。
- 灰色:表示已经被访问但其引用的对象尚未被访问的对象。这些对象是当前正在处理的对象。
- 黑色:表示已经被完全访问的对象。这些对象及其引用的对象都被认为是存活的。
算法步骤
- 初始化:
- 将所有对象标记为白色。
- 将根对象(如全局变量、栈上的局部变量等)标记为灰色。
- 标记阶段:
- 从灰色对象队列中取出一个对象,将其标记为黑色。
- 将该对象引用的所有白色对象标记为灰色,并将这些对象加入灰色对象队列。
- 重复上述过程,直到灰色对象队列为空。
- 清理阶段:
- 所有仍标记为白色的对象被认为是垃圾,可以被回收。
Incremental Update:一种在并发标记过程中更新对象引用的技术。
**SATB (Store After Barrier)**:一种在对象更新时记录写操作的技术。
Colored Pointers:一种指针技术,使得对象可以直接携带有关其状态的信息,简化了并发回收过程中的对象检查。
Load Barrier 和 Write Barrier:在读取或写入对象时插入的屏障,确保垃圾回收的安全性。
JVM中的垃圾回收器
垃圾回收器是垃圾回收算法的具体实现,在JVM中,实现了多种垃圾收集器,包括:
- 串行垃圾收集器
- Serial和Serial Old串行垃圾收集器,是指使用单线程进行垃圾回收,堆内存较小,适合个人电脑
- Serial 作用于新生代,采用复制算法
- Serial Old 作用于老年代,采用标记-整理算法
- 垃圾回收时,只有一个线程在工作,并且java应用中的所有线程都要暂停(STW),等待垃圾回收的完成。
- 并行垃圾收集器
- Parallel New和Parallel Old是一个并行垃圾回收器,JDK8默认使用此垃圾回收器
- Parallel New作用于新生代,采用复制算法
- Parallel Old作用于老年代,采用标记-整理算法
- 垃圾回收时,多个线程在工作,并且java应用中的所有线程都要暂停(STW),等待垃圾回收的完成。
- CMS(并发)垃圾收集器
- CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,该回收器是针对老年代垃圾回收的,是一款以获取最短回收停顿时间为目标的收集器,停顿时间短,用户体验就好。其最大特点是在进行垃圾回收时,应用仍然能正常运行。
- G1垃圾收集器
- 应用于新生代和老年代,在JDK9之后默认使用G1
- 划分成多个区域,每个区域都可以充当 eden,survivor,old, humongous,其中 humongous 专为大对象准备
- 采用复制算法
- 响应时间与吞吐量兼顾
- 分成三个阶段:新生代回收、并发标记、混合收集
- 如果并发失败(即回收速度赶不上创建新对象速度),会触发 Full GC
由于垃圾回收器分为年轻代和老年代,除了G1之外其他垃圾回收器必须成对组合进行使用,具体的关系图如下:
- 年轻代-Serial垃圾回收器 + 老年代-SerialOld垃圾回收器
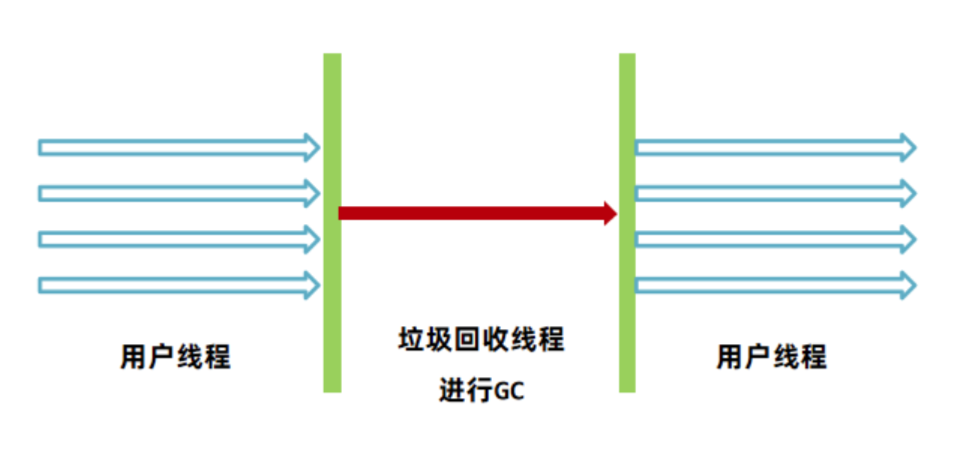
| 回收年代 | 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 年轻代 | 复制算法 | 单CPU处理器下吞吐量非常出色 | 多CPU下吞吐量不如其他垃圾回收器,堆如果偏大会让用户线程处于长时间的等待 | Java编写的客户端程序或者硬件配置有限的场景 |
| 回收年代 | 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 老年代 | 标记-整理算法 | 单CPU处理器下吞吐量非常出色 | 多CPU下吞吐量不如其他垃圾回收器,堆如果偏大会让用户线程处于长时间的等待 | 与Serial垃圾回收器搭配使用,或者在CMS特殊情况下使用 |
年轻代-ParNew垃圾回收器 + 老年代- CMS(Concurrent Mark Sweep)垃圾回收器

| 回收年代 | 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 年轻代 | 复制算法 | 多CPU处理器下停顿时间较短 | 吞吐量和停顿时间不如G1,所以在JDK9之后不建议使用 | JDK8及之前的版本中,与CMS老年代垃圾回收器搭配使用 |
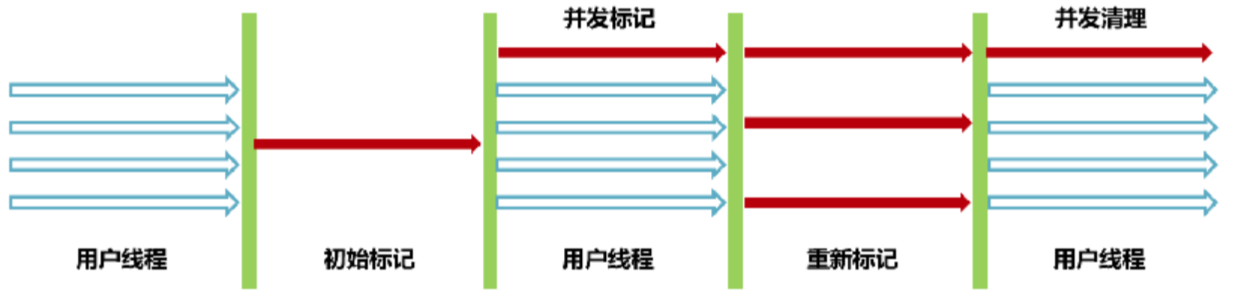
| 回收年代 | 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 老年代 | 标记-清除算法 | 系统由于垃圾回收出现的停顿时间较短,用户体验好 | 内存碎片问题、退化问题、浮动垃圾问题 | 大型的互联网系统中用户请求数据量大、频率高的场景,比如订单接口、商品接口等 |
CMS执行步骤:
1.初始标记,用极短的时间标记出GC Roots能直接关联到的对象。
2.并发标记, 标记所有的对象,用户线程不需要暂停。
3.重新标记,由于并发标记阶段有些对象会发生了变化,存在错标、漏标等情况,需要重新标记。
4.并发清理,清理死亡的对象,用户线程不需要暂停。
缺点:
1、CMS使用了标记-清除算法,在垃圾收集结束之后会出现大量的内存碎片,CMS会在Full GC时进行碎片的整理。这样会导致用户线程暂停,可以使用-XX:CMSFullGCsBeforeCompaction=N 参数(默认0)调整N次Full GC之后再整理。
2.、无法处理在并发清理过程中产生的“浮动垃圾”,不能做到完全的垃圾回收。
3、如果老年代内存不足无法分配对象,CMS就会退化成Serial Old单线程回收老年代。
- 年轻代-Parallel Scavenge垃圾回收器 + 老年代-Parallel Old垃圾回收器(JDK 1.8默认的垃圾回收器)
| 回收年代 | 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 年轻代 | 复制算法 | 吞吐量高,而且手动可控。为了提高吞吐量,虚拟机会动态调整堆的参数 | 不能保证单次的停顿时间 | 后台任务,不需要与用户交互,并且容易产生大量的对象。比如:大数据的处理,大文件导出 |
| 回收年代 | 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 老年代 | 标记-整理算法 | 并发收集,在多核CPU下效率较高 | 暂停时间会比较长 | 与Parallel Scavenge配套使用 |
- G1垃圾回收器(JDK9之后强烈建议)
- 支持巨大的堆空间回收,并有较高的吞吐量。
- 支持多CPU并行垃圾回收。
- 允许用户设置最大暂停时间。
G1的整个堆会被划分成多个大小相等的区域,称之为区Region,区域不要求是连续的。分为Eden、Survivor、Old区。Region的大小通过堆空间大小/2048计算得到,也可以通过参数-XX:G1HeapRegionSize=32m指定(其中32m指定region大小为32M),Region size必须是2的指数幂,取值范围从1M到32M。
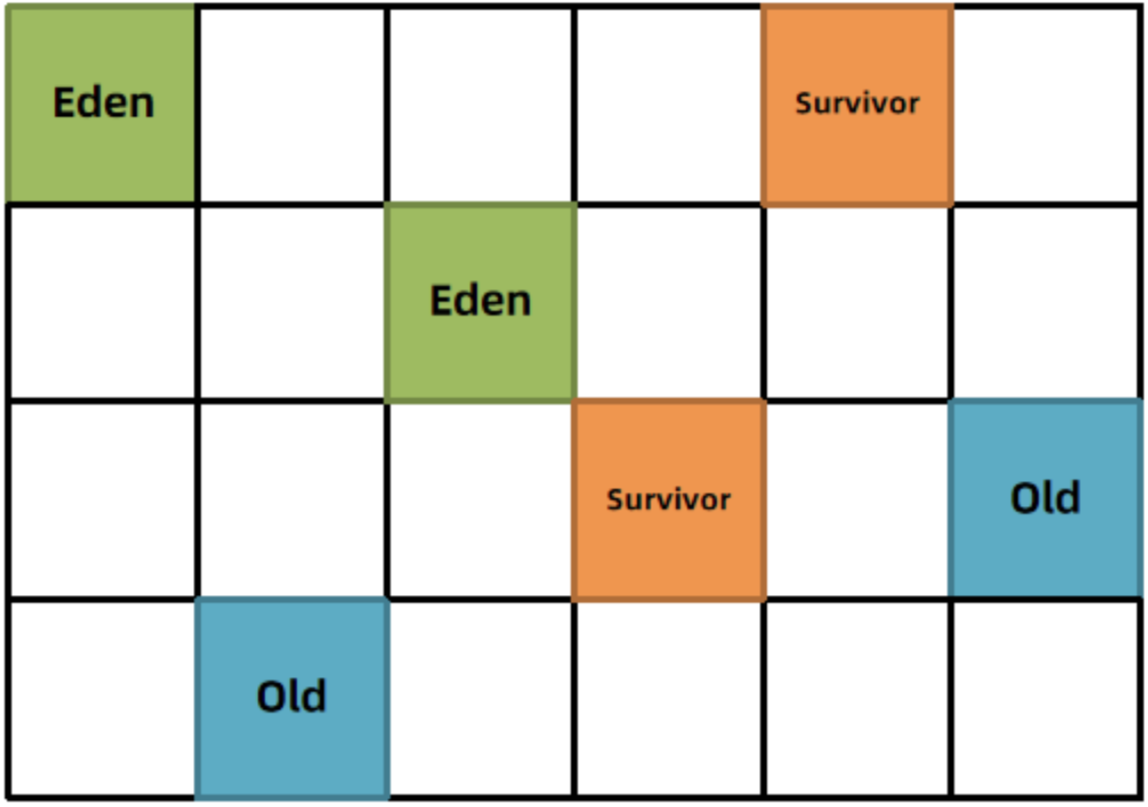
回收过程:(简略版)
当G1判断年轻代区不足(max默认60%),无法分配对象时需要回收时会执行Young GC。
根据配置的最大暂停时间选择某些区域将存活对象复制到一个新的Survivor区中(年龄+1),清空这些区域。
- 当某个存活对象的年龄到达阈值(默认15),将被放入老年代。
- 部分对象如果大小超过Region的一半,会直接放入老年代,这类老年代被称为Humongous区。比如堆内存是4G,每个Region是2M,只要一个大对象超过了1M就被放入Humongous区,如果对象过大会横跨多个Region。
- 多次回收之后,会出现很多Old老年代区,此时总堆占有率达到阈值45%(默认)时,会触发混合回收MixedGC(过程略)。回收所有年轻代和部分老年代的对象以及大对象区。采用复制算法来完成。
JVM场景题
内存泄漏是指:不再使用的对象仍然占用内存空间,因为垃圾回收器无法回收它们。这种情况下,应用程序会逐渐消耗越来越多的内存,最终可能导致性能下降甚至崩溃。以下是一些常见的导致 Java 应用程序内存泄漏的场景:
1. 静态集合类
当集合类被声明为静态变量时,它们的生命周期与整个应用程序相同,如果不定期清理,会导致内存持续增长。
2. 内部类和 Lambda 表达式
内部类(Inner Class)和 Lambda 表达式可能会持有对外部类的隐式引用,从而阻止垃圾回收。
3. 日志记录
日志记录类可能会持有某个对象的强引用,特别是当使用 MDC(Mapped Diagnostic Context)时,如果不及时清除 MDC 中的信息,可能会导致内存泄漏。
4. 线程局部变量(ThreadLocal)
ThreadLocal 变量如果没有正确地清除,可能导致内存泄漏,因为每个线程都会保留一份拷贝。
————————————-
实习经历:阶梯式阅读2.0 积分模块——杭州施强教育科技有限公司
架构设计
扫码登录设计原理?
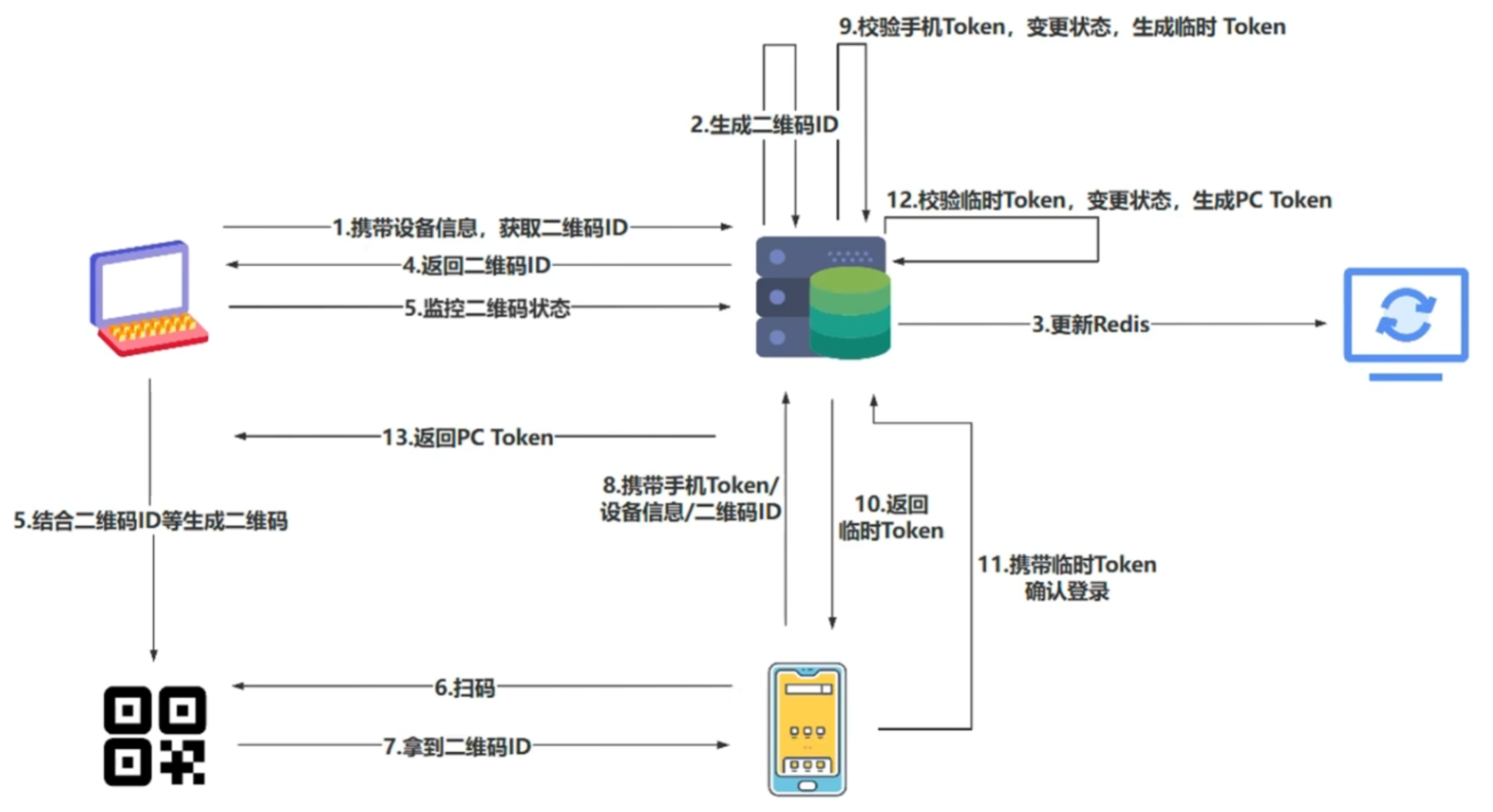
在积分模块的设计中是否使用了设计模式?如果有,请具体说明。
你是如何设计积分模块的数据模型的?请分享一下你的设计思路。
在实现积分规则判断时,你是如何设计规则引擎的?如果后期需要新增或修改规则,该如何实现?
回答:
为了使积分规则的定义和修改更加灵活,我设计了一个基于策略模式的规则引擎。具体而言,每个积分规则被封装成一个独立的策略类,继承统一的接口或抽象类,并实现具体的规则逻辑。在系统初始化时,将这些规则策略类注册到规则引擎中。这样,在执行积分结算时,可以根据用户的行为动态选择并应用相应的规则策略。如果后期需要新增或修改规则,只需添加或修改相应的策略类,无需对现有代码进行大规模改动。
此外,如果系统对规则的复杂性要求更高,我会考虑引入Drools等第三方规则引擎,以实现更复杂的条件判断和规则配置,提升系统的灵活性和可扩展性。
你提到在项目中使用了异步消息队列,为什么选择这种方式?如何保证消息的可靠传递?
回答:
使用异步消息队列的主要原因是为了解耦系统的各个模块,提升系统的并发处理能力。积分结算往往是一个耗时的操作,如果同步执行,会影响用户的实时响应体验。通过消息队列,将积分结算操作放到后台异步处理,不仅减少了前端的响应时间,还能有效地平衡系统负载。
为了保证消息的可靠传递,我在实现中引入了消息持久化和重试机制。消息一旦进入队列,将立即持久化到存储中,以防止因系统故障导致消息丢失。同时,消费端在处理消息时,如果遇到异常情况,会将消息重新放回队列并触发重试机制,直到消息成功处理为止。此外,还可以利用死信队列(DLQ)来处理那些多次重试仍失败的消息,防止消息堆积。
业务实现
在积分结算过程中,你是如何保证数据的一致性和准确性的?
回答:
为确保积分结算的准确性,我采用了乐观锁和事务管理机制。每次积分结算操作都会检查当前数据是否被其他操作修改过,如果发生冲突,系统会自动重试。此外,我将积分结算逻辑封装在事务中,确保在积分计算、数据库更新和通知用户等操作中,任意一步出现问题时,整个操作可以回滚,从而保证数据的一致性。同时,在实际操作中,我还使用了异步消息队列处理一些耗时较长的任务,以提高系统的整体响应速度。
积分模块在高并发场景下如何保证数据一致性?例如,当多个用户同时提交相同的行为时(如提交同一次的积分答题),如何防止积分重复计算?
- HTTP方法幂等性:
- GET请求:GET请求应当是幂等的,这意味着无论调用多少次,返回的结果应该是相同的,并且不应该改变资源的状态。
- PUT请求:PUT请求也应当是幂等的,它用于更新资源的状态,但是同样的请求多次发送应该只产生一次效果。
- DELETE请求:DELETE请求同样要求幂等性,删除资源的请求不应该因为多次发送而产生多次删除的效果。
- 唯一标识符: 给每个请求分配一个唯一的标识符(如UUID),并在请求中携带此标识符。在接收方,根据标识符检查请求是否已经处理过,如果已经处理则直接返回之前的结果。
- 状态码和响应头: 在HTTP响应中使用状态码来表示操作的结果,并且在需要时使用响应头来传递附加信息。例如,使用200 OK来表示成功,使用204 No Content来表示没有内容的幂等操作。
- 数据库约束:
- 使用唯一键约束(UNIQUE约束)来确保数据的唯一性,这样即使尝试多次插入相同的数据也不会成功。
- 利用外键约束(FOREIGN KEY约束)来保证数据的一致性。
- 事务和分布式事务:
- 利用数据库事务来确保一组操作要么全部成功,要么全部失败。
- 对于跨服务的操作,可以使用分布式事务协议(如两阶段提交2PC、三阶段提交3PC)来确保操作的一致性。
- 使用消息队列的幂等性处理:
- 在消息队列中实现幂等性处理逻辑,确保消息被正确消费并且不会因为重复消费而导致数据错误。
- 可以利用消息队列提供的特性(如幂等生产者)来帮助实现幂等性。
如何设计权限控制系统,确保只有授权用户才能查看或修改积分数据?
访问控制模型
基于角色的访问控制(Role-Based Access Control):通过为用户分配不同的角色来实现权限管理的。角色代表了一组权限的集合,用户通过被赋予特定的角色来获得相应的访问权限。
基于属性的访问控制(Attribute-Based Access Control):根据主体(用户)和客体(资源)的属性来决定访问权限的。属性可以包括用户的身份信息、时间、地点、设备状态等,甚至可以是环境条件或业务逻辑中的任意属性。
RBAC和ABAC的区别在于:
- RBAC:权限分配基于角色,用户通过角色来获取权限。角色通常是静态定义的,与企业的组织结构或工作职责相关联。
- ABAC:权限分配基于属性,通过评估一系列属性来决定访问权限。这种方式更为灵活,可以适应复杂的访问控制需求,但同时也可能带来更高的管理复杂度。
权限审计:记录权限分配的历史,便于审核和追踪。
接口安全:使用token鉴权来验证请求的合法性。
在积分模块与其他模块集成时,如何保证数据的一致性和完整性?
1. 事务处理
本地事务:
对于单一数据库操作,确保每个操作都在一个事务中完成,以保证原子性、一致性、隔离性和持久性(ACID)。
分布式事务:
对于跨数据库或服务的操作,可以使用以下几种分布式事务解决方案:
- 两阶段提交(2PC):协调者协调参与者(如数据库)完成事务,分为准备阶段和提交阶段。
- 三阶段提交(3PC):在两阶段提交的基础上增加了预提交阶段,减少了阻塞时间。
- TCC(Try-Confirm-Cancel):预先预留资源,确认后提交,取消则回滚。
- SAGA:长事务模式,通过一系列短事务来实现长事务的效果,每个短事务都是可补偿的。
2. 幂等性处理
2.1 请求幂等性
确保同一个请求多次执行的结果相同,不会重复执行某些操作,如:
- 唯一标识:为每个请求分配一个唯一的标识符(如订单号),在处理请求时先检查该标识符是否存在。
- 状态码:使用 HTTP 状态码来表示请求的幂等性,如
201 Created表示资源已被创建,后续请求可以直接返回200 OK而不需要再次创建。
2.2 消息幂等性
在消息队列中,确保消息被多次消费时不会重复处理:
- 消息去重:在消费端记录已处理的消息标识符,避免重复处理。
- 消息确认机制:确保消息在处理完成后才确认接收,否则重新投递。
3. 异步处理与补偿机制
3.1 异步处理
使用消息队列(如 RabbitMQ、Kafka)来异步处理积分模块与其他模块之间的交互,可以提高系统的吞吐量和响应速度。
3.2 补偿机制
对于无法保证一致性的操作,设计补偿机制来处理异常情况:
- 补偿事务:在 SAGA 模式中,每个短事务都有对应的补偿操作。
- 重试机制:对于可重试的操作,设置重试策略,并记录重试次数和状态。
- 死信队列:对于无法处理的消息,可以发送到死信队列中,后续手动处理或重试。
4. 数据校验与对账
4.1 数据校验
在操作前后进行数据校验,确保数据的一致性:
- 预检查:在执行操作前先进行预检查,如检查账户余额是否足够。
- 后验证:操作完成后再次验证数据状态,如检查积分是否正确更新。
4.2 对账机制
定期对账,确保各个模块之间的数据一致性:
- 定期对账:设置固定的对账周期,如每日对账。
- 差异处理:对账发现差异时,记录差异详情,并进行手动或自动处理。
5. 事件驱动架构
5.1 事件发布与订阅
采用事件驱动架构,通过发布和订阅机制来实现模块间的解耦:
- 事件发布:当积分模块发生变动时,发布事件。
- 事件订阅:其他模块订阅相关事件,并根据事件内容进行相应处理。
假设你有一个积分模块,需要在用户下单时扣减积分,并通知库存模块扣减库存。以下是一个使用 Spring Boot 和 Spring Data JPA 实现的简单示例:
1 |
|
在这个示例中,deductPoints 方法是一个事务性的方法,确保扣减积分的操作在一个事务中完成。如果积分足够,则扣减积分并发布一个 InventoryDeductionEvent 事件,通知库存模块扣减库存。如果积分不足,则抛出异常。
性能优化
你在设计积分模块时是否考虑过性能优化?如果是,采取了哪些措施?
项目中涉及到了排行榜,在设计这个功能时,你是如何优化性能和体验的?有没有使用缓存或者其他技术手段?
回答:
在设计积分排行榜功能时,我使用了Redis作为缓存来提高性能和用户体验。由于排行榜数据通常是高频访问的数据,直接从数据库中查询会导致性能瓶颈。因此,我将排行榜的热点数据缓存到Redis中,并设置适当的过期时间,以便定期更新和刷新数据。此外,Redis的有序集合(Sorted Set)数据结构非常适合用于存储和操作排行榜数据,可以高效地进行排名计算和排序。
在用户访问排行榜时,系统会首先从Redis中读取数据。如果缓存命中,则直接返回;如果缓存未命中,则从数据库中查询并更新缓存。通过这种方式,我们既保证了数据的实时性,又大幅提高了系统的响应速度和用户体验。
如果未来用户基数增长迅速,积分模块需要做哪些改进来保证可扩展性?
TODO
如何确保在高并发情况下积分系统的稳定性和准确性?
- 积分操作使用使用事务处理
- 用户积分操作时使用乐观锁
- 积分日志操作可以使用队列系统
- 积分日志表使用索引优化,加快查询
你是如何评估积分模块的性能瓶颈的?使用了哪些工具和技术?
- 应用性能监控(APM)工具: 使用APM工具(如New Relic, Dynatrace, Pinpoint等)来实时监控应用程序的性能,收集有关请求处理时间、CPU使用率、内存消耗等信息。
- 日志分析: 分析应用日志和系统日志,查找可能导致性能问题的异常或警告信息。
- 数据库性能监控: 使用专门的数据库性能监控工具(如MySQL Performance Schema, PostgreSQL的pgAdmin等)来监控数据库的性能,特别是慢查询分析。
- 系统监控工具: 使用系统监控工具(如Nagios, Zabbix等)来监控服务器的硬件资源使用情况,如CPU、内存、磁盘IO、网络带宽等。
与线程池的联动
积分结算时是否有并发场景?如果有,你是如何处理的?
在积分结算的高并发场景中,你是如何处理分布式事务的?有没有考虑过CAP理论对你设计的影响?
回答:
在高并发场景下,分布式事务是一个挑战。为了处理这个问题,我采用了基于事件驱动的最终一致性策略,而不是传统的分布式锁或两阶段提交。具体做法是,将积分结算的操作封装成事件,通过消息队列进行异步处理。这样做的好处是避免了分布式锁带来的性能瓶颈,同时通过幂等性设计和补偿机制,确保数据最终一致性。
关于CAP理论,在积分结算场景中,我们优先考虑的是AP(可用性和分区容错性),因为系统的高可用性对用户体验至关重要。我们通过消息队列和异步处理确保系统在网络分区的情况下仍能保持高可用性,而一致性则通过幂等操作和重试机制在系统恢复后最终达成。
你在项目中使用了动态线程池的Java组件,这与阅读积分模块有什么关联吗?能否具体说明一下如何结合的?
回答:
在积分模块中,由于需要处理大量的学生阅读数据和积分统计,我使用了自定义的动态线程池来优化系统的性能。通过动态调整线程池的核心线程数和最大线程数,可以根据系统的负载情况灵活调整线程资源,确保在高并发场景下系统的稳定性和响应速度。例如,在阅读高峰期,线程池能够自动扩展以处理大量的积分结算请求,而在系统负载降低时,线程池又可以收缩以节省资源。这一优化不仅提高了系统的吞吐量,也为学生端的流畅体验提供了保障。
你谈到了在阅读高峰期,线程池能够自动扩展以处理大量的积分结算请求,而在系统负载降低时,线程池又可以收缩以节省资源,这是如何实现的,你定义了定时任务吗?还是有其他方法可以实现动态的扩容?
动态调整线程池的实现方式通常有两种:通过定时任务或基于实际运行时的动态监控。
1. 定时任务方式
可以定义一个定时任务,定期检查系统的负载情况(如当前的请求数、CPU使用率、内存占用等)。根据这些指标,动态调整线程池的核心线程数和最大线程数。这种方式实现简单,通过Java中的ScheduledExecutorService来周期性地执行这些调整逻辑。
优点: 实现简单,容易维护。
缺点: 可能存在延迟,无法实时响应突发流量。
代码示例:
1 | ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1); |
2. 基于实际运行时的动态监控
这种方法更加实时。通过监控线程池的运行情况,例如任务队列的长度、活跃线程数等指标,动态地调整线程池参数。Java中的ThreadPoolExecutor本身就提供了这些监控方法,结合实际情况可以实现自动扩容或缩容。
优点: 更加实时,能够迅速响应系统负载变化。
缺点: 实现稍微复杂,需要更复杂的监控和调整逻辑。
代码示例:
1 | // 自定义一个监控任务 |
测试
在测试和维护阶段,你遇到过哪些典型的 bug?你是如何定位和解决这些问题的?
TODO
其他
你在开发中遇到的最大挑战是什么?是如何克服的?
回答:
在开发过程中,最大挑战是如何在高并发场景下保证积分系统的高可用性和一致性。为了克服这个挑战,我做了以下几点工作:
- 异步化处理:将积分结算和一些耗时操作放到后台异步处理,避免了前端响应阻塞。
- 动态线程池优化:通过自定义的动态线程池,根据系统的负载情况自动调整线程资源,确保系统在高并发下仍能保持稳定。
- 消息队列和分布式事务:采用消息队列实现模块解耦,同时引入最终一致性策略,保证系统的数据一致性。
- 缓存优化:利用Redis缓存常用数据,如排行榜信息,减少数据库压力,提高系统的响应速度。
通过这些措施,我不仅解决了高并发带来的性能问题,还确保了系统的稳定性和一致性。
在开发过程中,最大挑战是如何在高并发场景下保证积分结算的实时性和准确性。为解决这个问题,我首先优化了数据库查询和写入的性能,利用索引和缓存减少数据库的压力。同时,通过引入动态线程池组件,灵活调配系统资源应对高并发请求。此外,利用消息队列分离了部分异步任务,将非关键任务延后处理,从而减轻了主流程的压力。最终,这些措施有效提升了系统的性能,确保了积分模块的稳定运行。
你提到在项目中使用了GitLab CI/CD和Rancher,这些工具是如何帮助你在项目后期保持高效开发的?
回答:
在项目后期,需求变更和bug修复的频率增加,为了确保每次代码提交后的版本稳定性,我使用了GitLab CI/CD来自动化构建、测试和部署流程。每次提交代码后,CI/CD管道会自动运行测试,确保代码质量,并在通过测试后自动部署到开发或生产环境。Rancher则用于管理Kubernetes集群,帮助我们轻松实现应用的扩展和升级,确保系统在高并发场景下的稳定性。通过这些工具的配合,我们能够快速响应变化,同时保持高效和稳定的开发流程。
你知道如何设计 GitLab CI/CD 的流水线来支持自动化构建、测试和部署吗?
准备阶段
- 在一台或多台机器上安装GitLab Runner,用于执行CI/CD作业。
- 配置Runner与GitLab服务器关联,并注册到GitLab项目中。
- 在GitLab上创建一个新的仓库,并设置好版本控制相关的策略。
- 编写
.gitlab-ci.yml文件
流水线设计
构建阶段(Build)
构建镜像/编译代码:
- 使用
docker build命令构建Docker镜像(如果项目使用容器化部署)。 - 或者执行编译命令(如
npm install && npm run build对于Node.js项目)。
- 使用
上传工件(Artifacts):
- 将构建好的镜像或编译后的文件上传到GitLab的artifacts存储中,供后续阶段使用。
测试阶段(Test)
单元测试:
集成测试:
代码质量检查:
发布阶段(Deploy)
环境变量管理:
- 在GitLab项目的Settings > CI/CD > Variables中配置不同环境的变量。
环境部署:
- 根据分支或标签的不同,部署到不同的环境(如
staging或production)。 - 使用
deploy关键字指定部署目标和脚本。
- 根据分支或标签的不同,部署到不同的环境(如
—————————————
项目经历:动态线程池组件
项目背景
动态线程池组件的核心功能和应用场景?
核心功能
- 动态调整线程数量:根据当前系统的负载情况,自动增加或减少线程池中的工作线程数量。
- 负载监控:持续监控系统的负载,如CPU利用率、线程池中待处理的任务数量等。
- 资源优化:在低负载时减少线程数量,节约系统资源;在高负载时增加线程数量,提升处理能力。
- 异常处理:当线程池中的线程发生异常时,能够自动恢复或替换线程。
- 策略配置:支持不同的调整策略,如基于时间窗口的平均负载、固定间隔的调整等。
应用场景
- Web 服务器:处理来自用户的HTTP请求,特别是在流量波动较大的场景下。
- 批处理系统:在数据处理过程中,根据数据量的大小动态调整处理线程的数量。
- 分布式系统:在分布式环境中,根据节点的状态和负载情况动态调整线程数量。
- 微服务架构:在微服务之间相互调用时,根据服务调用量的变化动态调整线程池大小。
- 实时数据分析:处理实时数据流时,根据数据流的密度动态调整处理能力。
为什么需要动态调整线程池的大小?
- 资源利用率最大化:在负载较低时减少线程数量,避免资源浪费;在负载较高时增加线程数量,充分利用系统资源。
- 提高响应速度:通过增加线程数量来减少任务队列的等待时间,提高系统的响应速度。
- 适应负载变化:应对不可预测的工作负载变化,使系统能够在不同的负载条件下都能保持较高的性能。
- 增强系统稳定性:在系统面临突发流量时,通过增加线程数量来分散压力,减少系统崩溃的风险。
在实现动态线程池的过程中是否使用了设计模式?如果有,请举例说明。
本项目中通过Redis实现了观察者模式,所有没有用设计模式,但可以这样说
在实现动态线程池的过程中,可能会使用到以下几种设计模式:
- 观察者模式(Observer Pattern):用于监控系统的负载情况,当负载发生变化时,通知线程池调整线程数量。
- 示例:系统中有一个负载监控器,它可以观察系统负载的变化,并注册为线程池的观察者。当负载变化时,负载监控器会通知线程池调整线程数量。
- 工厂模式(Factory Pattern):用于创建线程池对象,可以支持多种不同的线程池配置和策略。
- 示例:可以定义一个
ThreadPoolFactory类,根据传入的不同参数(如线程数量、队列大小等)创建不同类型的线程池。
- 示例:可以定义一个
- 策略模式(Strategy Pattern):用于实现不同的线程池调整策略,可以根据实际需要更换不同的策略。
- 示例:可以定义一个接口
AdjustmentStrategy,不同的实现类分别代表不同的调整策略,如基于时间窗口的平均负载策略、基于任务队列长度的策略等。线程池可以根据需要选择不同的策略。
- 示例:可以定义一个接口
- 装饰器模式(Decorator Pattern):用于在不改变现有类结构的情况下,动态地给线程池添加新的功能。
- 示例:可以定义一个
DynamicThreadPoolDecorator类,它包裹现有的线程池对象,并在其基础上添加动态调整线程数量的功能。
- 示例:可以定义一个
项目实现
Redis 在该项目中是如何被使用的?它解决了什么问题?
- Redis作为消息队列,实现了主题的订阅发布,通过这个功能实现了线程池的配置修改。
- Redis保证了线程池的故障恢复。项目启动时,组件初始化服务类会去redis里读取线程池的配置,如果redis里没有就注册进去。
如何通过Redis进行订阅发布?
项目启动时发布一个主题,通过RTopic的addListener方法和publish方法实现主题的订阅和发布。
线程池的实时调整策略是如何实现的?
为了实现线程池的动态调整,我通过Redis的主题订阅功能实现的,也就是让Redis作为一个消息队列。
具体步骤如下:
启动服务时,读取yml文件中的配置消息,得到
RedissonClient的配置信息,构造一个RedissonClient对象;构造一个topicKey,也就是主题的键,通过
Redisson的getTopic方法的得到一个主题RTopic;通过
RTopic的addListener方法注册监听消息的类型和监听类,监听消息的类型就是线程池的配置参数类;1
2
3
4
5
6
7
public RTopic threadPoolConfigAdjustListener() {
String topicKey = key;
RTopic topic = redissonClient.getTopic(topicKey);
topic.addListener(ThreadPoolConfigEntity.class, threadPoolConfigAdjustListener);
return topic;
}在监听类里通过线程池的服务类去修改线程池。
组件服务类是如何拿到当前正在运行中的线程池的?
好的,这个组件首先需要其他引入。一个外部项目如果需要使用这个组件,需要使用组件提供的ThreadPoolConfigEntity对象,这个对象是我组件所提供的管理线程池的一个类,它可以创建好一个线程池,或者项目也可以自己创建线程池。
外部项目如果需要使用组件来管理线程池,则需要通过在项目启动时通过
@Bean注入线程池,组件通过Spring的依赖注入在项目启动时,获得通过一个Map对象获得所有通过
@Bean注入的所有线程池。构造一个键,将获取的线程池参数写入到Redis中,其中我将
ThreadPoolConfigEntity类作为每个本地线程池的配置类,这一步是因为从Redisson的Bucket中获取的数据类型时可以通过泛型来保障安全和提高规范化;最后,将线程池的Map集合作为参数设到服务类
DynamicThreadPoolService中去,这样的话,我通过控制层或其他触发器,传递修改参数请求,就可以去修改Redis查询当前线程池的情况。如果我去修改时,可以通过RTopic的publish方法发布ThreadPoolConfigEntity类型的消息,而由于我在组件中之前发布了监听主题,所以这个消息类型会触发对应的监听器,然后就会去运行监听器中的方法,通过组件的服务类去修改线程池的参数。因为组件服务类在服务启动时通过依赖注入已经拿到了外部项目的线程池,所以组件服务类就可以去修改本地的线程池了。最后,通过JS代码构建了一个简单的网页控制台,通过刷新查询实时获取线程池的数据,通过表单提交查看线程池参数和修改线程池。
动态线程池的原理
为什么线程池可以动态调整参数
因为 ThreadPoolExecutor 提供了调整线程数量和其他配置的能力。具体来说:
- 属性的可变性
corePoolSize 和 maximumPoolSize 属性都是 int 类型,并且它们是通过 volatile 关键字修饰的,这意味着它们可以在多线程环境中安全地读取和修改。
1 | protected volatile int corePoolSize; |
- 动态调整的方法
ThreadPoolExecutor 提供了以下方法来动态调整核心线程数和最大线程数:
- **setCorePoolSize(int corePoolSize)**:设置线程池的核心线程数。
- **setMaximumPoolSize(int maximumPoolSize)**:设置线程池的最大线程数。
这些方法直接修改了 corePoolSize 和 maximumPoolSize 的值。
- 动态调整的机制
当调用 setCorePoolSize 或 setMaximumPoolSize 方法时,线程池会根据新的配置来调整当前的工作线程数。具体来说:
- 增加核心线程数:如果新的
corePoolSize大于当前活动线程数,并且队列中有待执行的任务,线程池会尝试创建新的线程来处理这些任务。 - 减少核心线程数:如果新的
corePoolSize小于当前活动线程数,多余的线程将在空闲一段时间后被终止。 - 调整最大线程数:当
maximumPoolSize改变时,线程池会根据新的最大值来调整线程的数量。如果当前线程数超过了新的maximumPoolSize,多余的线程会被逐步终止。
在线程池的动态调整过程中,你是如何保证线程安全的?
使用 volatile 修饰符
corePoolSize 和 maximumPoolSize 在 ThreadPoolExecutor 类中是用 volatile 修饰的,这确保了多线程环境下的可见性和有序性。
1 | protected volatile int corePoolSize; |
volatile 修饰符保证了当这些字段被修改时,其他线程能够看到最新的值,而且不会发生指令重排序。
使用原子操作
ThreadPoolExecutor 使用了 ctl 字段来保存线程池的一些关键状态信息,包括当前活跃线程数、线程池的状态等。这个字段是一个 long 类型,通过位操作来保存不同的状态信息。在修改线程池状态时,ThreadPoolExecutor 使用了 CAS(Compare and Swap)操作来保证原子性。
1 | private volatile long ctl; |
例如,在创建新线程时,addWorker 方法会使用 compareAndSetWorkerCount 来更新线程池的当前线程数,这个操作是原子的。
java深色版本
1 | protected boolean compareAndSetWorkerCount(int expect, int update) { |
使用锁
在一些需要更复杂同步的地方,ThreadPoolExecutor 使用了锁来保护共享资源的访问。例如,在 interruptIdleWorkers 方法中,当需要中断空闲线程时,会获取 mainLock 来保护对 workers 集合的操作。
1 | private void interruptIdleWorkers(boolean onlyOne) { |
使用并发集合
ThreadPoolExecutor 使用了 ConcurrentHashMap 来管理 Worker 对象,这些对象代表了正在工作的线程。通过使用并发集合,ThreadPoolExecutor 可以在多线程环境下安全地管理这些线程。
1 | private final HashMap<Integer, Worker> workers = new HashMap<>(); |
底层原理:核心线程数的动态修改原理
1 | public void setCorePoolSize(int corePoolSize) { |
底层原理:最大线程数的动态修改原理
1 | public void setMaximumPoolSize(int maximumPoolSize) { |
底层原理:线程池状态ctl
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
workerCountOf 方法
workerCountOf 方法是从 ctl 字段中提取当前活动线程的数量。ctl 字段是一个 volatile long 类型的变量,包含了线程池的一些状态信息,包括当前活动线程的数量。
ctl 的高几位表示线程池的状态信息,而低几位表示当前活动线程的数量。具体来说,ctl 的低 3 位(0-2)表示当前活动线程的数量。
interruptIdleWorkers 方法
interruptIdleWorkers 方法用来中断那些处于空闲状态的线程。该方法遍历所有工作线程,并中断那些处于空闲状态的线程。如果当前活动线程数仍然大于新的最大线程数,则会再次检查并中断空闲线程。
JMX
线程池的监控指标体系是如何设计的?如何确保这些指标的准确性和及时性?
你是如何使用 JMX 进行线程池监控的?具体有哪些指标?
我希望通过获取系统当前的运行情况来判断,是否需要修改线程池。
所以我通过查询资料知道可以通过JMX这个技术,JMX是com.sun.management中的一个包,我通过OperatingSystemMXBean的工厂模式得到ManagementFactory对象,通过这个对象可以获得系统的内存信息、线程信息、类加载信息、垃圾回收信息、内存池信息等信息。
我利用CPU占用率、堆的使用情况,来调整线程池的核心线程数和最大线程数
线程池的动态扩展逻辑是如何实现的?
监控功能的实现我是这样做的:
使用一个 SystemMonitor 类实现 Runnable 接口重写run方法,让它在死循环里每个10秒获取一次系统运行信息,如果出现例如CPU飙高或堆占用过高,则实施线程池调整策略,把核心线程数和最大线程数调高;反之,如果系统资源占用较低,则调低线程池的配置
在开发过程中,是否进行了性能测试?如何模拟真实场景进行测试?
我通过一个Runnable的实现类模拟了一个线程的任务执行流程,然后在Applicaion启动类中通过applicationRunner方法返回参数args,在Application类启动时执行这个方法中的死循环来模拟不停地提交任务。
1 |
|
其中,主线程是在死循环中不停地去向线程池提交任务,还有一个子线程我是将其设置为了守护线程去检测系统状态。过程中,子线程通过JMX可以实时地获取的系统信息,并通过系统的信息来动态调整线程池的配置。
如何设计日志记录机制,确保在出现问题时能够快速定位原因?
这不是本项目应该去做的,但是如果问到了可以这样回答
1. 日志格式
统一的日志格式有助于快速解析和分析日志:
- 时间戳:记录日志产生的精确时间。
- 日志级别:明确指出该条日志的重要性。
- 线程 ID:帮助追踪特定线程的行为。
- 消息:描述发生了什么,以及任何必要的上下文信息。
- 异常堆栈跟踪:如果有的话,记录完整的异常堆栈跟踪信息。
示例日志格式:
1 | 2024-09-21 17:30:00 [INFO] [Thread-1] - Request received for /api/v1/users |
2. 日志聚合与索引
使用日志聚合工具(如 ELK Stack、Graylog、Splunk 等)来集中管理所有日志信息,并建立索引以便快速搜索:
- 集中存储:所有日志信息存储在一个地方,便于统一管理。
- 全文搜索:支持全文搜索功能,帮助快速找到相关信息。
- 图表展示:提供图表展示功能,可以直观地了解日志趋势。
3. 日志分析
利用日志分析工具(如 Kibana、Grafana 等)进行日志分析,发现潜在的问题:
- 趋势分析:查看日志随时间的趋势变化。
- 异常检测:自动检测异常行为,并产生告警。
- 性能分析:分析性能瓶颈,找出影响系统性能的因素。
如何设计监控系统,确保线程池的健康状况能够实时监控并及时告警?
1. 收集监控数据
首先,需要确定要收集哪些监控数据。对于线程池来说,以下是一些关键的监控指标:
- **活动线程数 (activeCount)**:当前正在执行任务的线程数量。
- **线程池大小 (poolSize)**:当前线程池中的线程总数。
- **队列长度 (queueLength)**:等待处理的任务队列长度。
- **任务完成数 (completedTaskCount)**:已完成的任务数量。
- 拒绝策略执行次数:当任务被拒绝时的次数。
- **线程存活时间 (keepAliveTime)**:非核心线程在空闲状态下存活的时间。
- **线程池状态 (threadPoolState)**:线程池的当前状态(如运行中、关闭中等)。
2. 选择监控工具和技术
Java Management Extensions (JMX)
- MBeans:使用
ThreadPoolExecutor的 MBeans 来暴露上述监控指标。 - JMX 客户端:可以使用 JConsole 或 VisualVM 这样的工具来查看这些指标。
日志记录
- 日志级别:通过设置不同的日志级别(如 INFO、WARN、ERROR),记录线程池的关键事件。
- 日志框架:使用如 Logback、Log4j 等日志框架来记录线程池的日志。
应用性能监控 (APM)
- APM 工具:如 New Relic、Datadog、Prometheus 等,可以用来监控应用程序的整体性能,包括线程池的运行状况。
3. 设置告警规则
根据业务需求和系统容量,设置合理的阈值来触发告警。例如:
- 当活动线程数超过某个阈值时。
- 当任务队列长度超过一定长度时。
- 当线程池拒绝任务的频率上升时。
4. 实现告警逻辑
告警发送
- 邮件/短信通知:当达到预设的阈值时,通过邮件或短信的方式通知相关人员。
- Webhook:可以设置 Webhook 与第三方服务(如 PagerDuty、Opsgenie)集成,自动触发告警流程。
自动化响应
- 自动化脚本:编写自动化脚本来响应告警,例如自动扩容、重启服务等。
- CI/CD 流水线:集成到 CI/CD 流水线中,当检测到问题时自动触发修复流程。
5. 可视化仪表板
使用可视化工具(如 Grafana、Kibana)来展示监控数据,帮助运维人员更容易地理解系统的运行状态。
6. 定期审核与优化
定期审查监控数据,根据实际运行情况调整监控阈值和告警策略,持续优化监控系统。
如果系统需要重启,线程池的状态如何保存和恢复?
用redis来保证。项目启动时,组件会去redis里读取线程池的配置,如果redis里没有就注册进去
性能优化
如果系统负载变化很大,动态线程池组件需要做哪些改进来保证可扩展性?
这不是本项目应该去做的,但是如果问到了可以这样回答
异步和非阻塞处理
异步处理:引入异步处理机制,将一些耗时较长的任务放入异步执行,从而减少主线程的等待时间,提高整体处理能力。
非阻塞 I/O:使用 NIO 或 AIO 等非阻塞 I/O 技术,减少 I/O 操作带来的阻塞时间,使得每个线程能够处理更多的请求。
弹性伸缩
- 云服务集成:利用云平台提供的弹性伸缩服务(如 AWS Auto Scaling、Kubernetes Horizontal Pod Autoscaler),根据实际需求动态增减计算资源。
缓存机制
- 缓存策略:合理使用缓存来减轻后端数据库的压力,减少重复计算,加快响应速度。
测试与验证
负载测试:定期进行负载测试,验证线程池的调整策略是否有效,并根据测试结果调整策略。
A/B 测试:在生产环境中使用 A/B 测试来评估新策略的效果,确保新的调整不会带来负面影响。
通过上述改进措施,动态线程池组件可以在面对大范围的负载变化时,保持良好的可扩展性和稳定性。
在极端情况下,当系统压力过大导致线程池无法正常工作时,你将如何快速诊断并解决问题?
如果在生产环境中突然出现大量的请求导致线程池崩溃,你会如何快速定位问题并恢复服务?
1. 快速响应与初步诊断
检查告警系统,确认问题:查看是否有相关的告警信息,如 CPU 使用率过高、内存溢出、线程池拒绝策略被触发等。
查看应用日志:查找最近的日志条目,特别关注错误级别和警告级别的日志,寻找异常信息。
查看系统日志:查看操作系统日志,了解是否有系统层面的问题,如磁盘空间不足、网络故障等。
2. 分析问题根源
检查线程池配置:确认线程池的最大线程数、核心线程数、队列大小等配置是否合理。
业务高峰期:如果是由于业务高峰期导致的,分析是否可以提前准备资源,如增加服务器或扩展线程池大小。
异常请求:检查是否有异常请求导致了大量的任务积压,如有必要,可以临时禁用或限流这些请求。
性能瓶颈:分析是否存在性能瓶颈,如数据库查询慢、外部服务响应慢等问题。
资源限制:检查是否存在资源限制,如 JVM 的内存设置不合理导致 OOM。
3. 采取紧急措施
横向扩展:增加更多的服务器或实例来分担负载。
纵向扩展:增加单个服务器的资源,如内存、CPU 等。
增加线程数:根据监控数据和系统资源情况,适当增加线程池的最大线程数。
调整队列大小:根据业务需求调整队列的大小,确保既能处理大量请求又不至于消耗过多资源。
客户端限流:在客户端实施限流措施,减少请求频率。
服务端限流:在服务端实现限流逻辑,如使用令牌桶算法或漏桶算法。
4. 长期解决方案
优化性能:针对性能瓶颈进行代码优化,如减少不必要的数据库查询、优化数据结构等。
异常处理:加强异常处理逻辑,避免异常导致的资源泄露或无限循环等问题。
自动化监控:建立更完善的监控体系,自动监控系统各项指标。
告警策略:完善告警策略,确保在出现问题时能够及时通知相关人员。
定期审查:定期审查系统配置和性能指标,确保系统处于最佳状态。
负载测试:定期进行负载测试,模拟高峰时期的流量,验证系统的稳定性和可扩展性。
线程池组件是否有容错机制?如何在出现故障时保证服务的连续性和数据一致性?
1. 容错机制
拒绝策略:在线程池满员时决定如何处理新的任务请求。
重试机制:对于一些可以重试的任务,可以在任务执行失败时进行重试。
超时处理:当任务执行时间超过预设的超时时长,可以采取相应的措施,如终止任务、记录日志或抛出异常。
2. 服务连续性
水平扩展:增加更多的实例来分散请求,减轻单个实例的负载压力
异步处理:采用异步处理一些耗时较长的任务,将其放入MQ中处理。
3. 数据一致性
事务管理:使用事务管理来保证数据的一致性。要么全部成功,要么全部回滚。
数据库连接池:使用DB连接池来管理数据库连接。
分布式事务:对于跨服务的操作,可以使用分布式事务(如两阶段提交、三阶段提交)来保证数据一致性。
消息队列保证:使用 RabbitMQ 的持久化消息、确认机制等来保证消息不丢失。
在高并发场景下,如何实现负载均衡来优化资源使用?
考察的是对负载均衡算法的理解
优化负载均衡算法
负载均衡器可以根据不同的算法来分配请求到后端服务器:
- **轮询 (Round Robin)**:按顺序将请求分发给后端服务器。
- **最少连接 (Least Connections)**:将请求分发给当前连接数最少的服务器。
- **IP 哈希 (IP Hash)**:根据客户端 IP 地址哈希值来分发请求,使得来自同一个客户端的请求尽量分配到同一台服务器。
- **URL 哈希 (URL Hash)**:根据请求 URL 的哈希值来分发请求。
- **加权轮询 (Weighted Round Robin)**:根据服务器的能力赋予不同的权重,权重高的服务器获得更多的请求。
异步处理
- 异步任务处理:对于耗时较长的任务,可以使用消息队列(如 RabbitMQ、Kafka)来异步处理,减轻主服务器的压力。
数据库读写分离
- 读写分离:将数据库的读操作和写操作分离,使用不同的数据库实例来处理,提高数据库的并发处理能力。
缓存策略
- 本地缓存:使用本地缓存(如 Ehcache、Caffeine)来减少对后端数据库的访问。
- 分布式缓存:使用分布式缓存系统(如 Redis、Memcached)来存储热点数据,减轻后端服务器的负载。
—————————————
项目经历:基于Java实现的关系型数据库
项目介绍
多线程模型
在 mbdb 项目中,我使用了 Java BIO 多线程模型进行网络通信。具体实现如下:
- 服务端使用
ServerSocket监听指定端口,等待客户端连接请求。 - 当有新的客户端连接请求到达时,服务端创建一个新的线程来处理该连接。
- 每个处理线程使用
Socket对象与客户端进行通信,读取客户端发送的数据并处理。 - 为了优化性能,我使用了线程池来管理这些处理线程,避免频繁创建和销毁线程带来的开销。
- 处理完成后,线程将结果通过输出流返回给客户端,然后销毁。
这种一请求一线程的模型虽然简单,但在高并发情况下可能会遇到性能瓶颈,因为每个客户端连接都需要一个独立的线程。在未来的版本中,我计划使用 NIO 或 AIO 模型来提高并发性能。
预写日志
预写日志的实现是通过在执行任何数据修改操作之前,先将操作记录到日志文件中。具体实现如下:
- 使用
FileOutputStream打开日志文件,以追加模式写入。 - 在执行插入或更新操作时,先将操作序列化并写入日志。
- 只有在日志写入成功后,才执行实际的数据库操作。
- 在系统启动时,先读取日志文件中的所有操作,重放到数据库中,以确保数据一致性。
这种预写日志的机制确保了即使在系统崩溃时,也可以通过重放日志来恢复到最后一致的状态。
SQL 解析
在 mbdb 中,我实现了一个简单的 SQL 解析器,主要使用了正则表达式来识别基本的 SQL 语句结构。具体实现如下:
- 定义几个正则表达式来匹配
SELECT、INSERT和UPDATE语句。 - 使用正则表达式将 SQL 语句拆分为关键字、表名和字段名。
- 将这些信息存储在一个数据结构中,以便后续处理。
- 根据解析结果,调用相应的数据库操作方法来执行 SQL 语句。
虽然这个 SQL 解析器功能相对简单,但已经能够处理基本的查询和数据操作。在未来的版本中,我计划扩展它的功能,支持更复杂的 SQL 语句。
事务管理
在事务管理方面,mbdb 实现了两阶段锁协议和 MVCC。具体实现如下:
- 在事务开始时,获取所有需要的锁。
- 在事务结束时,释放所有获取的锁。
- 使用
ConcurrentHashMap存储每个数据项的版本信息。 - 在读操作时,根据事务开始时间获取最新版本的数据。
- 在写操作时,创建一个新的数据版本,并更新版本号。
这种机制确保了事务的可串行化,并消除了读写操作之间的阻塞。mbdb 提供了两种事务隔离级别:读提交和可重复读。
索引结构
mbdb 使用 B+ 树作为索引结构,提供了创建聚簇索引的功能。具体实现如下:
- 每个索引节点包含多个键值对和指向子节点的指针。
- 在插入和删除操作时,根据 B+ 树的特性进行节点的分裂和合并,以保持树的平衡。
- 使用递归算法遍历树,查找、插入和删除索引项。
- 在表创建时,用户可以指定一个或多个字段作为聚簇索引。
- 在查询时,优先使用索引来加速数据检索。
B+ 树索引的优点在于它能够保持数据的有序性,并且在查找和插入时性能较高。总之,mbdb 在设计和实现时充分利用了 Java 的多线程特性、文件 I/O 以及数据结构等技术,以提供一个可靠、高效的关系型数据库管理系统。虽然目前功能还比较简单,但已经展示了一个基本的数据库系统的架构和实现。
底层模块关系展示
从这个依赖图中,拓扑排序一下就能看出实现顺序。本教程的实现顺序是 TM -> DM -> VM -> IM -> TBM
每个模块的职责如下:
- TM 通过维护 XID 文件来维护事务的状态,并提供接口供其他模块来查询某个事务的状态。
- DM 直接管理数据库 DB 文件和日志文件。DM 的主要职责有:1) 分页管理 DB 文件,并进行缓存;2) 管理日志文件,保证在发生错误时可以根据日志进行恢复;3) 抽象 DB 文件为 DataItem 供上层模块使用,并提供缓存。
- VM 基于两段锁协议实现了调度序列的可串行化,并实现了 MVCC 以消除读写阻塞。同时实现了两种隔离级别。
- IM 实现了基于 B+ 树的索引,BTW,目前 where 只支持已索引字段。
- TBM 实现了对字段和表的管理。同时,解析 SQL 语句,并根据语句操作表。

网络通信的设计
连接器
- 首先启动数据库服务端,服务端会监听本地的某个端口,我们通过客户端与服务端建立连接。
- 我没有设置账号和密码,所以会直接进入命令界面,socket会创建一个线程池,在死循环中等待我们输入命令。
- 一旦我们输入命令,服务端会创建一个worker页就是线程任务,丢给线程池去执行。
客户端设计
- 首先,通过启动类
ClientLancher类new一个Socket类发起连接 - 然后,new一个
Packager类建立传输层,同时绑定Transporter类、Encoder类这些消息传递类 - 最后,通过一个命令输入输出类
Shell类来接收命令、打印结果。
服务端设计
- 使用Maven来执行启动类
ServerLancher类,ServerLancher类中定义了服务端口、数据缓存大小 - 通过apache包中的
CommandLineParser接收命令行,让ServerLancher类执行两件事:创建数据库、打开数据库- 如果是创建数据库,则会new一个事务管理器、数据管理器、版本管理器去指定的路径下创建一个数据库,创建的文件有:
.db数据库文件、.log日志文件、.xid事务文件,创建完毕后结束服务; - 如果是打开数据库,则会new一个事务管理器、数据管理器、版本管理器,还会再启动一个
Server类去连接数据库。
- 如果是创建数据库,则会new一个事务管理器、数据管理器、版本管理器去指定的路径下创建一个数据库,创建的文件有:
- 然后,数据库会往数据库启动文件
Booter类获得数据库的路径,通过这一步知道你要操作的数据库在哪里;- 如果命令是创建数据库,则
Booter类会完成创建,它会往数据库启动文件中写入空数据,完成数据库的创建; - 如果命令是打开数据库,会启动
Server类监听ServerLancher类中定义的端口。Server类会通过ServerSocket监听端口当Socket中有事件时就会启动一个创建一个线程任务,接收socket的消息,这个socket消息本质上就是我们在命令行输入的数据库操作命令,而这个命令是由客户端通过消息传递类Transporter类写入到BufferedWriter中的,只不过这个消息现在通过Socket socket = ss.accept();接收到了;
- 如果命令是创建数据库,则
- socket接收到消息后会通过线程的
Runnable类创建worker线程,也就是一个线程任务,这个线程任务中,将这个线程任务交给线程池去执行,至此服务端网络通信层的任务就完成了。
Java BIO在项目中的使用场景是什么?相比NIO和AIO有什么不足?
在项目中,我使用Java BIO来实现客户端和服务端的网络通信。BIO(Blocking I/O)模式下,服务器端每接收到一个客户端连接请求,都会创建一个新的线程来处理该连接。在这个线程中,I/O操作是阻塞的,意味着如果没有数据可读或可写,线程会一直等待。
不足:
- 性能问题: 在高并发情况下,每个客户端连接都需要一个独立的线程处理,这种模式会消耗大量的系统资源,且容易导致线程数量过多,增加了系统的上下文切换成本。
- 可扩展性差: BIO模式不适合高并发场景,随着客户端数量的增加,服务器的性能会显著下降。
相比之下,NIO(Non-blocking I/O)和AIO(Asynchronous I/O)能够更好地处理高并发连接,NIO通过使用单个线程处理多个连接,而AIO则进一步提升了I/O操作的异步性和并发性能。
SQL解析和语法树构建
解析器
如果缓存没有命中,数据库会进入解析器做两件事:词法分析、语法分析。
词法分析会通过字符串分割和比较识别出关键字,例如:select、from、where等等。
之后语法分析会根据我定义的语法类对象(Select类、From类、Where类……)构建一个语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等。如果输入的sql语句语法不对,就会在这一阶段报错。
1
2
3
4
5
6// 例:select语法树
public class Select {
public String tableName;
public String[] fields;
public Where where;
}
缓存页
数据库会解析出 SQL 语句的第一个字段,看看是什么类型的语句,然后进入缓存里查找缓存数据。
查询缓存是以键值对的形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。如果命中就直接返回,反之继续往下走。
缓存的存储结构的设计:
1
2
3
4private HashMap<Long, T> cache; // 实际缓存的数据
private HashMap<Long, Integer> references; // 资源的引用个数
private HashMap<Long, Boolean> getting; // 正在被获取的资源
//维护了三个Map,查询时去cache里查,如果cache里有就返回,如果没有cache就去数据源里查,去查时往getting里放入数据对象,数据查出来后将数据放入cache中,将getting中的对象删掉,并将references计数+1,缓存的设计:2. 引用计数缓存框架和共享内存数组
不使用LRU算法(因为资源驱逐不可控,上层模块无法感知),而是采用引用计数缓存框架,上层资源手动释放对资源的引用,确保资源的安全
缓存的基本结构的设计:
TODO
执行器、优化器
- 每条语句会经历三个阶段:
- prepare 阶段,预处理阶段。检测表和字段是否存在,将 * 扩展为表上的所有列
- optimize 阶段,优化阶段。会生成一个执行方案,即去查那张表、用什么索引(目前只实现了聚集索引,所以如果走非聚集索引的话,会全表扫描)
- execute 阶段,执行阶段。根据执行计划执行语句,去操作数据文件、索引文件,最后将结果按照字符串的方式返回给客户端;
你是如何设计和实现简单的SQL解析器的?在解析过程中遇到的主要挑战是什么?
为了实现简单的SQL解析器,我首先定义了一个简单的SQL语法规则,并为每种SQL语句类型(如SELECT、INSERT、UPDATE、DELETE)设计了相应的解析方法。解析器通过词法分析(将SQL语句分解为标记)和语法分析(根据语法规则将标记组装为语法树)来理解和处理SQL语句。
主要挑战:
- 复杂的SQL语法: 即使是简单的SQL语法,也可能包含嵌套查询、别名、函数等复杂的元素,这些都会增加解析器的复杂性。
- 错误处理: 在解析过程中如何识别并报告语法错误是一个难点,必须设计一个健壮的错误处理机制,以便用户能够及时发现并纠正SQL语句中的错误。
记录的设计
数据库中记录的单位是由接口DataItem和实现类DataItemImpl来实现的。DataItemImpl实现了对记录的操作。
一行记录的结构如下:
[ValidFlag] [DataSize] [Data]
ValidFlag 1个字节,标识DataItem是否有效
DataSize 2个字节,标识Data部分的长度
Data 3个字节,数据
在实现数据持久化时,如何保证数据的一致性和持久性?
你是如何设计数据库的数据结构和索引结构的?
记录的结构如上所示。
索引的结构分为叶子结点和非叶子结点:
非叶子节点类
InternalNode:1
private List<AbstractTreeNode<K, V>> childrenNodes; // 孩子节点
叶子节点类
LeafNode1
2
3private List<K> keys; // 叶子节点中的键,即主键索引值
private List<V> values; // 叶子节点中的值,即整行数据
private LeafNode<K, V> next; // 下一个叶子节点的指针
B+树索引是如何实现的?请详细描述一下创建索引的过程。
定义索引列:选择一个或多个适合创建索引的列。这些列通常是那些经常出现在
WHERE子句中的列,或者是JOIN操作中用到的列。创建索引命令:在SQL中,可以通过
CREATE INDEX语句来创建索引。例如:1
2CREATE INDEX idx_age ON student (age);
CREATE INDEX [idx_column_name] ON [table_name] ([column_name]);这里
idx_column_name是索引的名字,table_name是要应用索引的表名,column_name是被索引的列名。数据库管理系统构建索引:当执行完
CREATE INDEX命令后,数据库管理系统会在后台开始构建索引。这个过程包括:- 遍历表中的每一行。
- 对于每行,提取出索引列的值。
- 按照B+树的方式插入这些键值对。如果树已满,则需要分裂节点以容纳新的键值对。
维护索引:一旦索引创建完成,每当表中的数据发生变化时(如INSERT、UPDATE、DELETE操作),数据库管理系统会自动更新索引,确保其与表数据保持一致。
优化查询:当执行查询时,数据库管理系统会检查是否有可用的索引来加速查询处理。如果有合适的索引,它将使用索引来减少需要扫描的数据量。
在实现B+树索引时,你是如何处理索引的插入、删除和更新操作的?B+树相比其他树形结构有哪些优势?
在B+树索引中,插入、删除和更新操作都涉及到节点的分裂、合并和重新平衡:
- 插入: 如果插入的节点超过了B+树的最大容量,则会发生节点分裂,父节点可能会接收到新的中间节点。如果父节点也达到容量上限,则继续向上分裂,直到根节点。
- 删除: 删除操作时,如果节点下的元素少于最小容量,则可能需要将其与相邻的兄弟节点合并,或从相邻节点借一个元素以维持B+树的平衡。
- 更新: 更新操作类似于删除和插入,更新某个键值后,如果新键值改变了索引的顺序,可能会涉及节点的重组。
B+树的优势:
- 节点分裂减少: B+树的内部节点仅存储索引值,不存储实际数据,因此树的分裂和合并操作比B树更少。
- 范围查询高效: B+树的所有叶子节点通过指针相连,范围查询时可以顺序扫描叶子节点,而不需要回溯。
- 磁盘I/O友好: B+树的结构非常适合磁盘存储,因为它的节点大小可以与磁盘页大小匹配,减少磁盘I/O操作。
数据的持久化是如何实现的?具体采用了哪些技术?
采用了许多技术,例如:事务管理、日志记录、检查点、缓冲池、恢复机制
记录的操作通过加锁实现了原子性。此外还通过redo log和undo log保证。
检查点(Checkpoint)机制用于定期将内存中的脏页(即已经被修改但还未写入磁盘的数据页)强制刷盘,并记录检查点的位置。检查点有助于减少在系统恢复期间需要处理的日志量。
此外,还有缓冲池(Buffer Pool)机制。缓冲池是数据库系统中用于缓存数据页的一个内存区域。当数据页被修改时,它们会被缓冲池管理器标记为“脏页”,并由缓冲池管理器决定何时将脏页写回到磁盘。
日志的设计(可靠性设计)
日志和恢复机制
WAL(Write-Ahead Logging):在数据修改之前先写入日志,确保在系统故障时可以通过日志恢复数据。在进行插入、更新等数据库操作之前,系统会先将这些操作记录到日志中,这些日志通常存储在一个持久化的介质中,比如磁盘。当数据库发生崩溃或其他故障时,可以通过回放这些日志来恢复未完成的事务,确保数据的一致性和完整性。
具体来说,当事务开始时,系统会为该事务创建一个日志记录,记录下事务的操作内容。当事务提交时,日志记录会被标记为已完成。如果系统在操作过程中崩溃,数据库可以通过扫描日志文件,回滚未完成的事务或重做已完成但未提交的事务,从而恢复到故障前的一致状态。
数据库日志文件(唯一)标准格式为:
1 | [XChecksum] [Log1] [Log2] ... [LogN] [BadTail] |
XChecksum 是后续所有日志计算的校验和,用于校验后续所有日志是否损坏
XChecksum 用于计算后续所有日志的Checksum,校验日志文件是否损坏
Log1 ~ LogN 是常规的日志数据
BadTail 是在数据库崩溃时,没有来得及写完的日志数据,BadTail 不一定存在
一条日志(大量)的格式为:
1 | [Size] [Checksum] [Data] |
Size:标识Data长度
Checksum:校验当前日志文件是否损坏
Data:日志数据
日志文件操作:
1 | // 向日志文件写入日志 |
事务操作日志:
1 | // 插入一条日志 |
如何设计监控和日志记录系统来帮助诊断和调试?
TODO
重启故障恢复策略(Recover类)
- 根据最大页号截断文件,丢弃损坏数据;
- 读取日志文件的最大页号,根据最大页号截断文件,丢弃损坏数据
- 执行重做操作,回滚已完成的事务;
- 判断日志中的事务类型是插入还是更新:
- 如果是插入的操作,则读取事务id、数据页编号、数据页偏移量、字节流;
- 如果是更新的操作,则读取事务id、数据页编号、数据页偏移量、修改前的的字节流、修改后的字节流。
- 如果事务的状态是“已提交”或“已回滚”,则重做。
- 重做的具体操作:
- 如果是插入的数据,则通过数据管理器,将字节流设为修改后的字节流,然后将到字节流写入到偏移量后面。
- 如果是更新的数据,则通过数据管理器,将字节流设为修改后的字节流,然后将到字节流写入到偏移量后面。
- 判断日志中的事务类型是插入还是更新:
- 执行撤销操作,撤销未完成的事务;
- 判断日志中的事务类型是插入还是更新:
- 如果是插入的操作,则读取事务id、数据页编号、数据页偏移量、字节流;
- 如果是更新的操作,则读取事务id、数据页编号、数据页偏移量、修改前的的字节流、修改后的字节流。
- 如果事务的状态是“活跃”,则回滚。
- 回滚的具体操作:
- 如果是插入的数据,则通过数据管理器,将偏移量后面的字节流数据标记为invalid;
- 如果是更新的数据,则通过数据管理器,将字节流设为修改前的字节流,然后将到字节流写入到偏移量的后面。
- 判断日志中的事务类型是插入还是更新:
数据库在故障重启后什么情况下会做重做日志?什么情况下会做回滚日志?
何时使用重做日志?
- 系统崩溃后的恢复:如果某个事务已经提交,但是它的修改还没有完全写入磁盘,那么在系统重启后会通过重做日志来重新执行这些事务的修改操作。
何时使用回滚日志?
- 事务回滚:当一个事务因为某种原因(如遇到错误、用户手动回滚等)需要回滚时,数据库管理系统会使用回滚日志来撤销该事务所做的修改,将数据库恢复到事务开始前的状态。
- 多版本并发控制(MVCC):在支持多版本并发控制的数据库系统(如MySQL的InnoDB存储引擎)中,回滚日志还可以用于实现读取一致性视图,允许多个事务同时读取同一份数据的不同版本。
重做日志的例子
假设事务 T1 修改了某一行数据,然后提交。如果在 T1 提交之后但其数据还未完全写入磁盘之前系统崩溃,那么在重启后,数据库管理系统会读取重做日志文件,找到 T1 的记录,并重新执行 T1 的修改操作,以确保事务 T1 的持久性。
回滚日志的例子
假设事务 T2 开始后修改了某一行数据,但在提交之前遇到了错误需要回滚。这时,数据库管理系统会读取回滚日志文件,找到 T2 修改前的数据状态,并将数据恢复到修改前的状态。
如何设计数据恢复机制,确保数据在意外中断后仍能正确恢复?
数据库是否有容错机制?如何在出现故障时保证服务的连续性和数据一致性?
TODO
事务的设计与处理
事务类,由版本控制器调用,每个事务对应一个Transaction对象
每个事务类的格式:
1 | // 事务的唯一xid |
事务控制器的设计:
1 | // 超级事务,xid为0的事务永远为commited状态 |
在事务处理中,你是如何实现事务的ACID特性的?
原子性(Atomicity):通过2PL和MVCC确保原子性,还通过redo log确保事务的修改可以被重做。
一致性(Consistency):在事务开始时检查事务是否满足一致性要求,即是否违反了数据库的完整性约束(如唯一性约束、外键约束等),并在整个事务执行过程中维持这些约束。
隔离性(Isolation):通过多种隔离级别MVCC来实现。
持久性(Durability):通过文件编程写入,如果在写入过程中系统发生崩溃,则通过使用redo log和checkpoint机制。
在实现事务支持时,如何处理事务的提交和回滚?
提交(Commit):当事务成功完成其所有操作并且决定提交时,需要将事务的更改永久地应用到数据库中。
- 实现方法:
- 将事务的状态从
FIELD_TRAN_ACTIVE修改为FIELD_TRAN_COMMITTED。 - 更新事务相关的数据结构(如版本链表、锁等)。
- 清理不再需要的旧版本。
- 如果使用了日志机制,确保所有相关的日志都已经持久化。
- 将事务的状态从
回滚(Rollback):当事务执行过程中发生错误或决定不提交时,需要撤销事务所做的所有更改,使数据库恢复到事务开始前的状态。
- 实现方法:
- 将事务的状态从
FIELD_TRAN_ACTIVE修改为FIELD_TRAN_ABORTED。 - 释放事务持有的所有锁。
- 如果使用了 MVCC,清理事务的快照。
- 如果使用了日志机制,确保所有相关的日志都被正确处理。
- 清理临时数据结构。
- 将事务的状态从
数据库故障重启,应该先做redo log还是先做undo log?
先处理重做日志(Redo Log),然后再处理回滚日志(Undo Log)。因为在故障恢复过程中,需要确保已经提交的事务的持久性(Durability),并且回滚未提交的事务。
如何避免 Undo Log 覆盖 Redo Log 的操作
- 区分已提交和未提交的事务:
- 在读取 Redo Log 记录时,会检查事务的状态。只有已提交的事务才会被重做。
- 在读取 Undo Log 记录时,会检查事务的状态。只有未提交的事务才会被回滚。
- 事务的版本控制:
- 使用MVCC机制,通过事务的版本号区分不同事务的操作。在 MVCC 中,每个数据项都有一个版本号,记录了创建该版本的事务 ID 和版本的有效时间范围。
- 在恢复过程中,通过版本号来确定哪些版本是有效的,哪些版本需要被回滚。
版本控制的实现与设计
在介绍 MVCC 之前,首先明确记录和版本的概念。
DM 层向上层提供了数据项(Data Item)的概念,VM 通过管理所有的数据项,向上层提供了记录(Entry)的概念。
上层模块通过 VM 操作数据的最小单位,就是记录。VM 则在其内部,为每个记录,维护了多个版本(Version)。每当上层模块对某个记录进行修改时,VM 就会为这个记录创建一个新的版本。
版本控制器的设计
隔离级别的实现方式是通过版本控制器创建版本,每个版本根据事务的隔离级别在事务的生命周期中创建。
VM向上层抽象出entry,entry结构:
1 | [XMIN]: XMIN 是创建该条记录(版本)的事务编号, |
读已提交
事务在读取数据时,只能读取已经提交事务产生的数据。如果一个记录的最新版本被另一个事务加锁,当另一个事务想要读取这条记录时,它将读取该记录的上一个已提交版本。最新的被加锁的版本,对于另一个事务来说,是不可见的。
为了避免这种情况,我们可以为每个版本维护了两个变量:
1 | XMIN:创建该版本的事务编号,在版本创建时填写 |
XMAX 这个变量解释了为什么 DM 层不提供删除操作,当想删除一个版本时,只需要设置 XMAX 就行了,这样的话这个版本对每一个 XMAX 之后的事务都是不可见的,也就等价于删除了。
可重复读
不可重复度,如果一个事务在两次读取同一数据项之间,另一个事务对该数据项进行了更新并提交,那么第一次读取和第二次读取可能会得到不同的结果。
为了避免这种情况,我们可以规定:事务只能读取它开始时, 就已经结束的那些事务产生的数据版本,即通过版本管理器,一个事务只能读取到与自己的xid一致的xmin的版本记录。
解释一下两阶段锁协议(2PL)和MVCC如何工作?
两阶段锁协议(2PL): 两阶段锁协议是保证事务可串行化的一种方法。它分为两个阶段:
- 加锁阶段: 事务开始执行时,需要的所有锁都必须在这个阶段获得。这个阶段允许事务获取新锁,但不能释放已获得的锁。
- 解锁阶段: 一旦事务释放了一把锁,就进入了解锁阶段,在此阶段不能再获得任何新的锁。
多版本并发控制(MVCC): MVCC允许数据库在处理读写操作时无需加锁。它通过维护数据的多个版本,实现了对同一数据的并发读写。具体来说,数据库为每个事务创建一个快照,事务只会看到在它开始时已经提交的事务的结果。这样可以避免读写操作的阻塞,提升系统的并发性。
为什么需要两阶段锁协议(2PL)和MVCC这两种机制?
- 2PL 确保了写操作的可串行化,避免了数据不一致。
- MVCC 提供了更高的并发性能,尤其是在读操作频繁的情况下。
如何实现多版本并发控制(MVCC)来保证并发事务的一致性?
在高并发场景下,如何确保数据的一致性和隔离性?
TODO
如何解决版本跳跃?
版本跳跃指的是一个事务看到的数据版本与另一个事务看到的数据版本不同,即使它们都是合法的版本。
版本跳跃产生的原因
版本跳跃可能发生在以下几种情况下:
- 事务开始时间不同:事务开始的时间不同,因此它们可能看到不同的版本。例如,事务T1在时间戳T开始,事务T2在时间戳T+1开始,它们可能看到不同版本的数据。
- 读取操作与数据版本不匹配:在某些情况下,事务的读取操作可能与当前的数据版本不匹配,导致读取到的数据版本不是最新的或者不是预期的版本。
- 并发控制策略不同:不同的MVCC实现可能有不同的并发控制策略,可能导致事务看到的数据版本不同。
解决版本跳跃的方法
解决版本跳跃的关键在于确保事务的一致性和隔离性。以下是一些常用的方法:
- 严格的时间戳分配:
- 确保每个事务有一个严格递增的时间戳或事务ID。这样可以确保每个事务看到的数据版本是一致的。
- 使用快照隔离(Snapshot Isolation, SI):
- 快照隔离是MVCC中最常用的一种隔离级别,它可以防止版本跳跃。每个事务在其开始时创建一个快照,该快照包含了事务开始时的数据版本。事务在其执行期间只能看到该快照中的数据版本,这样可以避免版本跳跃。
- 事务开始时创建快照:
- 在事务开始时创建一个快照,该快照包含了事务开始时所有可见的数据版本。事务在其执行期间只能看到该快照中的数据版本。
- 版本链管理:
- 对每个数据项维护一个版本链,确保版本链中的每个版本都按照时间顺序排列。这样可以确保事务读取时能够找到正确版本的数据。
- 版本有效性检查:
- 在读取数据版本时,检查版本的有效性,确保版本在事务的可见范围内。例如,事务T1只能看到在其开始时间之前提交的版本。
- 使用全局版本管理器:
- 可以引入一个全局版本管理器来统一管理所有事务的版本信息,确保版本的一致性。
MYDB的解决方案

死锁检测(hard)
- 构建等待图(Wait-for Graph):
- 使用一个图结构来表示事务之间的等待关系。每个事务节点(XID)和资源节点(UID)都是图中的顶点。
- 如果事务 Ti 正在等待事务 Tj 持有的资源,则在图中添加一条从 Ti 到 Tj 的边。
- 检测环路:
- 如果等待图中存在环路,则表明存在死锁。检测环路可以通过深度优先搜索(DFS)或其他图遍历算法来实现。
- 查找图中是否有环的算法也非常简单,就是一个深搜。思路:为每个节点设置一个访问戳,都初始化为 -1,随后遍历所有节点,以每个非 -1 的节点作为根进行深搜,并将深搜该连通图中遇到的所有节点都设置为同一个数字,不同的连通图数字不同。这样,如果在遍历某个图时,遇到了之前遍历过的节点,说明出现了环。
————————————-
实习的业务问题
问题1:实现用户端短信登陆,将用户Session数据转移到Redis存储,实现分布式会话
请简述你如何设计并实现用户短信登录的流程,包括验证码的生成、发送和验证。
短信登录流程设计:我们首先生成一个唯一的验证码,并将其存储到Redis中,设置一定的过期时间。然后将这个验证码通过短信服务发送到用户的手机上。用户在前端输入验证码并提交后,我们与Redis中存储的验证码进行比对,如果一致则验证成功,创建用户会话并登录。
你为什么选择将Session数据转移到Redis存储?这样做的好处和潜在问题是什么?
Redis作为内存数据库,读写速度快,适合存储临时数据。将Session数据转移到Redis中,可以实现跨服务器共享Session,从而支持分布式会话。潜在问题在于,如果Redis服务故障,可能导致用户会话丢失,因此需要考虑Redis的高可用性。
在实现分布式会话时,你如何处理Session的一致性和失效问题?
使用Redis的分布式锁机制确保Session数据的一致性。同时,为每个Session设置一个过期时间,当Session过期后自动失效,防止长时间占用资源。
问题3:采用Kafka监听消息队列,完成延时发布文章功能
请解释你如何利用Kafka实现延时发布文章的功能?具体使用了Kafka的哪些特性?
当文章创建时,我们将其封装为消息并发送到Kafka的延时队列中,设置相应的延时时间。Kafka会在指定的时间后将消息发送到相应的主题,我们的消费者监听这个主题并处理消息,完成文章的发布。
当Kafka中的消息处理失败时,你如何保证消息不丢失?
配置了Kafka的消息持久化,确保即使Kafka服务重启,消息也不会丢失。同时,消费者在处理消息时,会进行确认操作,只有确认后的消息才会从Kafka中删除。如果处理失败,消息会重新进入队列等待再次处理。
Kafka在高并发场景下可能会遇到哪些挑战?你如何优化Kafka的性能?
在高并发场景下,通过增加Kafka的分区数、调整消费者的并发数以及优化消息的序列化方式等手段来提高Kafka的性能。
问题6:完成服务订单管理功能,包括创建订单、取消订单、删除订单、历史订单等
请描述一下你如何设计服务订单管理系统的数据库模型?
订单管理系统设计了包括订单表、订单项表、用户表等在内的数据库模型。订单表存储订单的基本信息,如订单号、用户ID、创建时间等;订单项表存储订单的详细信息,如商品名称、数量、价格等。通过外键关联,我们实现了订单与订单项之间的关联关系。
在处理订单状态变更(如取消、删除)时,你是如何保证数据的一致性和完整性的?
在处理订单状态变更时,我们使用了数据库的事务管理来确保数据的一致性。例如,在取消订单时,我们需要同时更新订单状态和订单项的状态,这两个操作必须作为一个整体来完成,要么全部成功,要么全部失败。通过使用Spring框架的事务管理功能,我们可以方便地实现这一点。
对于历史订单数据的查询和展示,你采用了哪些优化策略?
对于历史订单的查询和展示,我们采用了分页和索引优化的策略。首先,我们为订单表的关键字段建立了索引,以提高查询效率。其次,我们使用了分页查询的方式,每次只加载部分订单数据到内存中,降低了内存消耗。同时,我们还提供了多种查询条件,方便用户根据订单状态、时间等条件进行筛选和排序。
问题7:使用Redis优化用户端的查询接口,定时缓存热点服务数据,搭配布隆过滤器防止缓存穿透
你如何确定哪些数据是热点服务数据?定时缓存的策略是怎样的?
通过分析用户请求日志和系统访问数据,确定了哪些数据是热点服务数据。这些数据通常具有访问频率高、变化不频繁的特点。
在使用Redis缓存数据时,你如何保证数据的一致性和实时性?
使用了Redis的缓存机制来存储这些热点数据。通过定时任务,我们定期从数据库中加载最新的热点数据到Redis中,并设置适当的过期时间。这样,当用户请求这些数据时,可以直接从Redis中获取,提高了查询速度。
请解释一下布隆过滤器在防止缓存穿透中的作用和实现原理。
布隆过滤器可以快速地判断一个元素是否存在于某个集合中,而不需要实际存储这个元素。在查询Redis之前,我们先通过布隆过滤器判断数据是否可能存在。如果布隆过滤器判断数据不存在,则直接返回空结果,避免了对Redis的无效查询。
问题8:在优惠券分发接口中,使用Redisson+Lua实现一人一单,解决超卖问题
能否详细解释一下你如何使用Redisson和Lua实现一人一单的优惠券分发逻辑的?
使用了Redisson的分布式锁和Lua脚本来实现一人一单的优惠券分发逻辑。首先,我们使用Redisson的分布式锁来确保同一时间只有一个线程能够处理优惠券的分发。然后,我们编写了一个Lua脚本,该脚本在Redis中原子地执行优惠券的扣减和分配操作。通过这两个机制的结合,我们确保了每个用户只能领取一张优惠券。
在高并发场景下,你的优惠券分发系统如何保证性能和稳定性?
通过水平扩展Redis集群、优化Lua脚本的性能以及调整Redisson的配置参数等手段来提高系统的性能和稳定性。同时,我们还建立了监控和报警机制,及时发现并处理可能出现的性能瓶颈或异常。
如果在优惠券分发过程中出现了超卖问题,你如何检测和修复这个问题?
如果出现了超卖问题,我们会首先通过日志和监控数据定位问题的原因。然后,我们会根据具体情况采取回滚优惠券、补偿用户等措施来修复问题,并总结经验教训,完善系统的容错和恢复能力。
实习的基础知识
问题1(短信登录与Redis存储Session):
请简述Session在Web应用中的作用,以及为什么我们需要将其转移到Redis中?
Session在Web应用中的作用:Session在Web应用中用于跟踪用户的会话状态,存储用户在网站上的活动信息,如登录状态、购物车内容等。通过Session,网站能够在用户的不同请求之间保持状态,提供个性化的服务。
为什么将Session转移到Redis中:将Session转移到Redis中可以实现Session的共享和持久化。传统的Session存储在单个服务器的内存中,当服务器宕机或扩展时,Session数据容易丢失或不可访问。而Redis作为内存数据库,具有高性能和可靠性,可以实现Session的分布式存储和快速访问,支持水平扩展和容错。
Redis的数据结构有哪些?并说明每种数据结构的适用场景。
字符串(String)、哈希(Hash)、列表(List)、集合(Set)和有序集合(Sorted Set)。每种数据结构都有其特定的应用场景。例如,字符串可用于简单的键值存储;哈希可用于存储结构化数据;列表可用于实现队列或栈等数据结构;集合可用于存储不重复的元素;有序集合则支持元素的排序和范围查询。
你如何理解分布式会话,以及实现它需要注意哪些关键点?
问题3(Kafka延时队列):
Kafka的核心概念有哪些?它们是如何协同工作的?
Kafka的核心概念:Kafka的核心概念包括Producer(生产者)、Broker(代理服务器)、Consumer(消费者)、Topic(主题)和Partition(分区)。Producer负责发送消息到Kafka;Broker负责存储和转发消息;Consumer从Kafka中消费消息;Topic是消息的类别;Partition是Topic的物理分区,用于实现消息的并行处理和存储。
请描述一下Kafka的延时队列是如何实现的,它适用于哪些场景?
Kafka延时队列的实现及适用场景:Kafka通过其延时消息功能实现延时队列。生产者可以设置消息的延时时间,使消息在指定的时间后才会被消费者消费。这适用于需要实现定时任务、订单超时处理、消息重试等场景。
在处理Kafka消息时,如何确保消息的可靠性和一致性?
确保消息的可靠性和一致性:为了确保消息的可靠性和一致性,Kafka采用了多种机制,如消息的持久化存储、消息的确认机制、消息的幂等性处理等。同时,可以通过设置消息的重复发送策略、消费者的容错处理等方式来进一步保障消息的可靠性。
问题6(服务订单管理):
在设计订单管理系统时,通常需要考虑哪些核心功能和模块?
订单管理系统的核心功能包括订单创建、订单查询、订单修改、订单取消和订单统计等。对应的模块可以包括用户模块、商品模块、支付模块、物流模块等,这些模块共同协作以实现订单的全流程管理。
如何确保订单数据的完整性和一致性?
可以通过数据库的事务管理、数据校验、日志记录等方式来实现。同时,在设计系统时,需要考虑到并发控制和数据一致性的问题,避免出现数据冲突或不一致的情况。
在处理大量订单数据时,你通常采取哪些优化措施来提高性能?
在处理大量订单数据时,可以采用分页查询、索引优化、缓存机制等方式来提高性能。此外,还可以考虑使用分布式数据库或大数据处理技术来扩展系统的处理能力,应对高并发的场景。
问题7(Redis优化与缓存策略):
请简述Redis在缓存场景中的优势以及常见使用方式。
优势主要体现在高性能、低延迟、支持多种数据结构以及丰富的操作命令上。它可以将热点数据存储在内存中,快速响应客户端的请求,减轻数据库的压力。
什么是缓存穿透、缓存雪崩和缓存击穿?如何预防和处理这些问题?
缓存穿透是指查询一个不存在的数据,由于缓存中也没有该数据,导致每次请求都要去数据库查询,造成数据库压力过大。可以通过布隆过滤器或缓存空对象等方式来预防。缓存雪崩是指大量缓存数据同时失效或过期,导致大量请求直接打到数据库上。可以通过设置缓存的过期时间分散一些、使用缓存预热和降级策略等方式来应对。缓存击穿是指热点数据缓存过期,此时大量并发请求会穿透缓存直接访问数据库。可以通过设置热点数据永不过期或使用互斥锁等方式来避免。
在设计缓存策略时,你通常如何权衡数据的实时性和缓存的命中率?
如果数据实时性要求较高,可以设置较短的缓存过期时间或采用实时更新的策略;
如果数据实时性要求不,可以设置较长的缓存过期时间或采用定时刷新的策略;
同时,可以通过监控和分析缓存的命中率和性能数据来优化缓存策略。
问题8(优惠券分发与防超卖策略):
在实现优惠券分发功能时,如何确保每个用户只能领取一次优惠券?
可以在数据库中为每个用户设置一个优惠券领取状态字段,并在用户领取优惠券时更新该字段。同时,可以使用Redis的分布式锁或数据库的事务来保证操作的原子性,避免重复领取。
请解释超卖现象是如何发生的,以及如何通过技术手段来避免它?
可以采用乐观锁或悲观锁来控制并发操作,确保同一时间只有一个线程能够修改库存数量。此外,还可以使用Redis的Lua脚本来原子地执行库存扣减和优惠券发放操作,避免超卖的发生。
在高并发场景下,你通常如何设计优惠券分发系统来保证其性能和稳定性?
可以通过水平扩展服务器、使用高性能的数据库和缓存系统、优化代码和算法等方式来提高系统的处理能力。同时,需要建立监控和报警机制,及时发现和处理可能出现的性能瓶颈或异常。
实习的面试问题
- ThreadLocal的用途和实现:
ThreadLocal主要用于保存线程私有数据,避免线程间的数据共享和竞争。它可以在多线程环境下为每个线程提供独立的变量副本,从而避免锁竞争带来的性能损耗。实现上,ThreadLocal内部使用了一个ThreadLocalMap来存储每个线程的变量副本。这个Map的键是线程对象,值是线程的变量副本。当线程访问ThreadLocal变量时,ThreadLocal会通过当前线程作为键从Map中获取对应的变量副本;如果Map中不存在该键,则创建一个新的变量副本并存储到Map中。 - MySQL索引的设置与优化:
MySQL索引的设置和优化是提高数据库查询性能的重要手段。在设置索引时,需要根据查询的条件和顺序选择合适的索引类型和列。例如,对于经常用于查询条件的列,可以创建单列索引或联合索引;对于需要覆盖查询结果的列,可以选择合适的覆盖索引。在优化索引时,可以通过分析查询语句、避免全表扫描、定期维护索引等方式来提高查询效率。 - Spring AOP原理:
Spring AOP的原理主要基于动态代理和切面编程。动态代理是指在运行时动态地为目标对象创建代理对象,从而在不修改目标对象代码的情况下增强其功能。切面编程则是将跨多个类的通用逻辑(如日志记录、事务管理等)封装成切面,并将其织入到目标对象的执行流程中。Spring AOP通过代理类和切面类来实现这一功能,代理类负责拦截目标对象的方法调用,并根据切面类中的定义执行相应的逻辑。 - Spring动态代理的应用场景:
Spring动态代理主要应用于需要为已有对象提供额外功能而又不修改其代码的场景。例如,我们可以在不修改业务逻辑代码的情况下为其添加日志记录、性能监控或事务管理等功能。通过Spring动态代理,我们可以灵活地扩展和增强已有对象的功能,提高代码的可维护性和可扩展性。 - MyBatis的一级缓存和二级缓存:
MyBatis的一级缓存是SqlSession级别的缓存,它默认开启并自动管理。一级缓存用于存储同一个SqlSession中执行的相同SQL语句的结果集。当再次执行相同的SQL语句时,MyBatis会先从一级缓存中查找结果,如果找到则直接返回缓存结果,避免了重复查询数据库。二级缓存是Mapper级别的缓存,它可以被多个SqlSession共享。二级缓存用于存储跨SqlSession的相同SQL语句的结果集。通过合理配置和使用一、二级缓存,可以有效地提高MyBatis的查询性能。 - MyBatis的执行过程:
MyBatis的执行过程大致如下:首先,MyBatis会根据配置文件和映射文件初始化SqlSessionFactory;然后,通过SqlSessionFactory创建SqlSession对象;接着,SqlSession根据Mapper接口或XML映射文件生成Mapper代理对象;当调用Mapper代理对象的方法时,MyBatis会根据方法名和参数生成SQL语句并执行;最后,MyBatis将执行结果映射成Java对象并返回给调用者。 - Redis缓存穿透:
Redis缓存穿透是指查询一个不存在的数据,由于缓存中也没有该数据,导致每次请求都要去数据库中查询,从而给数据库带来压力。解决这个问题的方法之一是使用布隆过滤器来过滤掉不存在的请求,或者在缓存中存储一个空对象或特殊标记来表示该数据不存在。 - 高频数据的存储:
高频数据的存储需要考虑数据的实时性、并发性和持久化需求。常见的存储方案包括使用内存数据库(如Redis)来存储实时数据,通过负载均衡和分片技术来提高并发性能,同时定期将数据持久化到磁盘或分布式存储系统中以保证数据的可靠性。 - Redis和数据库的一致性问题:
Redis和数据库的一致性问题主要发生在数据更新时。由于Redis是内存数据库,其数据更新速度通常比数据库快,因此可能导致Redis中的数据与数据库中的数据不一致。解决这个问题的方法之一是使用双写策略,即在更新数据库的同时也更新Redis;或者使用延时双删策略,即在删除数据库数据前先删除Redis中的数据,并在一定时间后再次删除Redis中的数据以防止脏读。此外,还可以使用分布式锁或事务来保证数据的一致性。 - Redis宕机数据丢失问题:
Redis宕机时,如果未采取持久化措施,内存中的数据将会丢失。为了解决这个问题,Redis提供了两种持久化方式:RDB(快照)和AOF(追加文件)。RDB通过定期将内存中的数据生成快照并保存到磁盘上来实现持久化,而AOF则通过记录每次写操作到日志文件中来实现数据的持久化。在实际应用中,可以根据业务需求选择适合的持久化方式,并配置合理的持久化策略,以确保数据的可靠性。 - JVM垃圾回收算法:
JVM中的垃圾回收算法主要包括标记-清除、标记-整理、复制和分代收集等。标记-清除算法通过标记出不再使用的对象并清除它们来回收内存空间;标记-整理算法在标记的基础上对存活对象进行整理,以便消除内存碎片;复制算法将可用内存划分为两个大小相等的区域,每次只使用其中一个区域,当该区域内存用完时,将存活对象复制到另一个区域并清空当前区域;分代收集算法则根据对象的生命周期将内存划分为不同的代,并针对不同的代采用不同的回收策略。 - OOM(OutOfMemoryError)问题的排查:
当JVM出现OOM错误时,通常是因为堆内存不足。排查OOM问题可以从以下几个方面入手:首先,检查堆内存设置是否合理,是否需要根据应用需求调整堆内存大小;其次,分析堆内存中的对象占用情况,找出占用内存较大的对象;然后,根据对象类型和来源分析是否存在内存泄漏或对象生命周期过长的问题;最后,优化代码和配置,减少不必要的对象创建和内存占用。 - JVM分区:
JVM的内存分区主要包括堆、栈、方法区、程序计数器和本地方法栈等。堆用于存储对象实例,是垃圾回收的主要区域;栈用于存储基本数据类型和对象引用,每个线程都有一个私有的栈;方法区用于存储已被虚拟机加载的类信息、常量、静态变量等;程序计数器用于记录当前线程执行的字节码位置;本地方法栈则为虚拟机执行本地方法提供服务。 - Linux命令杀死线程:
在Linux中,线程是进程的一部分,因此没有直接杀死线程的命令。要杀死一个线程,实际上是杀死包含该线程的整个进程。可以使用kill命令来发送信号给进程,从而终止它。例如,使用kill -9 <进程ID>可以发送SIGKILL信号强制终止进程。要获取进程ID,可以使用ps命令结合其他选项来查找。 - 一次IO操作的内核与用户态切换次数:
一次完整的IO操作通常涉及多次内核态与用户态之间的切换。以读取文件为例,大致过程如下:首先,用户态程序发起读文件请求,进入内核态;内核态处理请求,将数据从磁盘读入内核缓冲区;然后,内核将数据从内核缓冲区拷贝到用户态缓冲区,并切换回用户态;最后,用户态程序处理数据。在这个过程中,至少发生了两次用户态与内核态之间的切换。 - 参数:
由于您没有具体指出是哪个方面的参数,我无法给出具体的回答。参数通常用于配置和控制程序或系统的行为。在不同的上下文中,参数可能包括命令行参数、配置文件中的设置、系统属性、环境变量等。如果您能提供更具体的上下文或需求,我将能够给出更准确的回答。
session、cookie和cache的区别是什么
在Web应用程序中,session、cookie和cache是常用的存储数据的方式,它们在功能和用途上有所不同,其区别如下:
Session Session是服务器端存储数据的一种方式,它通过在服务器上存储一个唯一的标识符(Session ID)来跟踪用户的会话状态。
Session可以存储任何类型的数据,例如用户登录状态、购物车内容等。 Session的优点是数据的安全性高,不容易被恶意篡改和伪造,同时可以保存较大量的数据。缺点是需要在服务器上进行存储和管理,会占用服务器的资源,需要开发人员进行维护。
Cookie Cookie是一种在客户端存储数据的方式,它通过在用户的浏览器上存储一个小型的文本文件来保存数据。
Cookie可以存储一些临时的用户数据,例如用户的偏好设置、购物车内容等。 优点是存储数据的速度快,不需要在服务器上进行存储和管理,缺点是数据容易被篡改和伪造,同时每个浏览器对于Cookie的数量和大小都有限制。 Cache Cache是一种缓存数据的方式,它可以将频繁访问的数据存储在内存中,以提高访问速度。Cache可以存储一些不经常更新的数据,例如静态文件、数据库查询结果等。
Cache的优点是访问速度快,可以大大减少对数据库和其他数据源的访问次数,缺点是需要开发人员进行维护,以避免缓存数据的过期和失效。同时,缓存数据的大小也需要控制,避免占用过多的内存资源。 总的来说,Session、Cookie和Cache在功能和用途上有所不同,可以根据实际需要选择合适的存储方式。
session怎么提高效率?
Session持久化:将session信息存储在持久化存储中,如数据库、文件系统或NoSQL存储中,这样可以避免将所有session信息存储在内存中,从而减少内存的使用量。
Session复制:将session信息从一台服务器复制到另一台服务器上,这样可以实现负载均衡,并将会话信息在多个服务器之间共享。
Session失效策略:设置合理的session失效策略,例如根据用户活动时间、最大不活动时间等来决定session的失效时间,可以减少无用的session信息。
集群:使用集群环境来分散请求和负载,这样可以使应用程序在多个服务器上运行,从而提高应用程序的性能和可扩展性。
总之,为了提高会话管理的效率,需要使用合理的持久化和集群技术,并设置合理的会话失效策略,以避免会话信息的无限增长。
 微信
微信 支付宝
支付宝
